本文主要是介绍深度学习之10分钟入门h5py,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 0、前言
- 1、HDF5 简介
- 2、h5py 安装
- 3、h5py 简介
- 3.1 打开和创建 h5py 文件
- 3.2 创建数据集
- 3.3 创建组
- 3.4 属性
- # 参考文章
0、前言
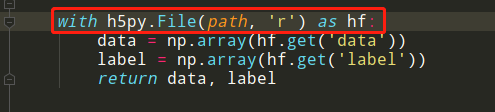
最近在看SRCNN代码的时候碰到了h5py,就查询了一下这个函数h5py.File,了解了一下这种读取图像的方式,发现它相比于其他读取方式,速度、内存占用和压缩程度都更强。下面跟我一起简单地入门h5py 😃
1、HDF5 简介
HDF(Hierarchical Data Format)指一种为存储和处理大容量科学数据设计的文件格式及相应库文件。最早由美国国家超级计算应用中心 NCSA 研究开发,目前在非盈利组织HDF Group维护下继续发展。HDF支持多种商业及非商业的软件平台,包括MATLAB、Java、Python、R 和 Julia 等等,现在也提供了 Spark ,其版本包括了 HDF4 和 HDF5 。
当前流行的版本是 HDF5。HDF5 拥有一系列的优异特性,使其特别适合进行大量科学数据的存储和操作,如它支持非常多的数据类型,灵活,通用,跨平台,可扩展,高效的 I/O 性能,支持几乎无限量(高达 EB)的单文件存储等,详见其官方介绍:https://support.hdfgroup.org/HDF5/ 。
Python 中有一系列的工具可以操作和使用 HDF5 数据,其中最常用的是 h5py 和 PyTables,我们只说今天的主角 h5py。
2、h5py 安装
官方教程:http://docs.h5py.org/en/latest/build.html#install
使用 Anaconda 或 Miniconda:
conda install h5py
用 Enthought Canopy,可以使用 GUI 安装包安装 或者:
enpkg h5py
或者使用pip 直接安装:
pip install h5py
3、h5py 简介
一个HDF5文件就是一个容器,用于储存两类对象:
-
数据集(dataset),类似于数组的数据集合,和 numpy 的数组差不多;
-
组(group),类似于文件夹的容器,它好比 python 中的字典,有键(key)和值(value)。
group 中可以存放 dataset 或者其他的 group。”键”就是组成员的名称,”值”就是组成员对象本身(组或者数据集),下面来看下如何创建组和数据集。
3.1 打开和创建 h5py 文件
HDF5 文件通常像标准 Python 文件对象一样工作。它们支持 r / w / a 等标准模式,并且在不再使用时应关闭。但是,显然没有“text”与“binary”模式的概念。
import h5pyf = h5py.File("myh5py.hdf5", "w")
文件名可以是字节字符串或 unicode 字符串。有效mode是:
| mode | 说明 |
|---|---|
| r | 只读,文件必须存在 |
| r+ | 读 / 写,文件必须存在 |
| w | 创建文件,已经存在的文件会被覆盖掉 |
| w- / x | 创建文件,文件如果已经存在则出错 |
| a | 打开已经存在的文件进行读 / 写,如果不存在则创建一个新文件读 / 写(默认) |
在当前目录下会生成一个 myh5py.hdf5 文件
3.2 创建数据集
使用 Group.create_dataset() 或创建新数据集 Group.require_dataset() 。应使用组索引语法()检索现有数据集。dset = group[“name”]
要创建一个空数据集,我们所要做的就是指定名称,形状和可选的数据类型(默认为’f’):
import h5pyf = h5py.File("myh5py.hdf5", "w")
# deset1是数据集的name,(100,)代表数据集的shape,i代表的是数据集的元素类型
dset = f.create_dataset("deset1", (100,), 'i')for key in f.keys():print(key)print(f[key].name)print(f[key].shape)print(f[key].value)# deset1
