本文主要是介绍Jmeter使用BeanShell保存数据到文件,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、目的
在使用jmeter压测时,业务上下连贯,需要对一些编号进行关联操作。这里使用‘JSON提取器’将值提取出来,后面请求可以直接使用。其它业务想要使用就只能把值保存到文件,再使用文件做参数化了。
2、JSON提取器 提取请求值
提取方式多种多样,正则、json、边界值等等。根据实际请求选择
-
在请求右键-添加-后置处理器-JSON提取器
Main sample and sub-samples:匹配范围包括当前父取样器并覆盖子取样器Main sample only:匹配范围是当前父取样器(最常用)Sub-samples only:仅匹配子取样器JMeter Variable Name to use:支持对 Jemter变量值进行匹配Names of created variables:变量名JSON Path expressions:需要提取的JSON值对应位置Match No.:0 代表随机取值,n取第几个匹配值,-1匹配所有Compute concatenation var:如果找到许多结果,则插件将使用’,‘分隔符将它们连接起来,并将其存储在名为 _ALL的var中Default Value:如果参数没有取得到值,默认给一个值
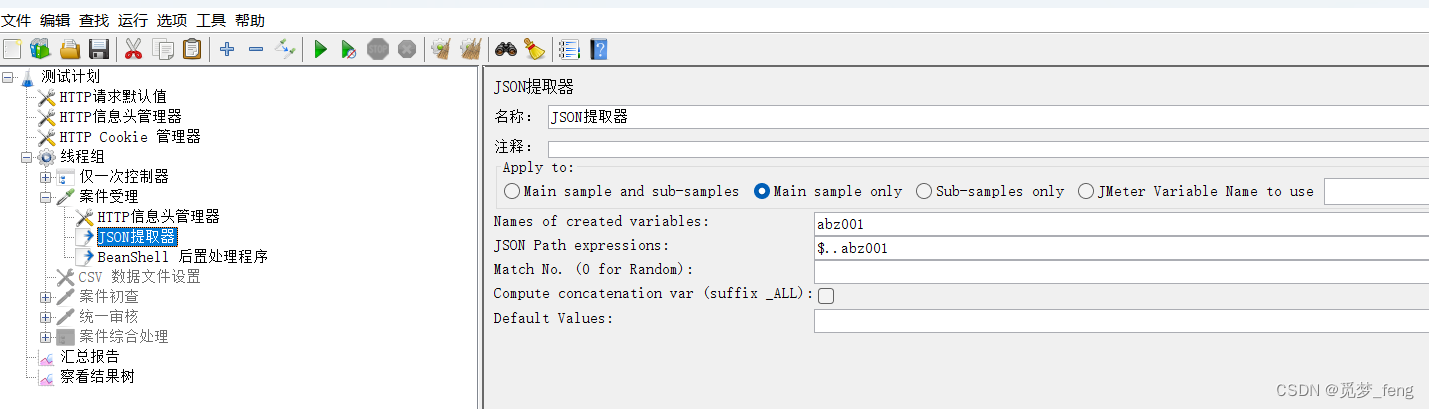 这里提取请求的abz001,写路径与变量名称。使用${abz001}调用。
这里提取请求的abz001,写路径与变量名称。使用${abz001}调用。
3、BeanShell 保存数据
- 在请求右键-添加-后置处理器-BeanShell 后置处理程序
编写保存代码,将${abz001}保存到abz001.csv
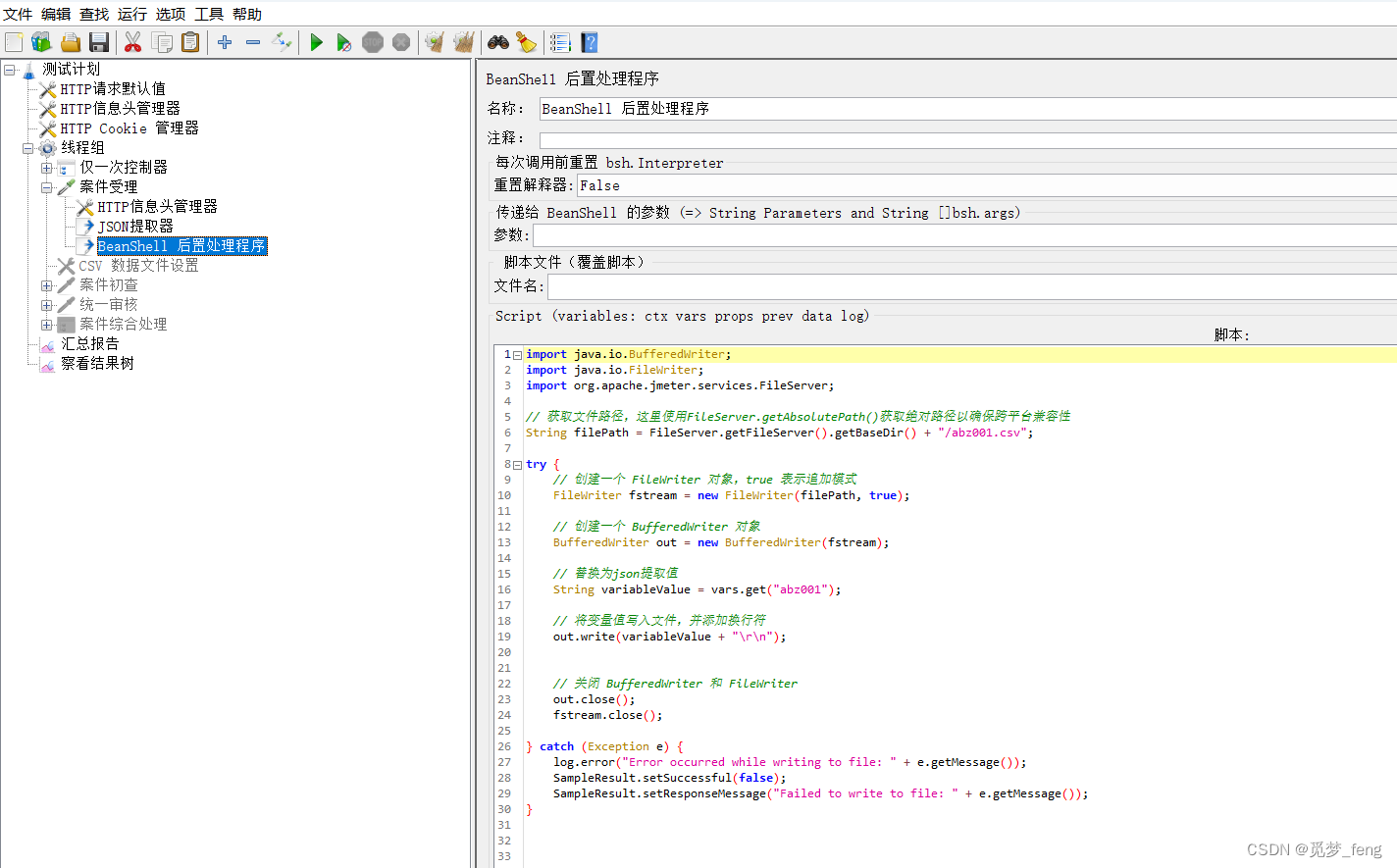
import java.io.BufferedWriter;
import java.io.FileWriter;
import org.apache.jmeter.services.FileServer;// 获取文件路径,这里使用FileServer.getAbsolutePath()获取绝对路径以确保跨平台兼容性
String filePath = FileServer.getFileServer().getBaseDir() + "/abz001.csv";try {// 创建一个 FileWriter 对象,true 表示追加模式FileWriter fstream = new FileWriter(filePath, true);// 创建一个 BufferedWriter 对象BufferedWriter out = new BufferedWriter(fstream);// 