本文主要是介绍pyhive入门介绍和实例分析(探索票价与景点评分之间是否存在相关性),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
PyHive 是一组 Python DB-API 和 SQLAlchemy 接口,可用于 Presto 和 Hive。它为 Python 提供了一个与 Presto 和 Hive 进行交互的平台,使得数据分析师和工程师可以更方便地进行数据处理和分析。
以下是使用 PyHive 进行数据分析时需要注意的几点:
-
安装和配置: 在开始之前,确保已经安装了以下软件:
- Pip
- Python 建议使用anaconda方便管理
- JDK 注意兼容性
- Hive 或 Presto
- 版本兼容性: 确保 PyHive 版本与 Hive 或 Presto 版本兼容。不同版本之间可能会有一些差异,需注意兼容性。
安装 PyHive 可以使用以下命令:
pip install pyhive [hive]如果你想安装 Presto 驱动器,请使用以下命令:
pip install pyhive [presto] -
连接 Hive 数据库: 使用 PyHive 连接 Hive 数据库非常简单。你需要传递正确的连接参数,例如:
from pyhive import hive connection = hive.Connection(host='localhost', port=10000, database='mydatabase') -
执行查询: 使用 PyHive 执行查询也很容易,只需使用游标对象来执行查询:
cursor = connection.cursor() cursor.execute('SELECT * FROM mytable') result = cursor.fetchall() for row in result:print(row) -
使用 Pandas 进行数据分析: 如果你更喜欢使用 Pandas 进行数据分析,可以将查询结果转换为 Pandas DataFrame:
import pandas as pd df = pd.read_sql('SELECT * FROM mytable', connection) print(df)
代码示例
from pyhive import hive# 设置连接参数
host = 'your_host'
port = 10000
username = 'your_username'
password = 'your_password'
database = 'your_database'# 建立连接
conn = hive.Connection(host=host, port=port, username=username, password=password, database=database)# 创建 Cursor 对象
cursor = conn.cursor()# 执行查询
query = "SELECT * FROM your_table LIMIT 10"
cursor.execute(query)# 获取查询结果
