本文主要是介绍【踩坑】使用CenterNet训练自己的数据时的环境配置与踩坑,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
环境配置
系统:Ubuntu22.04
Python:3.8
CUDA:11.7
pytorch:2.2.1
因为种种原因没有使用原工程的老版本python和pytorch……但总之也跑通了,可喜可贺,可喜可贺。
- 新建conda环境:
conda create --name CenterNet python=3.8conda activate CenterNet
- 安装CUDA
使用nvidia-smi命令(前提是你安装了显卡驱动),可以看到显卡信息,其中右上角表示显卡最高支持的CUDA版本号,安装的CUDA版本不要超过这个版本。
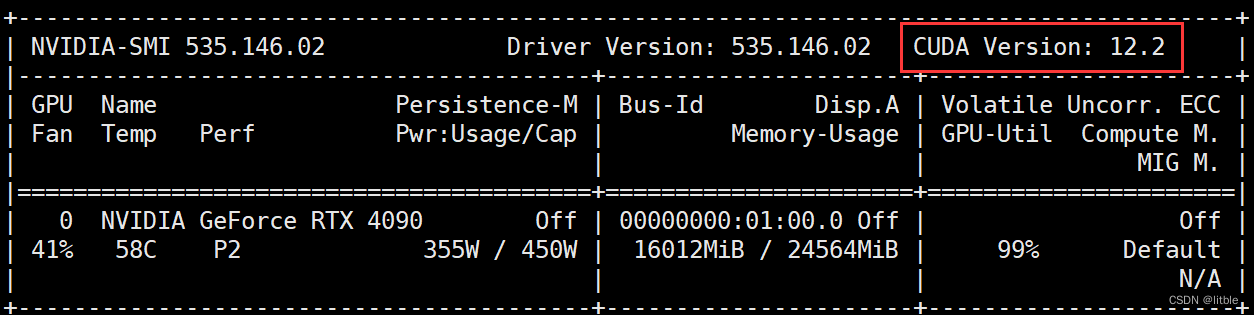
因为pytorch官网写了对应CUDA11.8和12.1两种版本的安装方式,所以图省事我的CUDA版本也直接安装11.8了。
首先找到你要安装的CUDA ToolKit版本:https://developer.nvidia.com/cuda-toolkit-archive
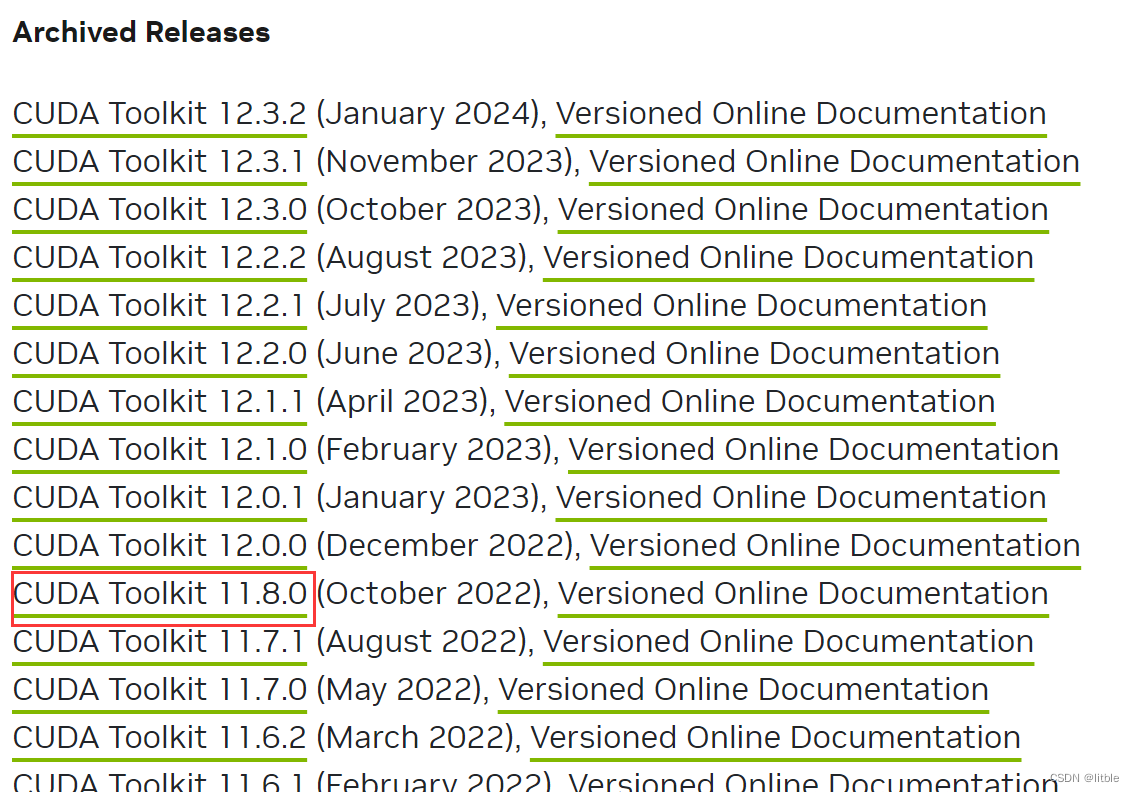
然后按你的机器配置一步一步选择好,运行给你的指令:
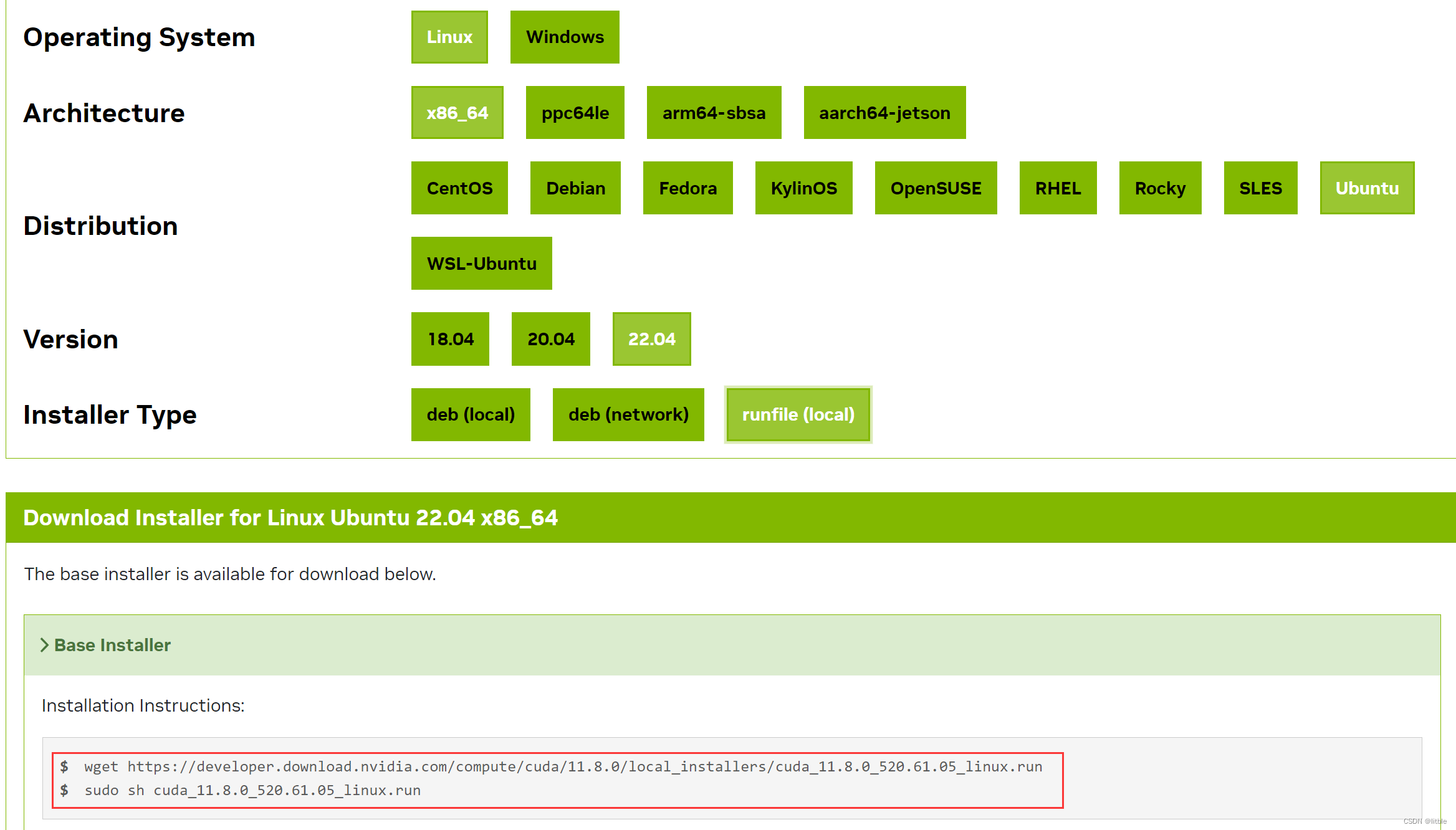
接下来的安装选项可以参考这篇博客,以下是一些细节:
如果你安装了其他版本的CUDA,会报一个询问是否continue的链接,continue即可。
注意在安装选项处去掉Driver、CUDA Demo Suite 11.8、CUDA Documentation 11.8,仅安装CUDA Toolkit 11.8。
使用如下命令设置CUDA环境变量:
