本文主要是介绍Spark Rebalance hint的倾斜的处理(OptimizeSkewInRebalancePartitions),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景
本文基于Spark 3.5.0
目前公司在做小文件合并的时候用到了 Spark Rebalance 这个算子,这个算子的主要作用是在AQE阶段的最后写文件的阶段进行小文件的合并,使得最后落盘的文件不会太大也不会太小,从而达到小文件合并的作用,这其中的主要原理是在于三个规则:OptimizeSkewInRebalancePartitions,CoalesceShufflePartitions,OptimizeShuffleWithLocalRead,这里主要说一下OptimizeSkewInRebalancePartitions规则,CoalesceShufflePartitions的作用主要是进行文件的合并,是得文件不会太小,OptimizeShuffleWithLocalRead的作用是加速shuffle fetch的速度。
结论
OptimizeSkewInRebalancePartitions的作用是对小文件进行拆分,使得罗盘的文件不会太大,这个会有个问题,如果我们在使用Rebalance(col)这种情况的时候,如果col的值是固定的,比如说值永远是20240320,那么这里就得注意一下,关于OptimizeSkewInRebalancePartitions涉及到的参数spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled,spark.sql.adaptive.advisoryPartitionSizeInBytes,spark.sql.adaptive.rebalancePartitionsSmallPartitionFactor 这些值配置,如果这些配置调整的不合适,就会导致写文件的时候有可能只有一个Task在运行,那么最终就只有一个文件。而且大大加长了整个任务的运行时间。
分析
直接到OptimizeSkewInRebalancePartitions中的代码中来:
override def apply(plan: SparkPlan): SparkPlan = {if (!conf.getConf(SQLConf.ADAPTIVE_OPTIMIZE_SKEWS_IN_REBALANCE_PARTITIONS_ENABLED)) {return plan}plan transformUp {case stage: ShuffleQueryStageExec if isSupported(stage.shuffle) =>tryOptimizeSkewedPartitions(stage)}}
如果我们禁用掉对rebalance的倾斜处理,也就是spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled为false(默认是true),那么就不会应用此规则,那么如果Col为固定值的情况下,就只会有一个Task进行文件的写入操作,也就只有一个文件,因为一个Task会拉取所有的Map的数据(因为此时每个maptask上的hash(Col)都是一样的,此时只有一个reduce task去拉取数据),如图:
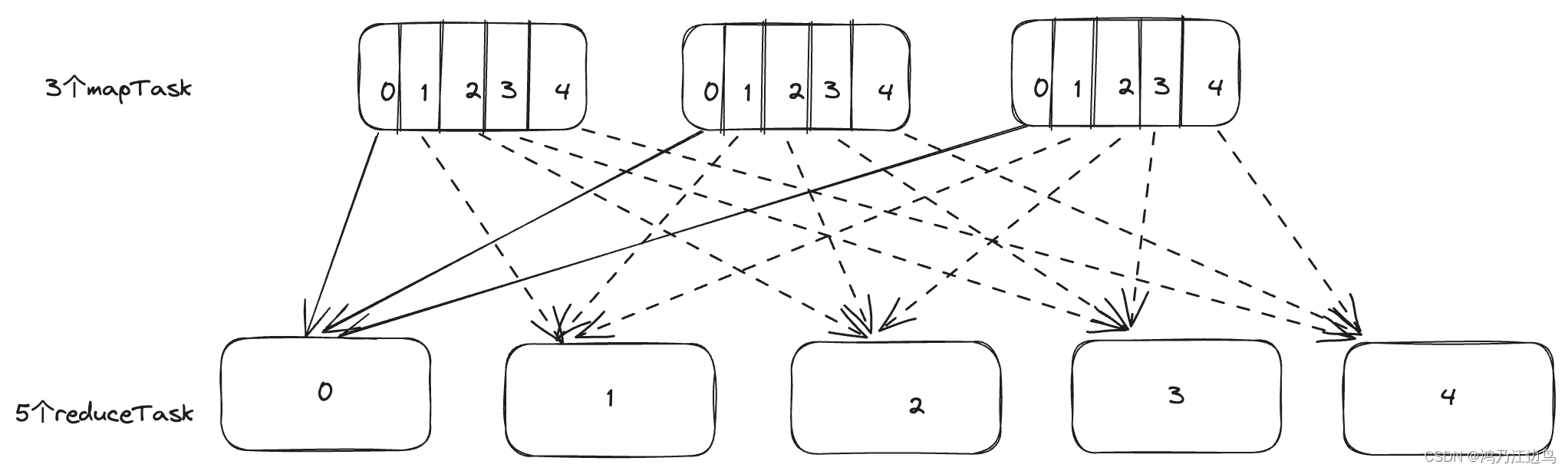
假如说hash(col)为0,那实际上只有reduceTask0有数据,其他的ReduceTask1等等都是没有数据的,所以最终只有ReduceTask0写文件,并且只有一个文件。
在看合并的计算公式,该数据流如下:
tryOptimizeSkewedPartitions||\/optimizeSkewedPartitions||\/ShufflePartitionsUtil.createSkewPartitionSpecs||\/ShufflePartitionsUtil.splitSizeListByTargetSize
splitSizeListByTargetSize方法中涉及到的参数解释如下 :
- 参数 sizes: Array[Long] 表示属于同一个reduce任务的maptask任务的大小数组,举例 sizes = [100,200,300,400]
表明该任务有4个maptask,0表示maptask为0的所属reduce的大小,1表示maptask为1的所属reduce的大小,依次类推,图解如下:
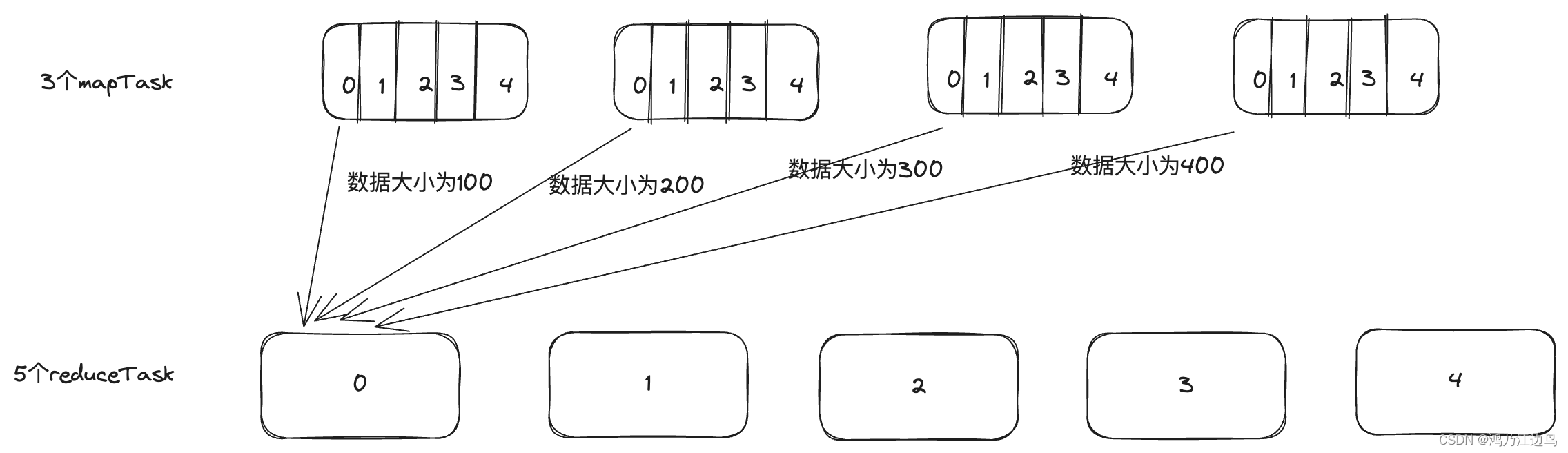
比如说reduceTask0的从Maptask拉取的数据的大小分别是100,200,300,400.
- 参数targetSize 为
spark.sql.adaptive.advisoryPartitionSizeInBytes的值,假如说是256MB - 参数smallPartitionFactor为
spark.sql.adaptive.rebalancePartitionsSmallPartitionFactor的值,默认是0.2
