本文主要是介绍PSO-CNN-BiLSTM多输入回归预测|粒子群优化算法-卷积-双向长短期神经网络回归预测|Matlab,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、程序及算法内容介绍:
基本内容:
亮点与优势:
二、实际运行效果:
三、算法介绍:
四、完整程序下载:
一、程序及算法内容介绍:
基本内容:
-
本代码基于Matlab平台编译,将PSO(粒子群算法)与CNN-BiLSTM(卷积-双向长短期记忆神经网络)结合,进行多输入数据回归预测
-
输入训练的数据包含7个特征,1个响应值,即通过7个输入值预测1个输出值(多变量回归预测,特征个数可自行指定)
-
归一化训练数据,提升网络泛化性
-
通过PSO算法优化CNN-BiLSTM网络的学习率、卷积核个数、神经元个数参数,记录下最优的网络参数
-
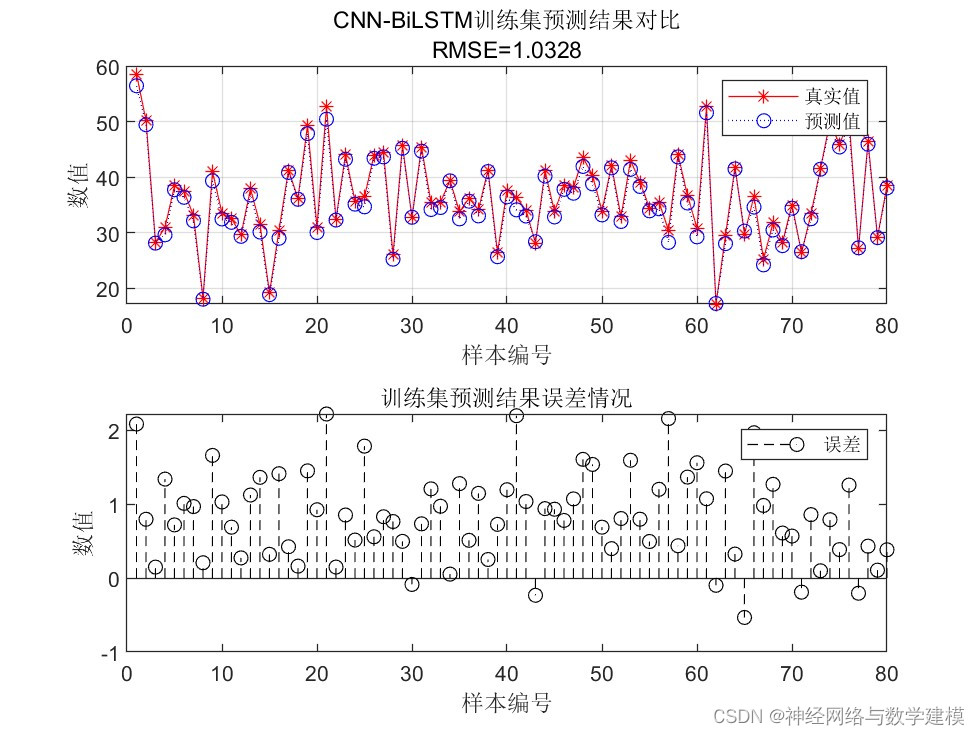
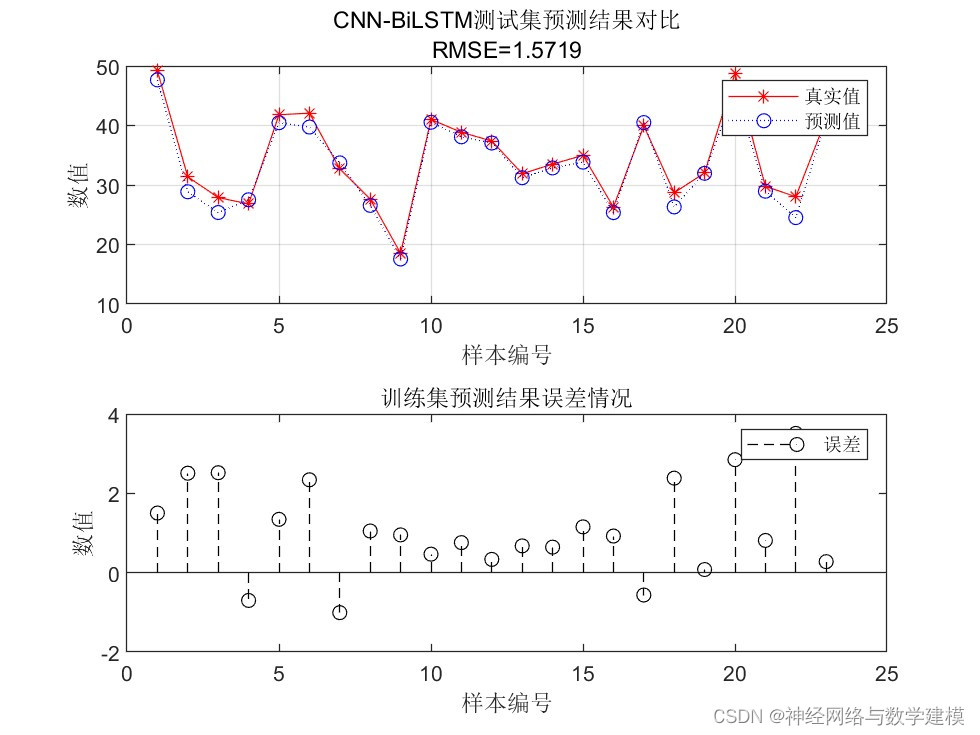
训练LSTM网络进行回归预测,实现更加精准的预测
-
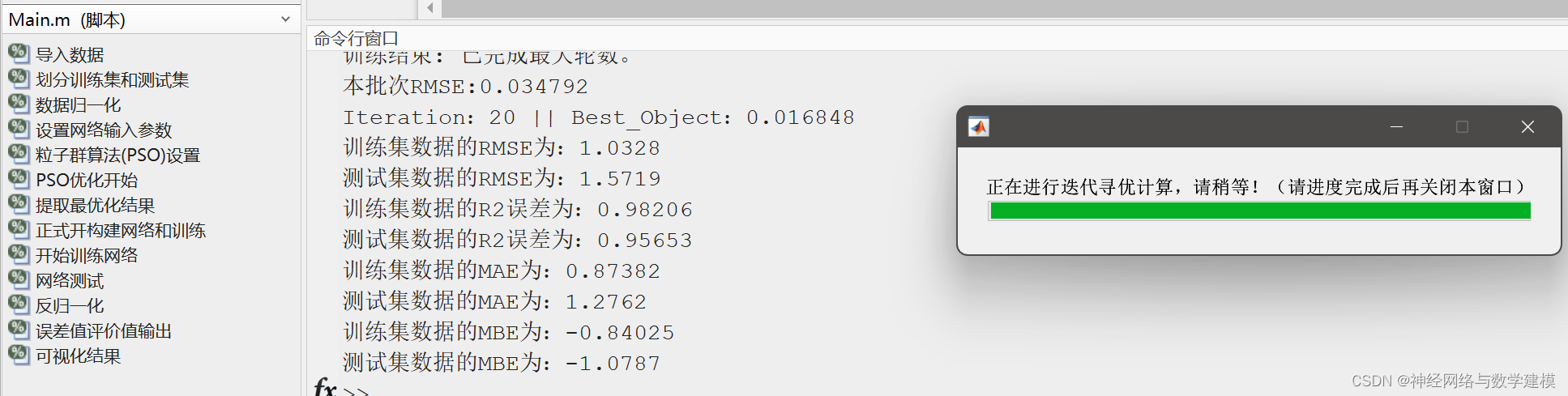
迭代计算过程中,自动显示优化进度条,实时查看程序运行进展情况
-
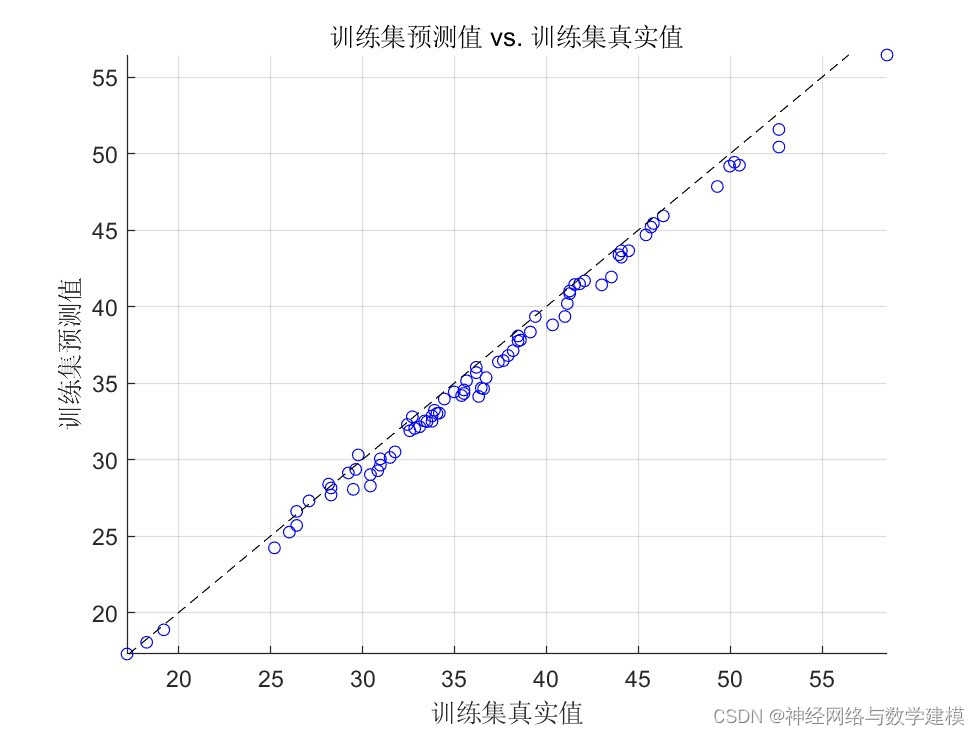
自动输出多种多样的的误差评价指标,自动输出大量实验效果图片
亮点与优势:
-
注释详细,几乎每一关键行都有注释说明,适合小白起步学习
-
直接运行Main函数即可看到所有结果,使用便捷
-
编程习惯良好,程序主体标准化,逻辑清晰,方便阅读代码
-