# /deset1
# (100,)
# [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
# 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
# 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
# 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
# 0. 0. 0. 0.]
如何给数据集赋值,有两种方法:
import h5py
import numpy as npf = h5py.File("myh5py.hdf5", "w")# 第一种方法:重新创建一个空数据集并赋值
d = f.create_dataset("dset1", (100,), 'i')
d[...] = np.arange(100)# 第二种方法:直接创建一个数据集并赋值
f["dset2"] = np.arange(100)for key in f.keys():print(f[key].name)print(f[key].value)# /dset1
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
# 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
# 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
# 96 97 98 99]
# /dset2
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
# 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
# 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
# 96 97 98 99]
如果有现成的 NumPy 数组,那么可以在创建数据集的时候将数据集初始化为现有的 NumPy 数组,这样就不必指定数据的类型和形状了,只需要把数组名传给参数 data:
import h5py
import numpy as npf = h5py.File("myh5py.hdf5", "w")arr = np.arange(100)
dset = f.create_dataset("dset", data=arr)for key in f.keys():print(f[key].name)print(f[key].value)# /dset
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
# 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
# 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
# 96 97 98 99]
3.3 创建组
组是 HDF5 文件组织的容器机制。从 Python 的角度来看,它们的运作方式有点像词典。在这种情况下,“keys”是组成员的名称,“values”是成员本身(Group 和 Dataset)对象。
import h5py
import numpy as npf = h5py.File("myh5py.hdf5", "w")# 创建一个名字为bar的组
g = f.create_group("bar")# 在bar这个组里面分别创建name为dset1, dset2的数据集并赋值
g["dset1"] = np.arange(100)
g["dset2"] = np.arange(100).reshape((10, 10))for key in g.keys():print(g[key].name)print(g[key].value)# /bar/dset1
# [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
# 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
# 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
# 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
# 96 97 98 99]# /bar/dset2
# [[ 0 1 2 3 4 5 6 7 8 9]
# [10 11 12 13 14 15 16 17 18 19]
# [20 21 22 23 24 25 26 27 28 29]
# [30 31 32 33 34 35 36 37 38 39]
# [40 41 42 43 44 45 46 47 48 49]
# [50 51 52 53 54 55 56 57 58 59]
# [60 61 62 63 64 65 66 67 68 69]
# [70 71 72 73 74 75 76 77 78 79]
# [80 81 82 83 84 85 86 87 88 89]
# [90 91 92 93 94 95 96 97 98 99]]
注意观察,数据集 dset1 和 dset2 的名字和前面的不一样。
如果是直接创建的数据集,不在任何组里面,那么它的名字就是/+名字,比如:/dset;现在这两个数据集都在bar这个组里面,名字就变成了/bar+/名字,比如:/bar/dset2,有点文件夹的感觉。
import h5pyf=h5py.File("myh5py.hdf5","w")
print(f.name)
# /
print(f.keys())
# <KeysViewHDF5 []>
文件中所有对象的名称都是文本字符串(unicode 在 Py2 上,str 在 Py3 上)。这些将在传递到 HDF5 C 库之前使用 HDF5 批准的 UTF-8 编码进行编码。也可以使用字节字符串检索对象,字节字符串将按原样传递给 HDF5 。
新组很容易创建:
import h5pyf=h5py.File("myh5py.hdf5","w")g = f.create_group("bar")
print(g.name)
# /bar
subgrp = g.create_group("baz")
print(subgrp.name)
# /bar/baz
也可以隐式创建多个中间组:
import h5pyf=h5py.File("myh5py.hdf5","w")g2 = f.create_group("/some/long/path")
print(g2.name)
# /some/long/path
g3 = f['/some/long']
print(g3.name)
# /some/long
再来看一个例子:
import h5py
import numpy as npf = h5py.File("myh5py.hdf5", "w")# 创建组bar1,组bar2,数据集dset
g1 = f.create_group("bar1")
g2 = f.create_group("bar2")
d = f.create_dataset("dset", data=np.arange(10))# 在bar1组里面创建一个组car1和一个数据集dset1。
c1 = g1.create_group("car1")
d1 = g1.create_dataset("dset1", data=np.arange(10))# 在bar2组里面创建一个组car2和一个数据集dset2
c2 = g2.create_group("car2")
d2 = g2.create_dataset("dset2", data=np.arange(10))# 根目录下的组和数据集
print(".............")
for key in f.keys():print(f[key].name)# bar1这个组下面的组和数据集
print(".............")
for key in g1.keys():print(g1[key].name)# bar2这个组下面的组和数据集
print(".............")
for key in g2.keys():print(g2[key].name)# 顺便看下car1组和car2组下面都有什么,估计你都猜到了为空。
print(".............")
print(c1.keys())
print(c2.keys())# .............
# /bar1
# /bar2
# /dset
# .............
# /bar1/car1
# /bar1/dset1
# .............
# /bar2/car2
# /bar2/dset2
# .............
# <KeysViewHDF5 []>
# <KeysViewHDF5 []>
3.4 属性
属性是使 HDF5 成为“self-describing”格式的关键部分。HDF5 的最好特征之一就是你可以在描述的数据后储存元数据(metadata)。所有的 groups 和 datasets 都支持几个数据位的附属命名,称为属性。Group和 Dataset 对象是在 HDF5 中存储元数据的官方方式。
属性具有以下属性:
- 它们可以从任何标量或 NumPy 数组创建
- 每个属性应该很小(通常 < 64k)
- 没有部分 I / O(即切片); 必须读取整个属性。
.attrs代理对象属于下面的 attributeManager 类。此类支持字典样式的接口。
属性可以通过 attrs 这个代理对象来获取,这会再一次执行字典接口:
import h5pyf = h5py.File("myh5py.hdf5", "w")dset = f.create_dataset("mydataset", (100,), dtype='i')dset.attrs['number'] = 100
print(dset.attrs['number'])
print('number' in dset.attrs)# 100
# True
更多的内容,请参考官方文档——HDF5 for Python
如果想要更多的资源,欢迎关注 @我是管小亮,文字强迫症MAX~
回复【福利】即可获取我为你准备的大礼,包括C++,编程四大件,NLP,深度学习等等的资料。
想看更多文(段)章(子),欢迎关注微信公众号「程序员管小亮」~

# 参考文章
- 官方文档——HDF5 for Python
- python库——h5py入门讲解
这篇关于深度学习之10分钟入门h5py的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



