本文主要是介绍十、C#基数排序算法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
基数排序是一种非比较性排序算法,它通过将待排序的数据拆分成多个数字位进行排序。
实现原理
-
首先找出待排序数组中的最大值,并确定排序的位数。
-
从最低位(个位)开始,按照个位数的大小进行桶排序,将元素放入对应的桶中。
-
将各个桶中的元素按照存放顺序依次取出,组成新的数组。
-
接着按照十位数进行桶排序,再次将元素放入对应的桶中。
-
再次将各个桶中的元素按照存放顺序依次取出,组成新的数组。
-
重复上述操作,以百位、千位、万位等位数为基准进行排序,直至所有位数都被排序。
代码实现
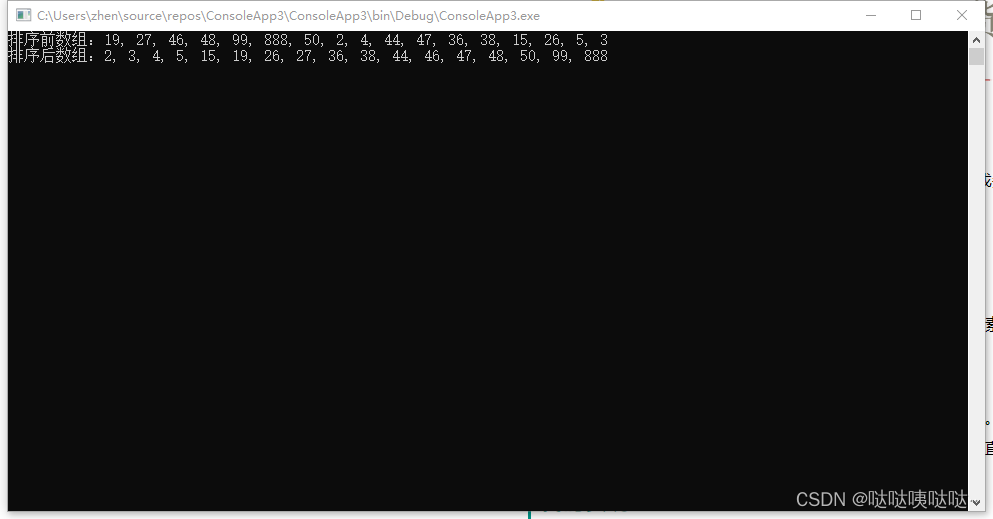
public static void RadixSort(int[] array){if (array == null || array.Length < 2){return;}//获取数组中的最大值,确定排序的位数int max = GetMaxValue(array);//进行基数排序for (int exp = 1; max / exp > 0; exp *= 10){CountingSort(array, exp);}}private static void CountingSort(int[] array, int exp){int arrayLength = array.Length;int[] output = new int[arrayLength];int[] count = new int[10];//统计每个桶中的元素个数for (int i = 0; i < arrayLength; i++){count[(array[i] / exp) % 10]++;}//计算每个桶中最后一个元素的位置for (int i = 1; i < 10; i++){count[i] += count[i - 1];}//从原数组中取出元素,放入到输出数组中for (int i = arrayLength - 1; i >= 0; i--){output[count[(array[i] / exp) % 10] - 1] = array[i];count[(array[i] / exp) % 10]--;}//将输出数组复制回原数组for (int i = 0; i < arrayLength; i++){array[i] = output[i];}}private static int GetMaxValue(int[] arr){int max = arr[0];for (int i = 1; i < arr.Length; i++){if (arr[i] > max){max = arr[i];}}return max;}public static void RadixSortRun(){int[] array = { 19, 27, 46, 48, 99, 888, 50, 2, 4, 44, 47, 36, 38, 15, 26, 5, 3 };Console.WriteLine("排序前数组:" + string.Join(", ", array));RadixSort(array);Console.WriteLine("排序后数组:" + string.Join(", ", array));}运行结果
总结
基数排序是一种稳定的排序算法,它的时间复杂度为O(d*(n+r)),其中d是位数,n是元素个数,r是基数(桶的个数)。相比其他比较性排序算法,基数排序的优势在于减少了元素之间的比较次数,并且可以处理负数。但是,基数排序的缺点是需要额外的空间来存储临时数组。
C#十大排序总结-CSDN博客
这篇关于十、C#基数排序算法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




