本文主要是介绍大数据篇 一篇讲明白 Hadoop 生态的三大部件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大数据Hadoop 生态的三大部件的目录
- 往期热门专栏回顾
- 前言
- 1、HDFS
- 2、Yarn
- 3、Hive
- 4、HBase
- 4.1.特点
- 4.2.存储
- 5、Spark及Spark Streaming
- 关于作者
往期热门专栏回顾
| 专栏 | 描述 |
|---|---|
| Java项目实战 | 介绍Java组件安装、使用;手写框架等 |
| Aws服务器实战 | Aws Linux服务器上操作nginx、git、JDK、Vue |
| Java微服务实战 | Java 微服务实战,Spring Cloud Netflix套件、Spring Cloud Alibaba套件、Seata、gateway、shadingjdbc等实战操作 |
| Java基础篇 | Java基础闲聊,已出HashMap、String、StringBuffer等源码分析,JVM分析,持续更新中 |
| Springboot篇 | 从创建Springboot项目,到加载数据库、静态资源、输出RestFul接口、跨越问题解决到统一返回、全局异常处理、Swagger文档 |
| Spring MVC篇 | 从创建Spring MVC项目,到加载数据库、静态资源、输出RestFul接口、跨越问题解决到统一返回 |
| 华为云服务器实战 | 华为云Linux服务器上操作nginx、git、JDK、Vue等,以及使用宝塔运维操作添加Html网页、部署Springboot项目/Vue项目等 |
| Java爬虫 | 通过Java+Selenium+GoogleWebDriver 模拟真人网页操作爬取花瓣网图片、bing搜索图片等 |
| Vue实战 | 讲解Vue3的安装、环境配置,基本语法、循环语句、生命周期、路由设置、组件、axios交互、Element-ui的使用等 |
| Spring | 讲解Spring(Bean)概念、IOC、AOP、集成jdbcTemplate/redis/事务等 |
前言
进入大数据阶段就意味着进入NoSQL阶段,更多的是面向OLAP场景,即数据仓库、BI应用等。
大数据技术的发展并不是偶然的,它的背后是对于成本的考量。集中式数据库或者基于MPP架构的分布数据库往往采用的都是性能稳定但价格较为昂贵的小型机、一体机或者PC服务器等,扩展性相对较差;而大数据计算框架可以基于价格低廉的普通的硬件服务器构建,并且理论上支持无限扩展以支撑应用服务。
在大数据领域中最有名的就是 Hadoop 生态,总体来看,它主要由三部分构成:底层文件存储系统 HDFS(Hadoop Distributed File System,Hadoop 分布式文件系统)、资源调度计算框架 Yarn(Yet Another Resource Negotiator,又一个资源协调者)以及基于 HDFS 与 Yarn的上层应用组件,例如 HBase、Hive 等。一个典型的基于 Hadoop 的应用如下图所示。
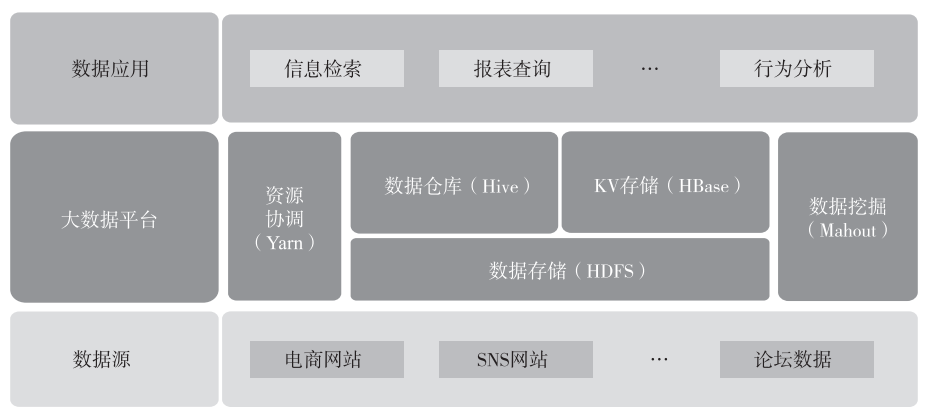
1、HDFS
HDFS 被设计成适合运行在通用硬件(Commodity Hardware)上的分布式文件系统。它和现有的分布式文件系统有很多共同点,例如典型的 Master-Slave 架构(这里不准备展开介绍),也有不同点,HDFS 是一个具有高度容错性的系统,适合部署在廉价的机器上。关于HDFS 这里主要想说两点,默认副本数的设置以及机架感知(Rack Awareness)。
