本文主要是介绍[自研开源] MyData 数据集成之任务调度模式 v0.7,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
开源地址:gitee | github
详细介绍:MyData 基于 Web API 的数据集成平台
部署文档:用 Docker 部署 MyData
使用手册:MyData 使用手册
试用体验:http://demo.mydata.work
交流 Q 群:430089673
概述
本篇基于 数据集成之任务流程 介绍任务调度模式的使用场景和配置操作。
任务调度模式
mydata 使用 API 方式集成、无 SDK 侵入,当业务系统与 mydata 集成时,不同业务数据的同步频率存在差异,因此对 API 的调用频率需要贴合业务场景;
集成任务的调度模式如下图:
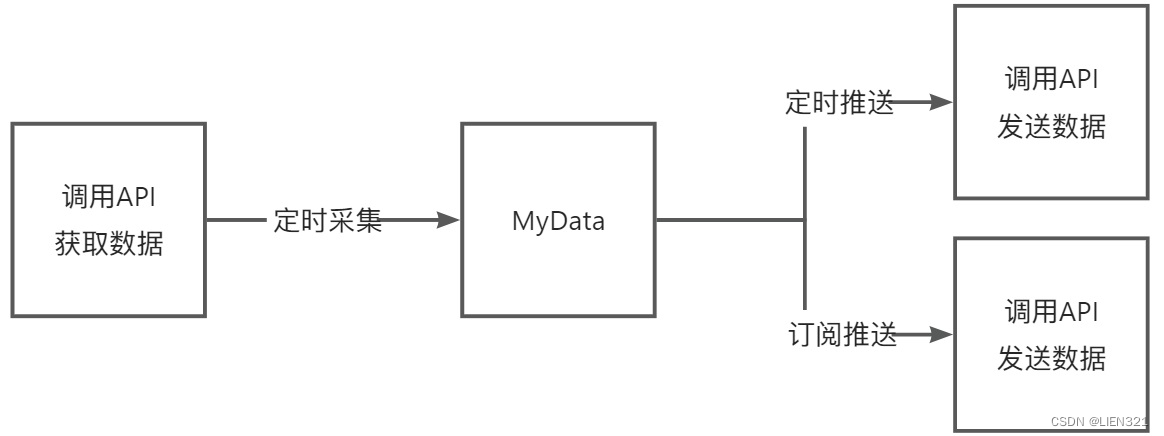
-
从 API 获取数据 即
提供数据类型的任务目前只有定时周期方式,配置方式如下图:
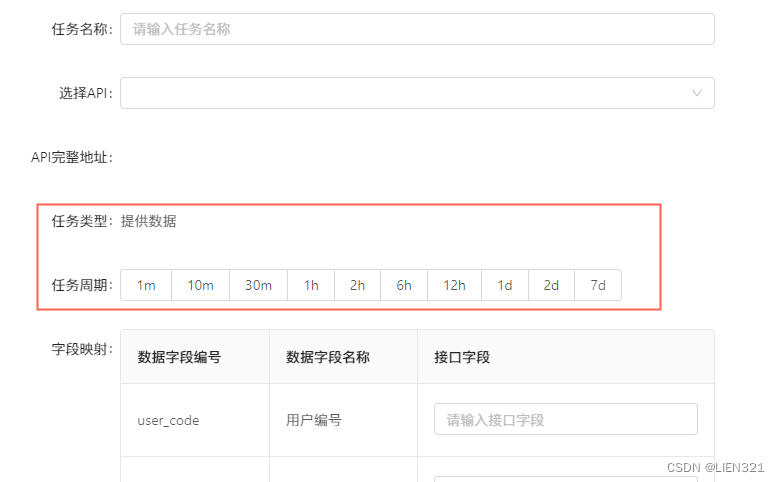
-
向 API 发送数据 即
消费数据类型的任务 可选择是否订阅-
选择
订阅表示当数据发送变化时 才向 API 推送数据,其他时间不会调用;
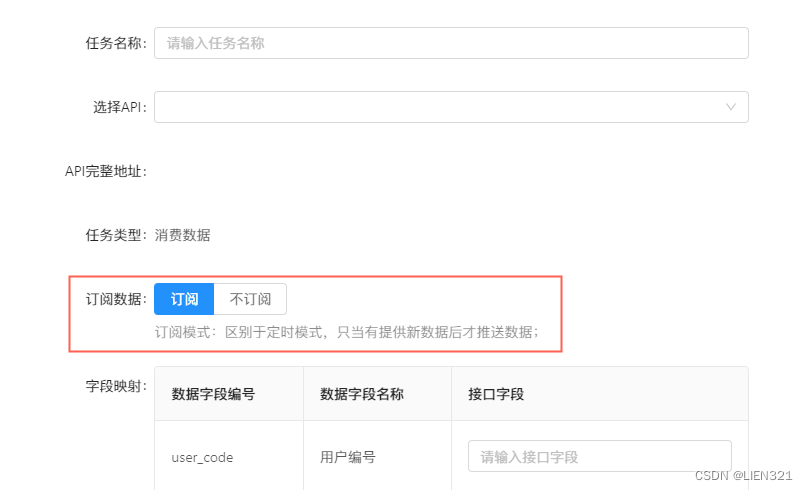
-
选择
不订阅则采用前面相同的定时周期模式,需要选择周期;
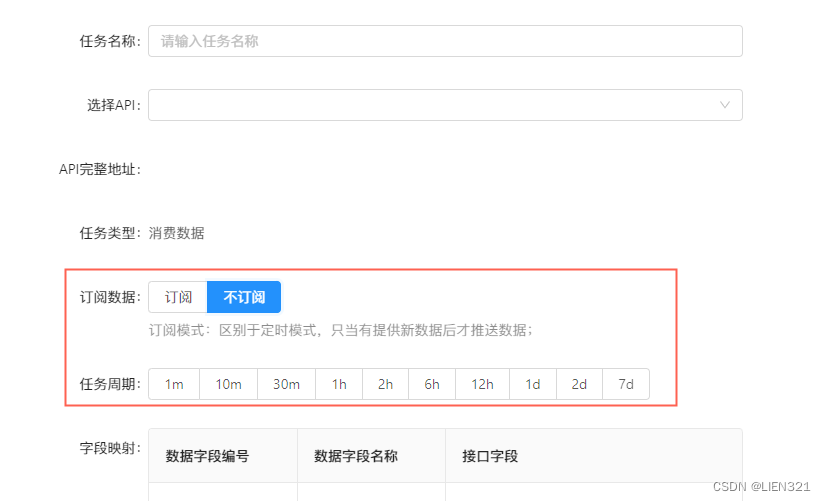
-
使用场景
根据采集周期间隔长短、推送是否订阅可以组合成 4 种模式:短周期采集 + 订阅推送、短周期采集 + 长周期推送、长周期采集 + 订阅推送、长周期采集 + 长周期推送;
注:以下示例仅供参考
-
短周期采集 + 订阅推送,适用于实时性较高的场景;
例如:订单与仓储,用户在线下单后“立即”同步到仓储系统,以便仓库出货;

- 用户在商城平台下单购买商品;
- 订单系统生成订单记录,包括商品信息、收货地址的等;
- MyData 每分钟采集任务 从订单系统 API 获取订单记录;
- MyData 向订阅订单数据的仓储系统 API 推送本次获取的数据;
-
