本文主要是介绍Orange3数据预处理(行选择组件),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
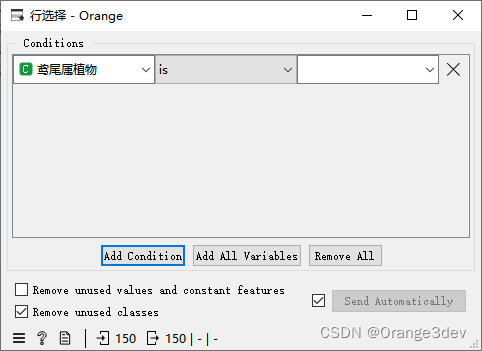
选择行
根据数据特征的条件选择数据实例。
输入
数据:输入数据集
输出
匹配数据:满足条件的实例
不匹配数据:不满足条件的实例
数据:带有额外列的数据,显示实例是否被选中
这个小部件根据用户定义的条件从输入数据集中选择一个子集。匹配选择规则的实例将被放置在输出的匹配数据通道中。
数据选择的标准以一系列合取项的形式呈现(即,选择的项是满足所有条件项的项)。
条件项是通过选择一个属性、从一系列操作符中选择一个操作符以及(如果需要)定义用于条件项的值来定义的。对于离散的、连续的和非字符串属性,操作符是不同的。
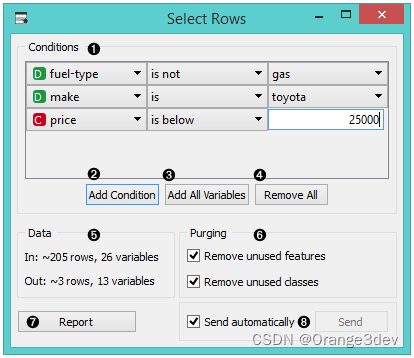
1.您想要应用的条件、它们的操作符和相关值
2.向条件列表中添加新的条件。
3.一次性添加所有可能的变量。
4.一次性删除所有列出的变量。
5.输入数据集的信息以及满足条件(们)的实例的信息
6.清空输出数据。
7.当“发送自动”框被勾选时,所有更改将被自动传达给其他小部件。
8.生成报告。
条件组成的变化将更新信息面板(数据输出)。
如果选择了“发送自动”,则在条件组成或其任何项发生变化时,输出将被更新。
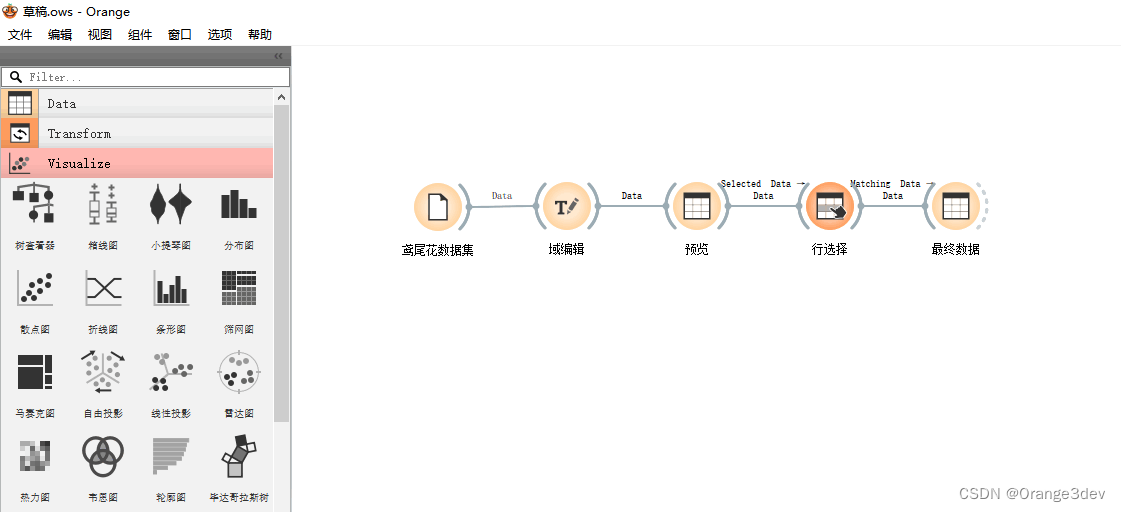
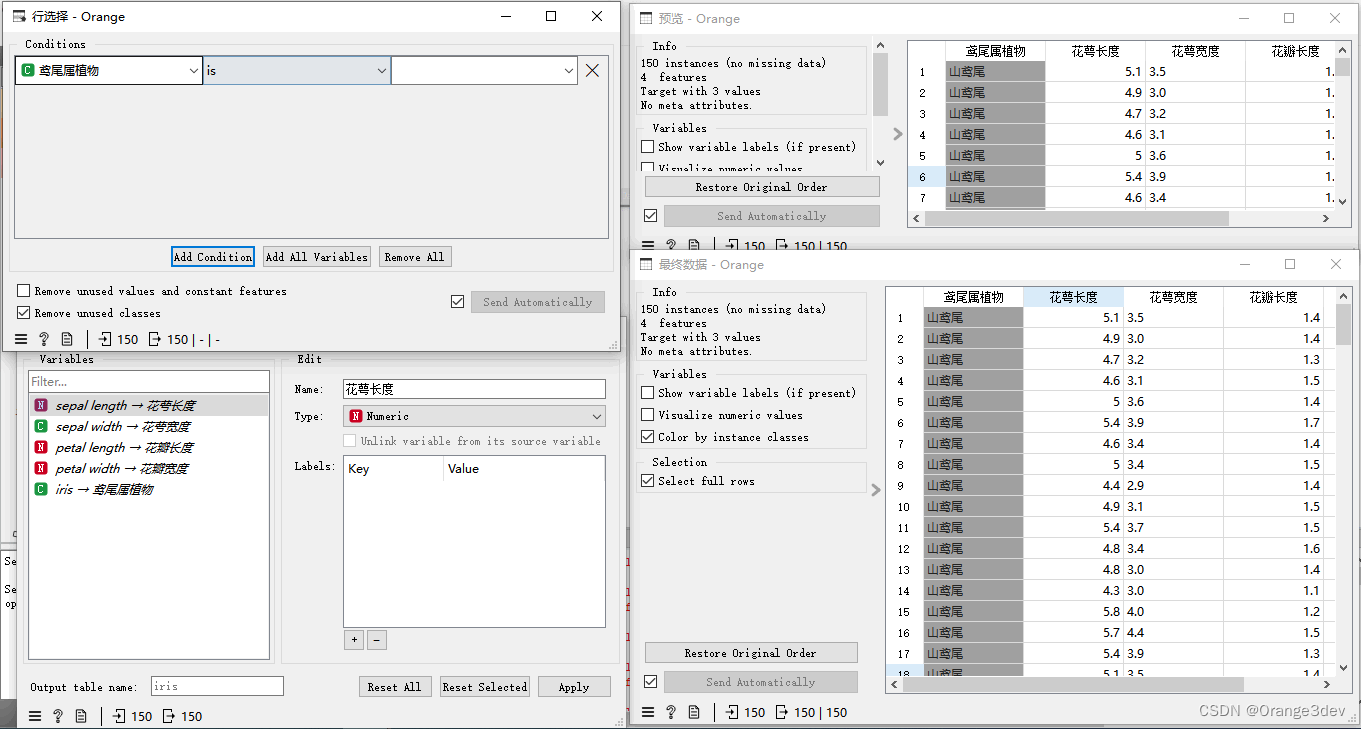
在Orange3软件中,iris数据集是一个非常出名的数据集,常常用于机器学习和数据科学的入门教学。该数据集来自鸢尾花的测量数据。
这个数据集包含以下四个特征:
sepal length(花萼长度): 这是单个鸢尾花花萼从基部到顶端的直线长度,单位是厘米。
sepal width(花萼宽度): 这是单个鸢尾花花萼最大宽度的直线长度,单位是厘米。
petal length(花瓣长度): 这是单个鸢尾花花瓣的直线长度,从基部到顶端,单位是厘米。
petal width(花瓣宽度): 这是单个鸢尾花花瓣的最大宽度,单位是厘米。
每一行数据表示对应一个样本的测量数据,每种鸢尾花大约有50个样本数据。