HDFS 默认副本数是 3,这是因为 Hadoop 有着高度的容错性,从数据冗余以及分布的角度来看,需要在同一机房不同机柜以及跨数据中心进行数据存储以保证数据最大可用。因此,为了达到上述目的,数据块需要至少存放在同一机房的不同机架(2 份)以及跨数据中心的某一机架(1 份)中,共 3 份数据。
机架感知的目的是在计算中尽量让不同节点之间的通信能够发生在同一个机架之 内,而不是跨机架,进而减少分布式计算中数据在不同的网络之间的传输,减少网络带 宽资源的消耗。例如当集群发生数据读取的时候,客户端按照由近到远的优先次序决定 哪个数据节点向客户端发送数据,因为在分布式框架中,网络 I/O 已经成为主要的性能瓶颈。
只有深刻理解了这两点,才能理解为什么 Hadoop 有着高度的容错性。高度容错性是Hadoop 可以在通用硬件上运行的基础。
2、Yarn
Yarn 是继 Common、HDFS、MapReduce 之 后 Hadoop 的又一个子项目, 它是在MapReduceV2 中提出的。
在 Hadoop1.0 中,JobTracker 由资源管理器(由 TaskScheduler 模块实现)和作业控制 (由 JobTracker 中多个模块共同实现)两部分组成。
在 Hadoop1.0 中,JobTracker 没有将资源管理相关功能与应用程序相关功能拆分开,逐 渐成为集群的瓶颈,进而导致集群出现可扩展性变差、资源利用率下降以及多框架支持不 足等多方面的问题。
在 MapReduceV2 中,Yarn 负责管理 MapReduce 中的资源(内存、CPU 等)并且将其 打包成 Container。这样可以使 MapReduce 专注于它擅长的数据处理任务,而不需要考虑资源调度。这种松耦合的架构方式实现了 Hadoop 整体框架的灵活性。
3、Hive
Hive 是基于Hadoop 的数据仓库基础构架,它利用简单的 SQL 语句(简称 HQL)来查询、分析存储在 HDFS 中的数据,并把 SQL 语句转换成 MapReduce 程序来进行数据的处理。Hive与传统的关系型数据库的主要区别体现在以下几点。
-
1)存储的位置, Hive 的数据存储在 HDFS 或者 HBase 中,而后者的数据一般存储在裸设备或者本地的文件系统中,由于 Hive 是基于 HDFS 构建的,那么依赖 HDFS 的容错特性,Hive 中的数据表天然具有冗余的特点。
-
2)数据库更新, Hive 是不支持更新的,一般是一次写入多次读写(这部分从 Hive 0.14之后开始支持事务操作,但是约束比较多),但是由于 Hive 是基于 HDFS 作为底层存储的, 而 HDFS 的读写不支持事务特性,因此 Hive 的事务支持必然需要拆分数据文件以及日志文 件才能支持事务的特性。
-
3)执行 SQL 的延迟,Hive 的延迟相对较高,因为每次执行都需要将 SQL 语句解析成MapReduce 程序。
-
4)数据的规模上,Hive 一般是 TB 级别,而后者规模相对较小。
-
5)可扩展性上,Hive 支持 UDF、UDAF、UDTF,后者相对来说可扩展性较差。
4、HBase
HBase(Hadoop Database)是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统。它底层的文件系统使用 HDFS, 使用ZooKeeper 来管理集群的 HMaster 和各RegionServer 之间的通信,监控各RegionServer 的状态,存储各 Region 的入口地址等。
4.1.特点
HBase 是 Key-Value 形式的数据库(类比 Java 中的 Map)。既然是数据库那肯定就有 表,HBase 中的表大概有以下几个特点。