export PATH=/usr/local/cuda-11.8/bin:$PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-11.8/lib64
最后使用nvcc --version命令可以验证自己安装的CUDA版本。
使用ls -l /usr/local | grep cuda可以查看安装的所有CUDA版本和对应的路径。
3. 安装pytorch
pytorch官网:https://pytorch.org/get-started/locally/
没啥好说的,输入指令安装即可。

4. 克隆CenterNet并安装依赖:
git clone https://github.com/xingyizhou/CenterNet
cd CenterNet
pip install -r requirements.txt
- 安装DCNv2
首先将CenterNet/src/lib/models/networks/DCNv2这个目录的老版本DCNv2删除,然后在原位置克隆DCNv2的一个fork:https://github.com/lbin/DCNv2
https://github.com/lbin/DCNv2.git
cd DCNv2
使用git branch -r指令可以查看所有分支信息,切换到最新的2.0.1分支:
git checkout pytorch_2.0.1
然后编译:
./make.sh
- 安装COCO API
git clone https://github.com/cocodataset/cocoapi.git
cd cocoapi/PythonAPI
make
python setup.py install --user
- 下载预训练模型
从作者提供的MODEL ZOO下载一个模型,放在/CenterNet/models/文件夹下。 - 运行demo
不出意外的话(虽然生活总是充满意外),做完以上这些配置后,应该就可以运行CenterNet的demo了!
