本文主要是介绍xpath helper插件:网页爬虫分析工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
XPath helper插件概述
xPath Helper插件是什么?
xPath helper是一款Chrome浏览器的开发者插件,安装了xPath helper后就能轻松获取HTML元素的xPath,程序员就再也不需要通过搜索html源代码,定位一些id去找到对应的位置去解析网页了。
xPath helper是一款Chrome浏览器的开发者插件,安装了xPath helper后就能轻松获取HTML元素的xPath,程序员就再也不需要通过搜索html源代码,定位一些id去找到对应的位置去解析网页了。
XPath helper插件功能介绍
XPath Helper插件有什么用?google插件XPath Helper 可以支持在网页点击元素生成xpath, 整个抓取使用了xpath、正则表达式、消息中间件、多线程调度框架(参考)。xpath 是一种结构化网页元素选择器,支持列表和单节点数据获取,他的好处可以支持规整网页数据抓取。
如果我们要查找某一个、或者某一块元素的xpath路径,可以按住shift,并移动到这一块中,上面的框就会显示这个元素的xpath路径,右边则会显示解析出的文本内容,并且我们可以自己改动xpath路径,程序也会自动的显示对应的位置,可以很方便的帮助我们判断我们的xpath语句是否书写正确。
XPath helper插件下载安装
XPath helper插件哪里可以下载?你可以从chrome应用商店里找到chrome爬虫插件 ,如果你的chrome应用商店无法打开,你可以在本站的下方找到 chrome爬虫插件 下载地址。XPath helper 插件怎么安装?
1. 如果你能够打开chrome应用商店,并且可以找到 chrome爬虫插件 ,那么直接点击“添加至chrome”,如下图所示:

2.如果你的chrome应用商店无法打开,你从本站或者其他途径获得了 chrome爬虫插件 ,那么就选择离线安装该插件。由于 chrome爬虫插件 同其他chrome插件一样都是CRX格式的,所以具体的安装方法请参照:怎么在谷歌浏览器中安装.crx扩展名的离线Chrome插件? 如果CRX格式插件不能离线安装怎么办?
Xpath helper插件使用说明
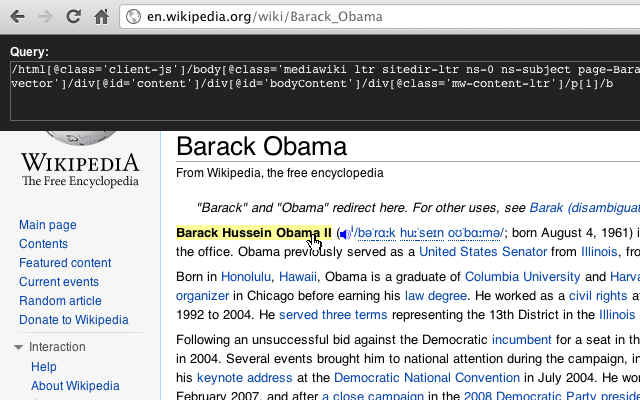
1.在chrome浏览器安装好xpath helper插件后,打开某个网页(以搜狐为例)拷贝目标页面元素的XPATH,如下图所示: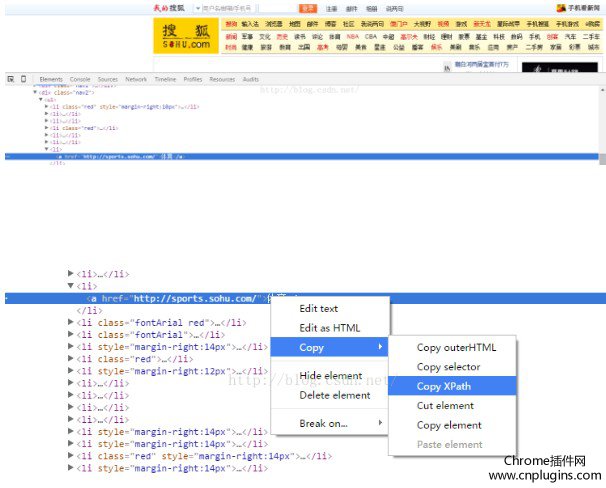
2.点击 Ctrl + Shift + X 激活 XPath Helper 的控制台,然后您可以在 Query 文本框中输入相应 XPath 进行调试了,提取的结果将被显示在旁边的 Result 文本框中,如下图所示:
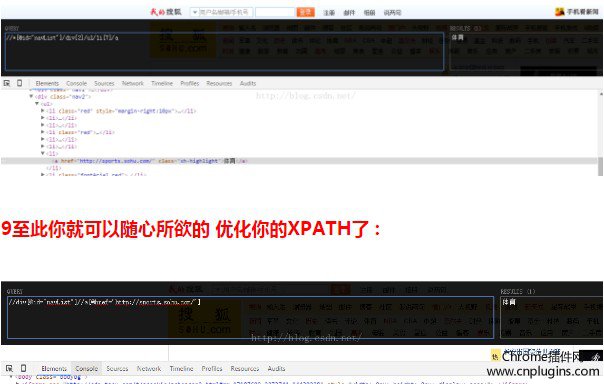
1。打开一个新的标签,并导航到你最喜欢的网页。
2。按Ctrl-Shift键-X以打开XPath辅助控制台。
3。按住Shift键鼠标在页面上的元素。查询框会不断更新,以显示鼠标指针下面的元素充分XPath查询。结果框其右侧将显示评价结果的查询。
4。如果需要的话,可以直接在控制台编辑XPath查询。在结果框中将立即反映任何变化。
5。再次按Ctrl-Shift键-X关闭控制台
XPath helper插件注意事项
虽然 XPath Helper 插件使用非常方便,但它也不是万能的,有两个问题:
1.XPath Helper 自动提取的 XPath 都是从根路径开始的,这几乎必然导致 XPath 过长,不利于维护;
2.当提取循环的列表数据时,XPath Helper 是使用的下标来分别提取的列表中的每一条数据,这样并不适合程序批量处理,还是需要人为修改一些类似于*标记等。
不过,合理的使用Xpath,还是能帮我们省下很多时间的!
转自:http://www.cnplugins.com/devtool/xpath-helper/
这篇关于xpath helper插件:网页爬虫分析工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





