本文主要是介绍Python爬取歌曲宝音乐:轻松下载Jay的歌,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
歌曲宝是一个不用付费就能听
jay的歌曲,但是每次都只能播放一首不方便,于是今天想把它下载下来,本地循环播放,它所用到的接口是某我的还不错哈
获取搜索接口
分析html请求接口,获取到的数据是直接渲染好的HTML内容,通过curl我们可以得到搜索接口请求构造

搜索请求:
import requestscookies = {'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710748063,1710768074,1710915841,1710916149','Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710916149',
}headers = {'authority': 'www.gequbao.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'no-cache',# 'cookie': 'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c=1710748063,1710768074,1710915841,1710916149; Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c=1710916149','pragma': 'no-cache','referer': 'https://www.gequbao.com/','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
}response = requests.get('https://www.gequbao.com/s/%E5%91%A8%E6%9D%B0%E4%BC%A6', cookies=cookies, headers=headers)
print(response.text)
print(response)
URL解码
由于接口被编码了,很难看出它是如何提交参数的,通过解码,我们可以快速查看接口构造
解码后,如下图:

用法:替换为想要搜索的歌曲或者是歌手,运行脚本即可
代码替换:
import requestscookies = {'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710748063,1710768074,1710915841,1710916149','Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710916149',
}headers = {'authority': 'www.gequbao.com','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'no-cache',# 'cookie': 'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c=1710748063,1710768074,1710915841,1710916149; Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c=1710916149','pragma': 'no-cache','referer': 'https://www.gequbao.com/','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'document','sec-fetch-mode': 'navigate','sec-fetch-site': 'same-origin','sec-fetch-user': '?1','upgrade-insecure-requests': '1','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36',
}response = requests.get('https://www.gequbao.com/s/周杰伦', cookies=cookies, headers=headers)
print(response.text)
清洗数据
使用Beautiful Soup解析HTML
由于搜索的数据不是接口返回,是HTML渲染的,所以我们需要通过 Python的BS模块进行数据处理
# 使用Beautiful Soup解析HTML
soup = BeautifulSoup(html_data, 'html.parser')# 提取标题
title = soup.title.text
print("标题:", title)# 找到所有的<div>标签,并遍历它们
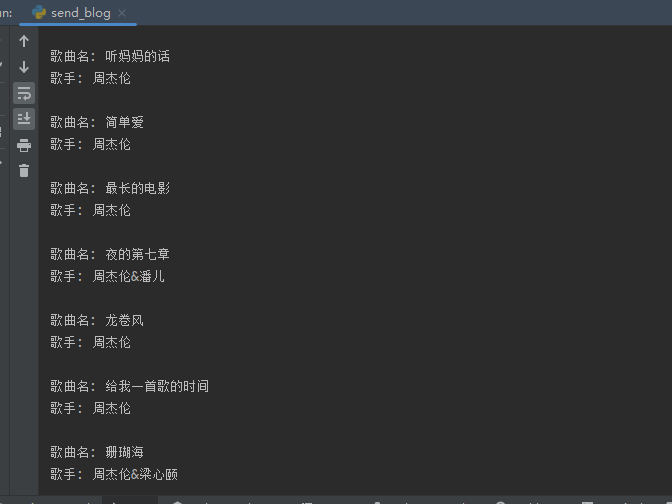
for div in soup.find_all('div', class_='row'):# 检查是否存在类为'text-success'的<div>标签text_success_div = div.find('div', class_='text-success')if text_success_div:# 提取歌手名artist_name = text_success_div.text.strip()# 检查是否存在<a>标签a_tag = div.find('a')if a_tag:# 提取歌曲名song_name = a_tag.text.strip()# 打印歌曲名和歌手名print("歌曲名:", song_name)print("歌手:", artist_name)print()
通过BS处理的数据可以很清晰的获取到歌曲名歌手以及歌曲的ID,而歌曲的ID是用来获取音乐地址
拼接下载链接
通过网页抓包分析,我们发现下载的时候需要歌曲ID,所以在进行下载之前要处理好ID的获取,然后进行下载调用
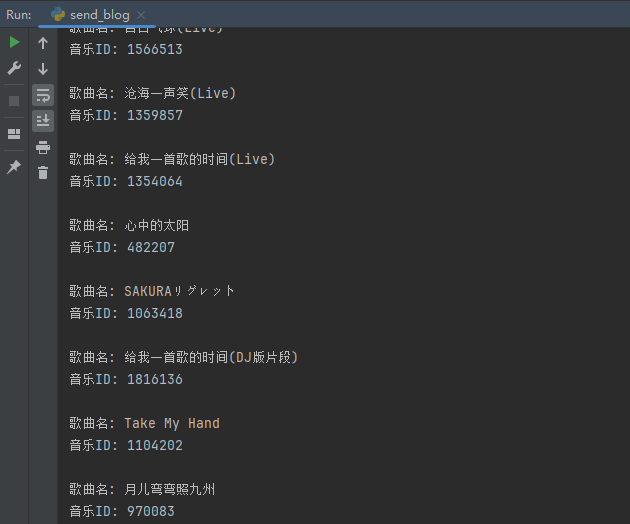
for a_tag in soup.find_all('a', class_='text-primary font-weight-bold'):# 提取 href 属性值href_value = a_tag.get('href')# 提取数字部分music_id = href_value.split('/')[-1]# 提取歌曲名song_name = a_tag.text.strip()# 打印歌曲名和音乐IDprint("歌曲名:", song_name)print("音乐ID:", music_id)print()
解析歌曲id
下载保存
请求歌曲宝下载接口,进行文件下载
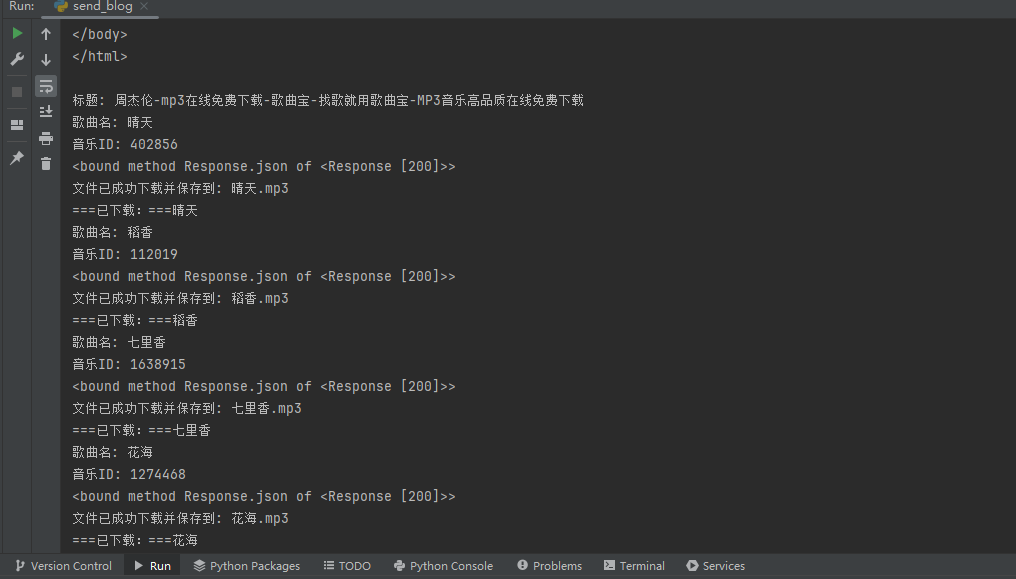
新建一个download方法,进行ID和歌名的接收,在方法内执行音乐下载接口的请求
def download(id,musicname):cookies = {'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710768074,1710915841,1710916149,1710922373','Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c': '1710923549',}headers = {'authority': 'www.gequbao.com','accept': 'application/json, text/javascript, */*; q=0.01','accept-language': 'zh-CN,zh;q=0.9','cache-control': 'no-cache',# 'cookie': 'Hm_lvt_c2b69091f94cb4368f25c28fc7c2d28c=1710768074,1710915841,1710916149,1710922373; Hm_lpvt_c2b69091f94cb4368f25c28fc7c2d28c=1710923549','pragma': 'no-cache','referer': 'https://www.gequbao.com/music/112019','sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Google Chrome";v="122"','sec-ch-ua-mobile': '?0','sec-ch-ua-platform': '"Windows"','sec-fetch-dest': 'empty','sec-fetch-mode': 'cors','sec-fetch-site': 'same-origin','user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36','x-requested-with': 'XMLHttpRequest',}params = {'id': id,'json': '1',}response = requests.get('https://www.gequbao.com/api/play_url', params=params, cookies=cookies, headers=headers)print(response.json)music_data=response.json()if music_data['code']==1:url = music_data['data']['url'] # 替换为要下载的文件的URLlocal_filename = musicname+".mp3" # 保存到本地的文件名,可以根据需要修改# 发送GET请求下载文件response = requests.get(url)# 检查请求是否成功if response.status_code == 200:# 打开文件以二进制写模式保存with open(local_filename, 'wb') as file:# 将文件内容写入本地文件file.write(response.content)print("文件已成功下载并保存到:", local_filename)else:print("下载文件失败:", response.status_code)else:print("下载失败"+music_data['msg'])运行结束后,保存在根目录,如下图:
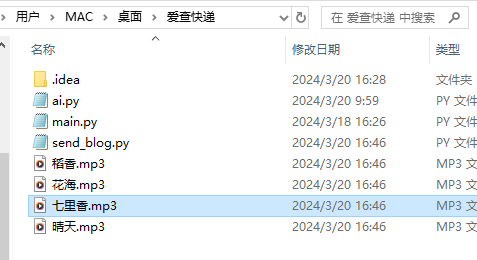
尝试放歌
关于