python demo.py ctdet --demo 图片路径 --load_model pth模型路径
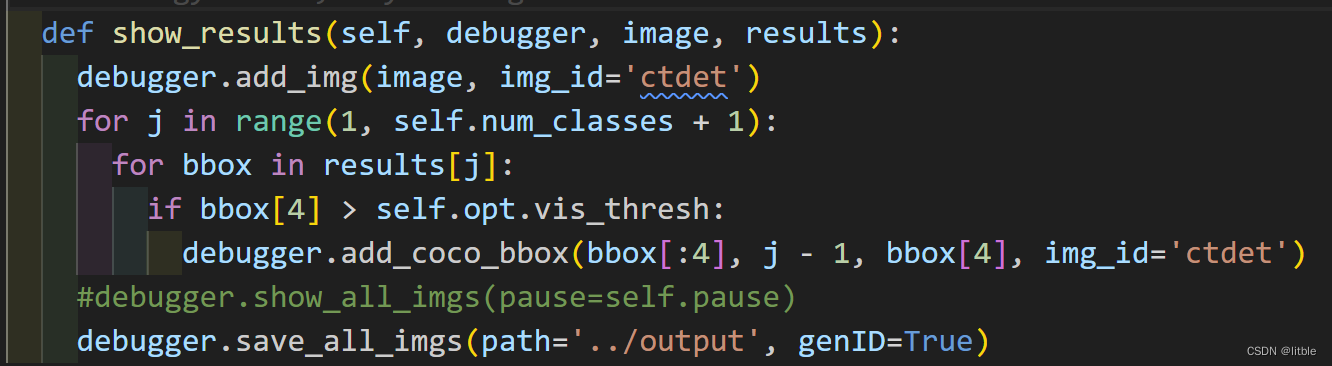
根据这篇博客,如果你想要保存结果而不是弹窗展示图片的话,将src/lib/detectors/cdet.py的最后一个函数做如下更改即可:
COCO格式数据集
参考原项目的README。
首先你的数据集要是COCO格式的,具体来说,你要在/CenterNet/data/文件夹下,建立一个这样的目录结构:
|mydata
|-- annotations
| |--train.json
| |--val.json
|-- images
images放你的所有图片(训练集和测试集可以不分开),而两个标注的json文件,最简格式如下:
{"categories": [ # 分类{"supercategory": # 父类,没有就填"None""id": # 类的标识id,建议令__background__为0"name": # 类名}],"images":[{"id": # 图片的唯一标识id"file_name": # 图片名称,不用带文件夹路径"width": # 宽度"height": # 高度}],"annotations":[{"id": #唯一标识id"segmentation": [] #图片分割,对于bbox类型的标注,直接[[left_x, top_y, left_x, bottom_y, right_x, bottom_y, right_x, top_y]]"area": # 标注的面积,对于bbox类型,直接长乘宽"bbox": [] # x, y, w, h"iscrowd": 0"ignore": 0"image_id": # 所在图片id"category_id": # 所属类别id}]
}
将数据处理好放好即可。
在CenterNet中应用自己的数据集
继续参考这篇博客,有很详细的代码修改说明,原项目README也有说明,主要是在src/lib/datasets/dataset下参考coco.py新增一个自己的dataloader类,然后将它引入src/lib/datasets/dataset_factory,并在/src/lib/opts.py中修改数据集默认值,添加类别标签即可。
运行训练:
python main.py ctdet --exp_id coco_dla --batch_size 32 --master_batch 1 --lr 1.25e-4 --gpus 0
模型会被保存在/exp/ctdet/coco_dla/文件夹下,其中测试集上效果最好的模型被命名为model_best.pth,而训出来的最后一个模型叫model_last.pth
运行测试:
python test.py --exp_id coco_dla --not_prefetch_test ctdet --load_model 模型路径
这篇关于【踩坑】使用CenterNet训练自己的数据时的环境配置与踩坑的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