而特殊的一列是 species(物种)。这是预测的目标值或标签,鸢尾花有三种不同的物种:setosa(山鸢尾),versicolor(变色鸢尾),virginica(维吉尼亚鸢尾)。
视频教程:关注我不迷路, 抖音:Orange3dev
https://www.douyin.com/user/MS4wLjABAAAAicBGZTE2kX2EVHJPe8Ugk3_nlJk9Nha8OZh4Bo_nTu8
1-Orange3安装
2-Orange3汉化DIY
3-Orange3创建快方式
4-数据导入(文件&数据表格组件)
5-数据导入(Python组件)
6-Python库安装(SQL表组件)
7-数据导入(Mysql)
8-数据导入(数据绘画和公式组件)
9-数据修改(域编辑和保存组件)
10-数据可视化(调色板&数据信息组件)
11-数据可视化(特征统计组件)
12-数据预处理(行选择组件)
13-特征选择(Rank组件)
14-数据转换(数据采样组件)
15-数据预处理(列选择组件)
16-数据预处理(转置组件)
17-数据预处理(合并数据组件)
18-数据预处理(连接组件)无主表且列数不同
19-数据预处理(连接组件)主附表
20-数据预处理(索引选择器组件)
21-数据预处理(唯一组件)
22-数据预处理(列聚合组件)
23-数据预处理(分组组件)
24-数据预处理(透视图表组件)
25-数据预处理(转换器组件)-表格互为模板
26-数据预处理(转换器组件)-转换示例
27-数据预处理(预处理器组件)-基本信息
28-数据预处理(预处理器组件)-特征选择
29-数据预处理(预处理器组件)-填充缺失值并标准化特征
30-数据预处理(预处理器组件)-离散化连续变量
31-数据预处理(预处理器组件)-连续化离散变量
32-数据预处理(预处理器组件)-主成分分析PCA与CUR分解
33-数据预处理(缺失值处理组件)
34-数据预处理(连续化组件)
35-数据预处理(离散化组件)
36-数据预处理(随机化组件)
37-数据预处理(清理特征组件)-清理未使用特征值及常量特征
38-数据预处理(宽转窄组件)
39-数据预处理(公式组件)
40-数据预处理(分类器组件)
41-数据预处理(创建实例)
42-数据预处理(Python代码组件)
这篇关于Orange3数据预处理(行选择组件)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