🍋希望你能喜欢我的其他作品
《记一次云之家签到抓包》
《记一次视频抓包m3u8解密过程》
《抓包部分软件时无网络+过代理检测 解决办法 安卓黄鸟httpcanary+vmos》
《Python】记录抓包分析自动领取芝麻HTTP每日免费IP(成品+教程)》
《某课抓包视频 安卓手机:黄鸟+某课app+VirtualXposed虚拟框架》
推荐专栏:
《Python爬虫脚本项目实战》
该专栏往期文章:
《【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)》
🥦如果感觉看完文章还不过瘾,欢迎查看我的其它专栏
🥦作者对python有很大的兴趣,完成过很多独立的项目:例如滇医通等等脚本,但是由于版权的原因下架了,爬虫这一类审核比较严谨,稍有不慎就侵权违规了,所以在保证质量的同时会对文章进行筛选
如果您对爬虫感兴趣请收藏或者订阅该专栏哦《Python爬虫脚本项目实战》,如果你有项目欢迎联系我,我会同步教程到本专栏!
🚀Python爬虫项目实战系列文章!!
⭐⭐欢迎订阅⭐⭐
【Python爬虫项目实战一】获取Chatgpt3.5免费接口文末付代码(过Authorization认证)
【Python爬虫项目实战二】Chatgpt还原验证算法-解密某宝伪知网数据接口
⭐⭐欢迎订阅⭐⭐

Python爬虫脚本项目实战

这篇关于Python爬取歌曲宝音乐:轻松下载Jay的歌的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