这里有个计算公式:
def tryMergePartitions() = {// When we are going to start a new partition, it's possible that the current partition or// the previous partition is very small and it's better to merge the current partition into// the previous partition.val shouldMergePartitions = lastPartitionSize > -1 &&((currentPartitionSize + lastPartitionSize) < targetSize * MERGED_PARTITION_FACTOR ||(currentPartitionSize < targetSize * smallPartitionFactor ||lastPartitionSize < targetSize * smallPartitionFactor))if (shouldMergePartitions) {// We decide to merge the current partition into the previous one, so the start index of// the current partition should be removed.partitionStartIndices.remove(partitionStartIndices.length - 1)lastPartitionSize += currentPartitionSize} else {lastPartitionSize = currentPartitionSize}}。。。while (i < sizes.length) {// If including the next size in the current partition exceeds the target size, package the// current partition and start a new partition.if (i > 0 && currentPartitionSize + sizes(i) > targetSize) {tryMergePartitions()partitionStartIndices += icurrentPartitionSize = sizes(i)} else {currentPartitionSize += sizes(i)}i += 1}tryMergePartitions()partitionStartIndices.toArray
这里的计算公式大致就是:从每个maptask中的获取到属于同一个reduce的数值,依次累加,如果大于targetSize就尝试合并,直至到最后一个maptask,
可以看到tryMergePartitions有个计算公式:currentPartitionSize < targetSize * smallPartitionFactor,也就是说如果当前maptask的对应的reduce分区数据 小于 256MB*0.2 = 51.2MB 的话,也还是会合并到前一个分区中去,如果smallPartitionFactor设置过大,可能会导致所有的分区都会合并到一个分区中去,最终会导致一个文件会有几十GB(也就是targetSize * smallPartitionFactor`*shuffleNum),
比如说以下的测试案例:
val targetSize = 100val smallPartitionFactor2 = 0.5// merge last two partition if their size is not bigger than smallPartitionFactor * targetval sizeList5 = Array[Long](50, 50, 40, 5)assert(ShufflePartitionsUtil.splitSizeListByTargetSize(sizeList5, targetSize, smallPartitionFactor2).toSeq ==Seq(0))val sizeList6 = Array[Long](40, 5, 50, 45)assert(ShufflePartitionsUtil.splitSizeListByTargetSize(sizeList6, targetSize, smallPartitionFactor2).toSeq ==Seq(0))
这种情况下,就会只有一个reduce任务运行。
这篇关于Spark Rebalance hint的倾斜的处理(OptimizeSkewInRebalancePartitions)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