results = cursor.fetchall()# 处理结果
for row in results:print(row)# 关闭连接
cursor.close()
conn.close()
分析实例
现有两个hive表,表结构大约为:

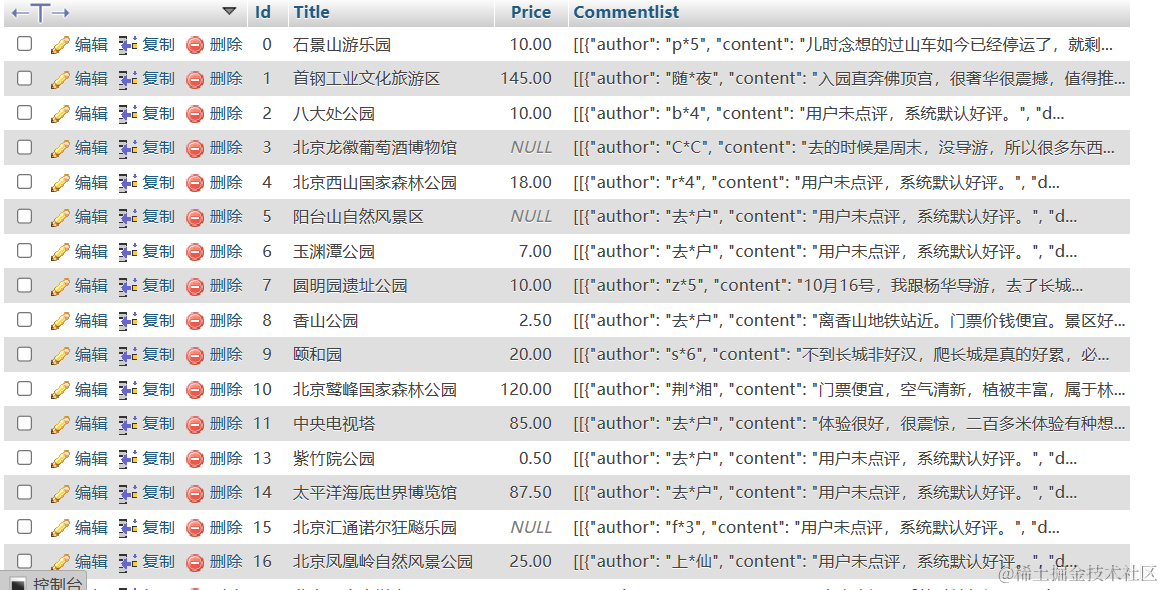
需要实现需求:
票价与评分的关系: 探索票价与景点评分之间是否存在相关性。分析不同票价档次下景点的评分分布情况,以确定价格对游客评价的影响程度。
首先 找到所有非空的景区,
在xiecheng表中找到所有averagescore不为null的数据,在qvna表中找到所有price不为null的数据。
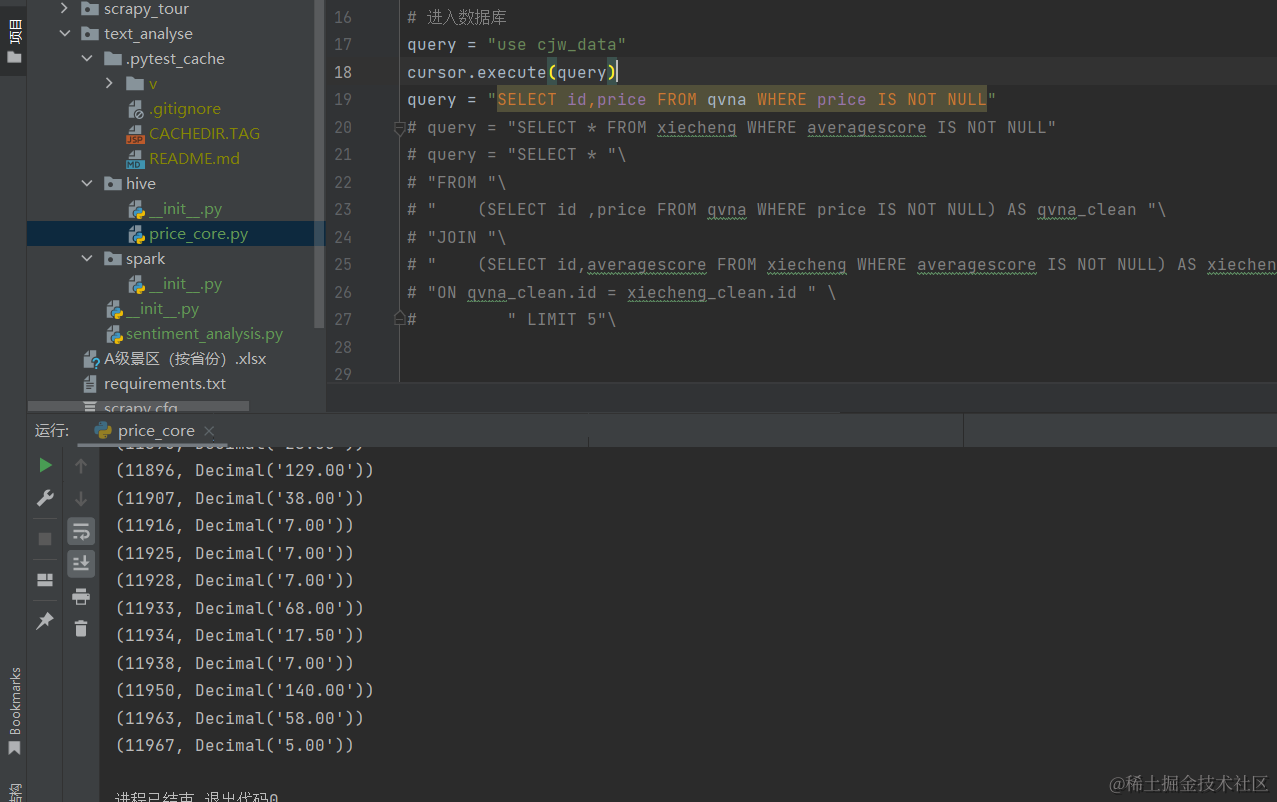
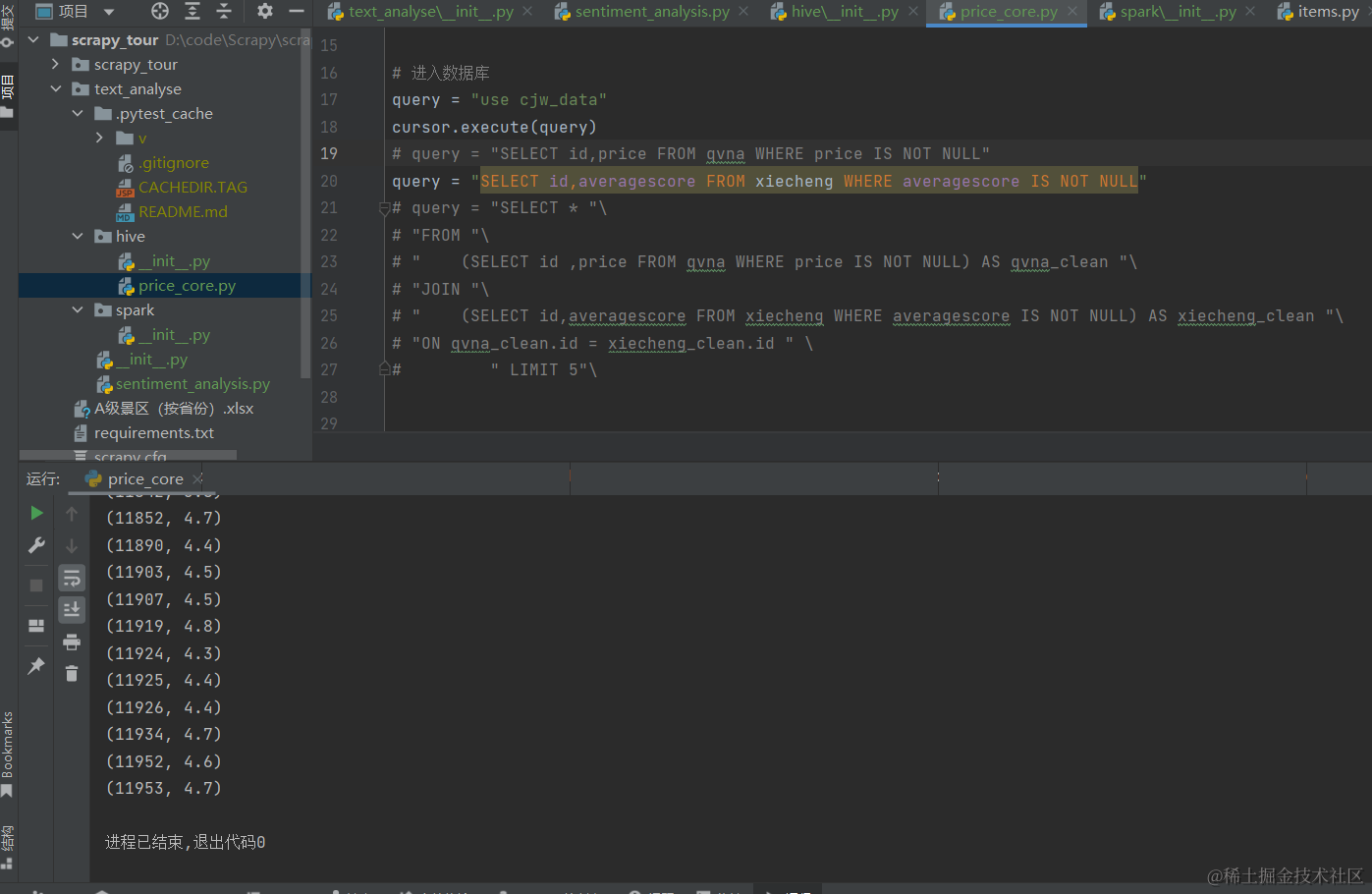
联合查询:
将两表所需数据放在一起。
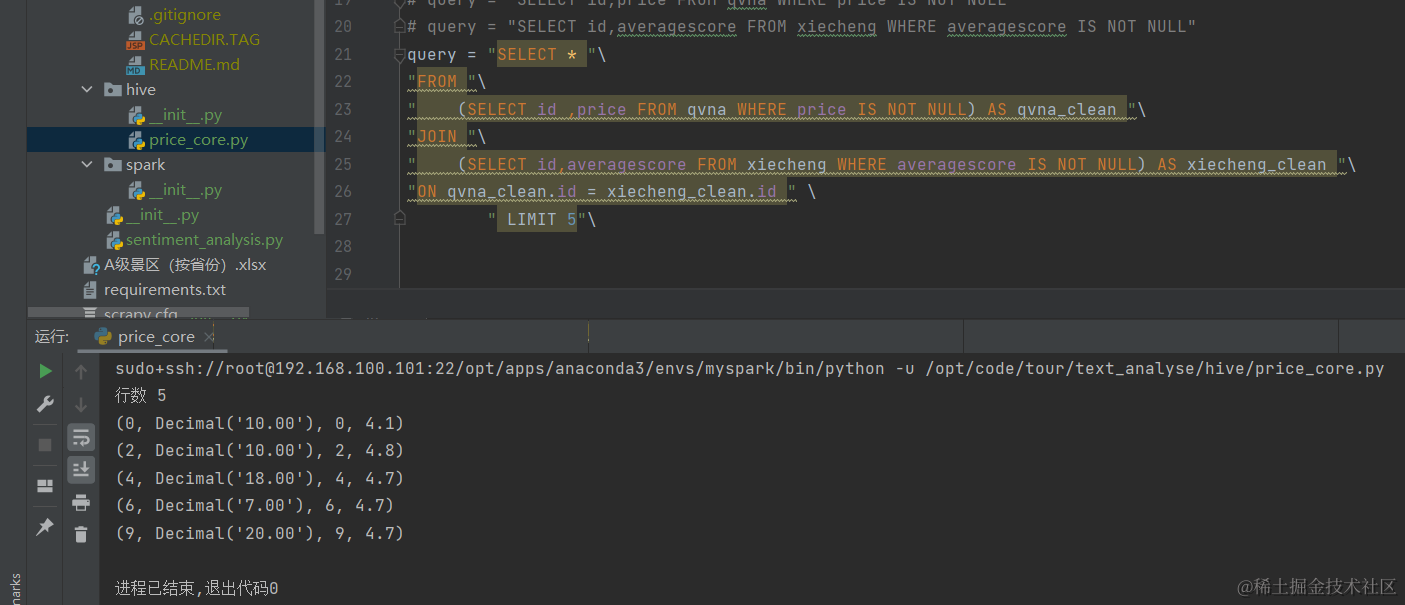
将查询到的数据放到新的表中以方便后续查找和使用:
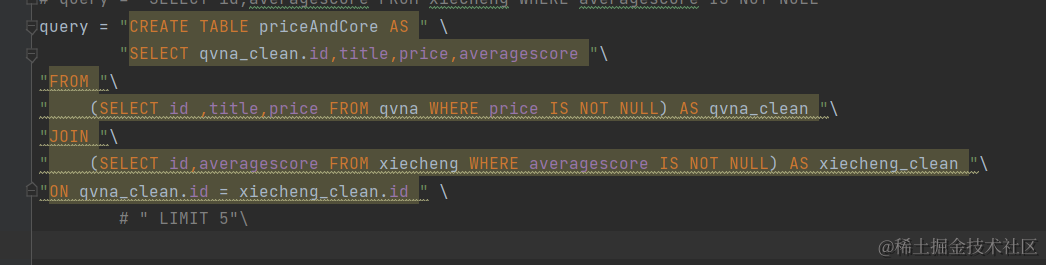
分类查找并计算平均值:
代码:
# Author: 冷月半明
# Date: 2023/12/6
# Description: This script does XYZ.from pyhive import hivedef creatConnection():conn = hive.Connection(host='******', port=10000, username='root')return conn# 连接到 Hive
conn = creatConnection()
