本文主要是介绍某对象存储元数据集群改造流水账,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
软件产品:某厂商提供的不便具名的对象存储产品,核心底层技术源自HDFS和Amazon S3,元数据集群采用了基于MongoDB的NOSQL数据库产品和MySQL数据库产品相结合。
该产品的元数据逻辑示意图如下:
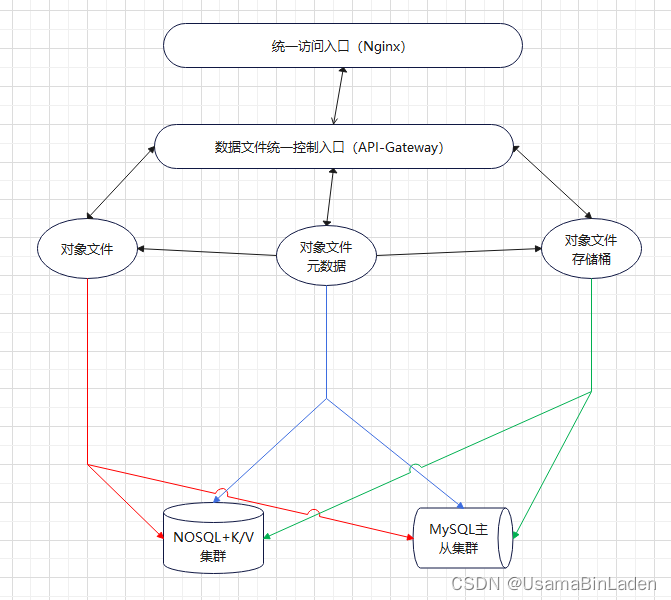
业务集群现状:当前第3期建设的元数据集群中存在约50亿条对象文件记录。当前共3期建成规模,元数据记录总量约400亿条。当前集群中对象文件的读写存在明显时延,读写性能已不满足业务应用方使用需求。
业务集群现状分析:
甲:当前业务集群主要是在跑大规模语言模型训练,产生的对象文件会冷档到对象存储集群,单个文件命名而成的元数据块未超过20B;
乙:当前对象存储系统所构成软件版本已不再维护,MySQL版本较低,数据库中单表过于庞大、且无法拆分;
丙:造成当前集群中对象文件读写延时的瓶颈在于MySQL数据库中单表过于庞大,此外NOSQL数据库的数据磁盘已利用了70%、NOSQL数据库消耗了其Host-OS内存的65%。
现场勘验结论:
简单地对当前集群进行元数据集群扩容无法缓解对象文件读写延时问题,需要对对象文件列表操作相关的MySQL数据库表做改造才能从根本上解决业务应用方反映的痛点。
对象存储软件存储系统组件分析:
NOSQL数据库主要以热存储的方式存储对象文件的名称、创建时间、存储桶位置、全局存储索引等索引信息,并以 K/V 的形式对外提供查询服务;
MySQL数据库主要记录存储桶内的对象文件索引信息,供文件列表类的操作使用。
换而言之,NOSQL存储了全局元数据信息、MySQL记录存储桶内的对象文件元数据信息。这种情况下,可以认为是NOSQL向MySQL同步了一部分元数据、对MySQL列表操作后的结果会来到NOSQL查找对象文件的具体存放位置。
有了这个认识,那么元数据集群的改造也就定向了:提升MySQL数据库表的链接查询速度和效率,增加NOSQL集群规模。因为提升MySQL数据库表的链接查询速率可以在前端页面快速返回被列表操作的对象文件集合;增加NOSQL集群规模可以缩小各节点上的 K/V记录的规模、进而缩短对象文件被查询的时间。
至此这个问题就变成了如何优化MySQL的数据库表结构、如何优化MySQL的数据库表链接查询速率的问题了。
在这个方向上大体有两种解决办法:
一是重新设计MySQL集群中的库表结构、并将对象文件的读写转移到新的MySQL集群上。这个操作需要分两个大的步骤来完成:第一步先完成新的兼容性库表的设计并搭建好新的MySQL集群,保证新写入的数据指向新建的MySQL集群、已有的数据继续从原来的MySQL集群上读写;第二步是构建一个新的中转数据池,把原有的MySQL集群中的数据同步到中转池中、并从中转池中清洗后写入到新建的MySQL集群,等到原有的数据和元数据同步完毕,再选择一个合适的操作窗口停止业务应用的读写、把尾数数据写入到新建的MySQL集群中、并更改数据访问路由到新建的MySQL集群上。
这个办法保守,能最大限度地保全原有数据的完整性,场内有过低版本MySQL向高版本MySQL迁移的案例,上线排期会比较短;但是操作周期长、操作过程频繁且复杂,既考验DBA对业务数据结构的规划设计能力、又考虑业务应用方对业务中断的容忍程度,很可能会遭遇业务应用方的否决。
二是采用路由网关的方式直接指向NOSQL数据库中的存储桶数据表。具体操作为新构建一个数据仓储池,把NOSQL中的数据记录持续被分到仓储池,在NOSQL节点上部署一个针对表的搜索引擎实例(如Elasticsearch、Lucene、Solr、ClickHouse等),在数据文件统一入口后添加一个路由网关(如Netflix Zuul),通过配置路由网关让文件列表操作直达存储桶所在的NOSQL节点,由搜索引擎对表文件进行查询并返回对象文件所在的物理位置。
这个办法比较激进,场内没有类似或相关的案例研究,理论上不会产生已有数据的丢失。优点是彻底解放了文件列表操作的数量限制(MySQL低版本上的表容纳量约为10亿条),只要路由网关和搜索引擎规模足够大,对象文件的列表操作几乎不会出现较大的延时。在做好路由流量切分的情况下,可以实现业务应用方的无感知操作。缺点是对原有集群改动幅度比较大,需要产品研发配合做针对性的代码修改,上线排期比较长。
当前这两种方案都做过了小规模的POC验证,但出于谨慎和客户方催期考虑,决定优先使用第一种方案对现有业务集群进行改造。
(等到该项目脱密或者我本人离岗脱密后,再行讨论这两种改造方案的细节内容。)
这篇关于某对象存储元数据集群改造流水账的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