1)大:一个表可以有上亿行,上百万列(列多时,插入变慢)。
2)面向列:面向列(族)的存储和权限控制,列(族)独立检索。
3)稀疏:对于空(null)的列,并不占用存储空间,因此,表可以设计得非常稀疏。
4)每个单元格中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入 时的时间戳。
5)HBase 中的数据都是字节,没有类型定义具体的数据对象(因为系统需要适应不同 类型的数据格式和数据源,不能预先严格定义模式)。
这里需要注意的是,HBase 也是基于 HDFS,所以也具有默认 3 个副本、数据冗余的特 点。此外 HBase 也是利用 WAL 的特点来保证数据读写的一致性。
4.2.存储
HBase 采用列式存储方式进行数据的存储。传统的关系型数据库主要是采用行式存储 的方式进行数据的存储,数据读取的特点是按照行的粒度从磁盘上读取数据记录,然后根 据实际需要的字段数据进行处理,如果表的字段数量较多,但是需要处理的字段较少(特 别是聚合场景),由于行式存储的底层原理,仍然需要以行(全字段)的方式进行数据的查 询。在这个过程中,应用程序所产生的磁盘 I/O、内存要求以及网络 I/O 等都会造成一定的 浪费;而列式存储的数据读取方式主要是按照列的粒度进行数据的读取,这种按需读取的 方式减少了应用程序在数据查询时所产生的磁盘 I/O、内存要求以及网络 I/O。
此外,由于相同类型的数据被统一存储,因此在数据压缩的过程中压缩算法的选用以 及效率将会进一步加强,这也进一步降低了分布式计算中对于资源的要求。
列式存储的方式更适合 OLAP 型的应用场景,因为这类场景具有数据量较大以及查询字段较少(往往都是聚合类函数)的特点。例如最近比较火的 ClickHouse 也是使用列式存储的方式进行数据的存储。
5、Spark及Spark Streaming
Spark 由 Twitter 公司开发并开源,解决了海量数据流式分析的问题。Spark 首先将数据 导入 Spark 集群,然后通过基于内存的管理方式对数据进行快速扫描,通过迭代算法实现 全局 I/O 操作的最小化,达到提升整体处理性能的目的。这与 Hadoop 从“计算”找“数据” 的实现思路是类似的,通常适用于一次写入多次查询分析的场景。
Spark Streaming 是基于 Spark 的一个流式计算框架,它针对实时数据进行处理和控制, 并可以将计算之后的结果写入 HDFS。它与当下比较火的实时计算框架 Flink 类似,但是二者在本质上是有区别的,因为 Spark Streaming 是基于微批量(Micro-Batch)的方式进行数据处理,而非一行一行地进行数据处理。
关于作者
李杨,资深数据架构师,在数据相关领域有10年以上工作经验。头部保险资管公司科技平台交易系统团队开发组负责人,负责多个应用以及数据平台的建设、优化以及迁移工作。曾担任某数据公司技术合伙人,负责多个金融机构的数据仓库或数据平台相关的工作。《企业级数据架构:核心要素、架构模型、数据管理与平台搭建》作者。
本文摘编于《企业级数据架构:核心要素、架构模型、数据管理与平台搭建》作者。(书号:9787111746829),经出版方授权发布,转载请标明文章出处。
推荐理由:
一部从企业架构视角系统讲解企业级数据架构的著作,系统梳理和阐述了企业架构的基础知识,以及数据架构的组成要素、架构模型、数据治理和数据资产管理的理论知识。

资料获取,更多粉丝福利,关注下方公众号获取

这篇关于大数据篇 一篇讲明白 Hadoop 生态的三大部件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