所有数据均采用Excel格式输入,替换数据方便,适合懒人选手
-
出图详细、丰富、美观,可直观查看运行效果
-
附带详细的说明文档(下图),其内容包括:算法原理+使用方法说明

二、实际运行效果:
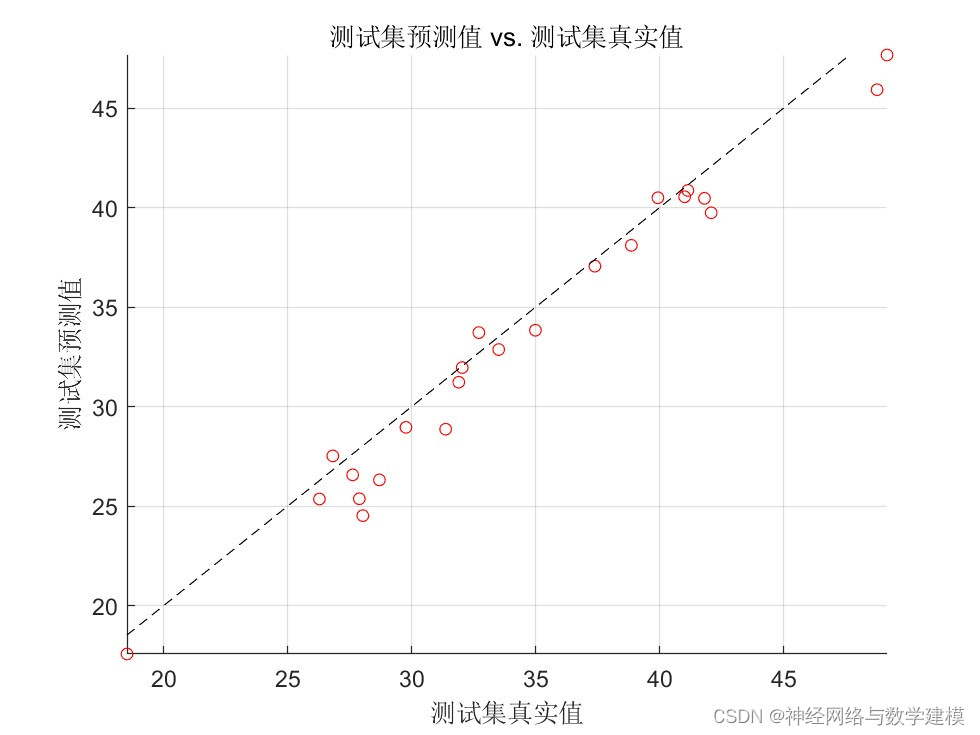
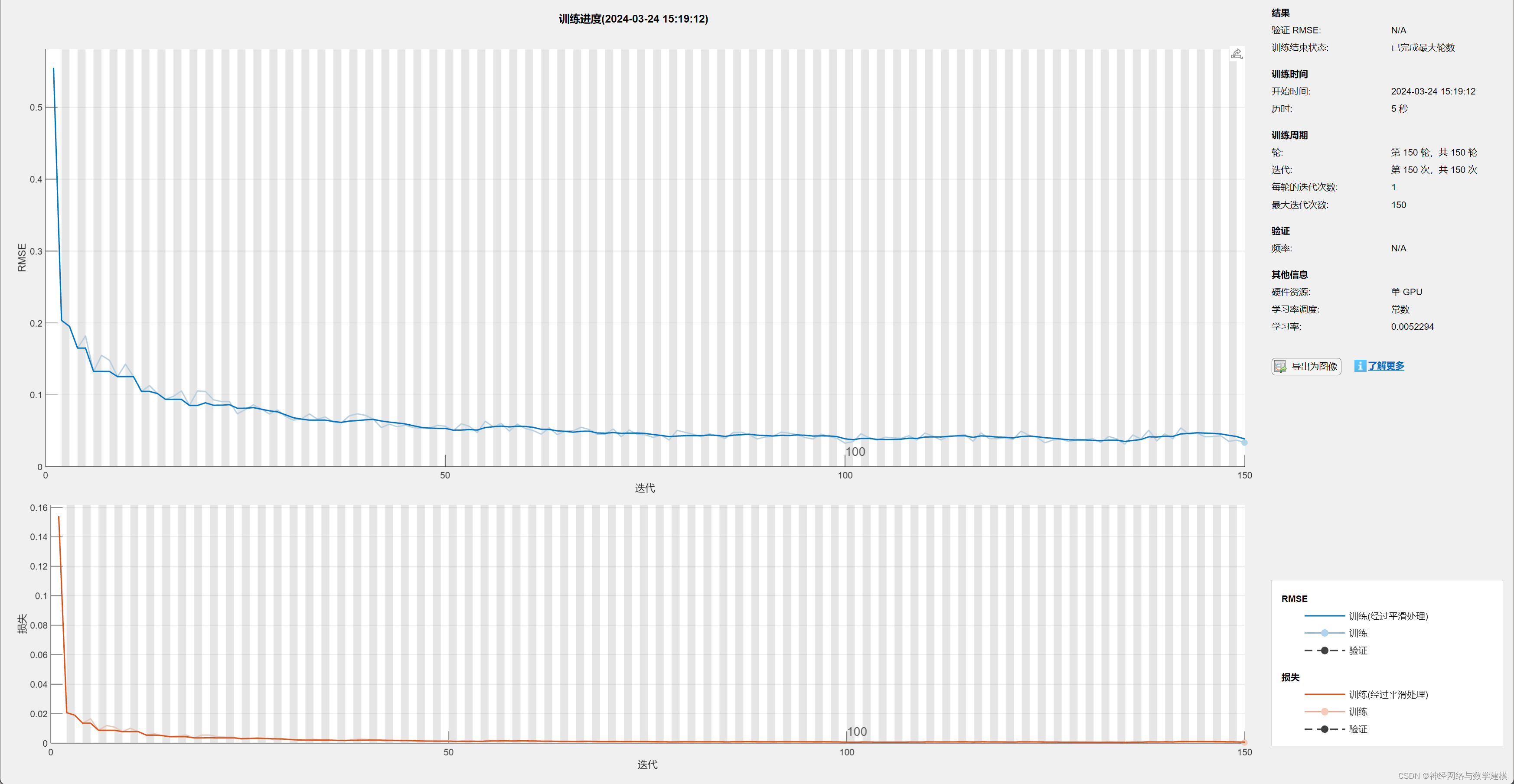
三、算法介绍:
粒子群优化算法(Particle Swarm Optimization, PSO)是一种基于群体智能的优化算法,其灵感源自对鸟群觅食行为的研究。在PSO中,问题的解被表示为粒子群中的个体,这些个体在解空间中移动,并根据其自身经验和群体经验进行调整,以找到最优解。PSO的工作原理如下:
-
初始化:随机生成一群粒子,每个粒子代表了问题的一个解,并赋予每个粒子一个随机的速度和位置。