cursor = conn.cursor()# 进入数据库
query = "use cjw_data"
cursor.execute(query)
# 查询去哪价格非空的景区
# query = "SELECT id,price FROM qvna WHERE price IS NOT NULL"
# 查询携程平均分非空的景区
# query = "SELECT id,averagescore FROM xiecheng WHERE averagescore IS NOT NULL"
# 将查询到的id,title,价格,平均分等数据存储到新的表中
# query = "CREATE TABLE priceAndCore AS " \
# "SELECT qvna_clean.id,title,price,averagescore "\
# "FROM "\
# " (SELECT id ,title,price FROM qvna WHERE price IS NOT NULL) AS qvna_clean "\
# "JOIN "\
# " (SELECT id,averagescore FROM xiecheng WHERE averagescore IS NOT NULL) AS xiecheng_clean "\
# "ON qvna_clean.id = xiecheng_clean.id " \
# # " LIMIT 5"\# 计算各个区间票价景点之间的平均评价分
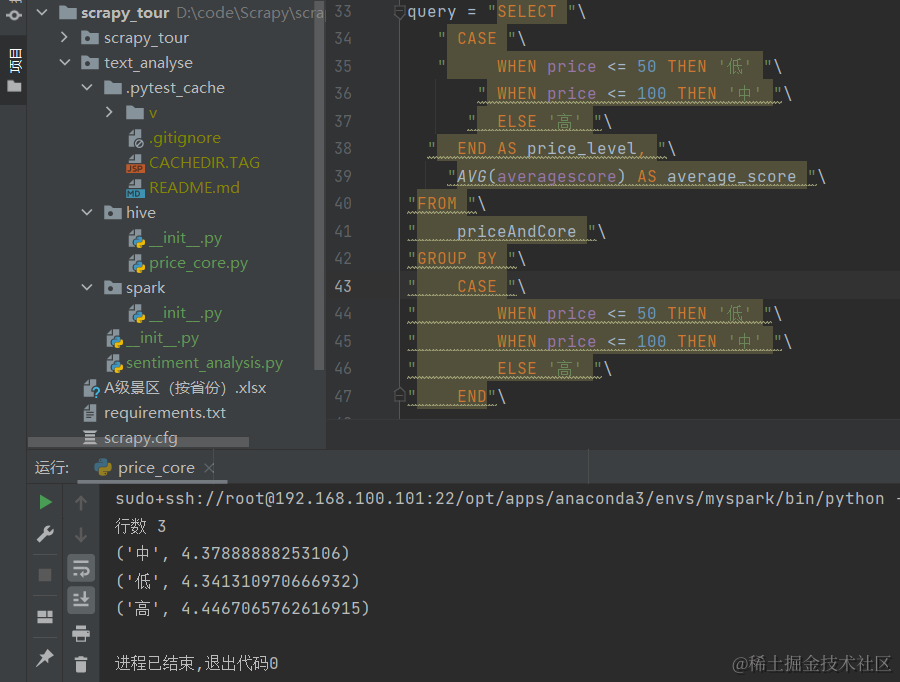
query = "SELECT "\" CASE "\" WHEN price <= 50 THEN '低' "\" WHEN price <= 100 THEN '中' "\" ELSE '高' "\" END AS price_level, "\"AVG(averagescore) AS average_score "\
"FROM "\
" priceAndCore "\
"GROUP BY "\
" CASE "\
" WHEN price <= 50 THEN '低' "\
" WHEN price <= 100 THEN '中' "\
" ELSE '高' "\
" END"\# " LIMIT 5"\cursor.execute(query)
tables = cursor.fetchall()
print('行数',len(tables))# 打印数据库列表
for tables in tables:print(tables)# 关闭连接
cursor.close()
conn.close()这篇关于pyhive入门介绍和实例分析(探索票价与景点评分之间是否存在相关性)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