替换为json提取值String variableValue = vars.get("abz001");// 将变量值写入文件,并添加换行符out.write(variableValue + "\r\n");// 关闭 BufferedWriter 和 FileWriterout.close();fstream.close();} catch (Exception e) {log.error("Error occurred while writing to file: " + e.getMessage());SampleResult.setSuccessful(false);SampleResult.setResponseMessage("Failed to write to file: " + e.getMessage());
}保存文件实例:
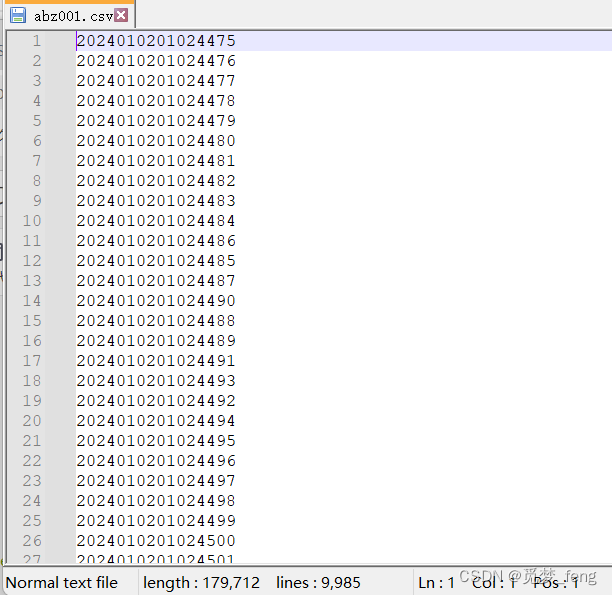
4、csv文件使用示例
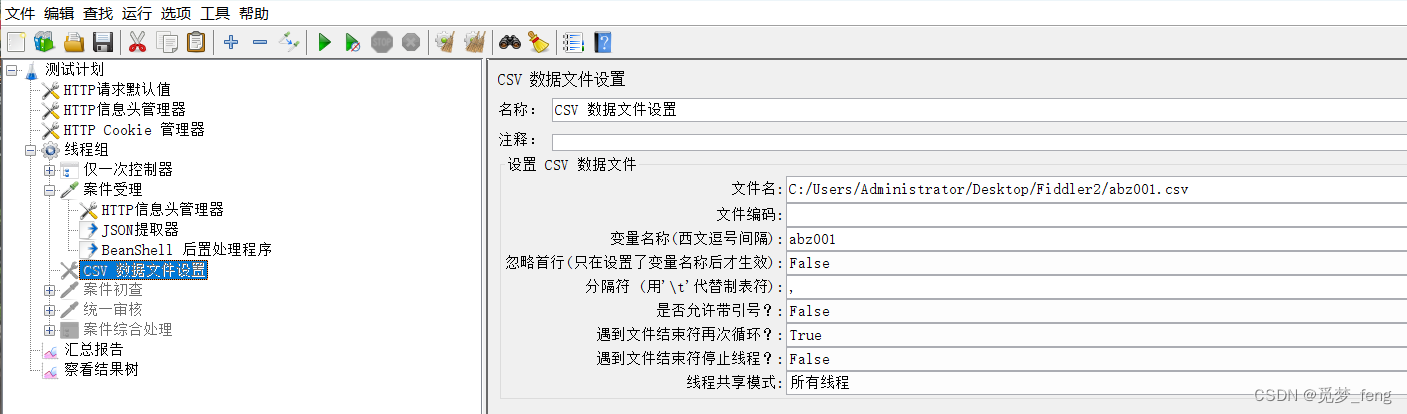
- 在请求右键-添加-配置元件-CSV 数据文件设置
读取文件名:abz001.csv,变量名称abz001,则使用${abz001}调用。
这篇关于Jmeter使用BeanShell保存数据到文件的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