-
评估:根据问题的目标函数,计算每个粒子的适应度(fitness),即目标函数的值。
-
更新个体最优位置:对于每个粒子,根据其当前位置和历史最优位置之间的比较,更新其个体最优位置。
-
更新群体最优位置:根据所有粒子的个体最优位置,确定群体的全局最优位置。
-
更新速度和位置:根据粒子的速度和位置,以及个体和群体最优位置的差异,调整粒子的速度和位置。
-
迭代:重复步骤2至步骤5,直到达到停止条件(如达到最大迭代次数或达到满意的解)。
CNN-BiLSTM网络结合了卷积神经网络(CNN)和双向长短期记忆网络(BiLSTM),这种网络结构充分利用了CNN在提取局部特征方面的优势,以及BiLSTM在建模长期依赖关系方面的优势,从而能够有效地捕捉输入序列中的空间和时间信息。具体而言,CNN-BiLSTM网络通常由以下几个部分组成:
-
卷积层(CNN):用于提取输入序列的局部特征。CNN通过滑动窗口在输入序列上进行卷积操作,并通过池化层降低特征维度,从而得到序列的局部特征表示。
-
双向长短期记忆网络(BiLSTM):用于建模序列数据中的长期依赖关系。BiLSTM由两个方向的LSTM组成,分别从序列的两个方向(前向和后向)对输入序列进行处理,然后将它们的输出进行合并,以获得更全面的序列表示。
-
全连接层:将CNN和BiLSTM的输出连接起来,并通过全连接层进行特征融合和分类。
四、完整程序下载:
这篇关于PSO-CNN-BiLSTM多输入回归预测|粒子群优化算法-卷积-双向长短期神经网络回归预测|Matlab的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