短周期采集 + 长周期推送,适用于集中采集、批量推送的场景;
例如:仓储与物流,仓储完成一部分出货打包后 批量同步到物流系统,以便物流上门取货;
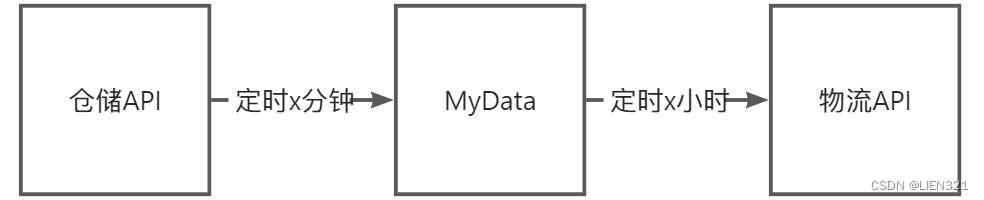
-
长周期采集 + 订阅推送,适用于阶段性采集汇总并立即推送的场景;
例如:商品销量统计与热门商品,每隔数小时 获取商品销量统计数据,立即同步到商城更新热门商品数据;
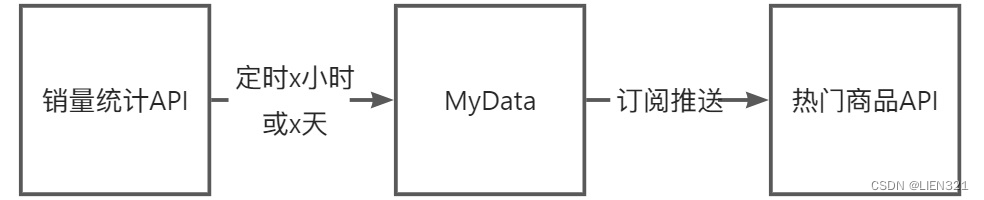
-
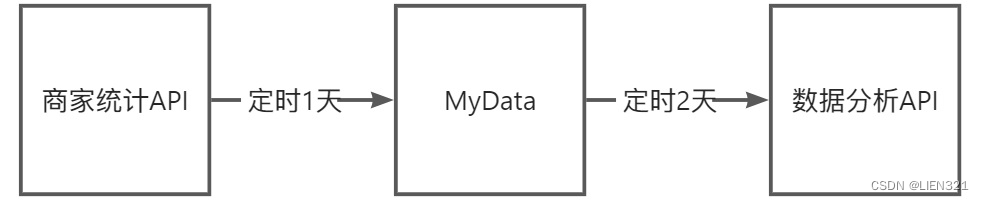
长周期采集 + 长周期推送,适用于周期性汇总统计,长周期推送的场景;
例如:商家统计与数据分析,每隔 1 天 获取商家统计数据,再每个 2 天 将统计数据同步到数据分析系统;
执行订阅任务
- 根据提供数据任务的数据项,查询订阅相同数据项的任务;
- 批量执行,并传入业务数据;
/*** 执行订阅任务** @param taskInfo 当前执行的任务*/
public void executeSubscribedTask(TaskInfo taskInfo) {// 当前任务不是 提供数据,则结束if (MdConstant.DATA_PRODUCER != taskInfo.getOpType()) {return;}List<Map> produceDataList = taskInfo.getProduceDataList();if (CollUtil.isEmpty(produceDataList)) {return;}// 查询相同数据的订阅任务List<Task> subTasks = taskService.listRunningSubTasks(taskInfo.getDataId());subTasks.forEach(task -> {TaskInfo subTaskInfo = build(task);// 订阅任务现在执行subTaskInfo.setStartTime(new Date());// 向订阅任务传入数据subTaskInfo.setConsumeDataList(produceDataList);// 指定订阅任务,调用接口发送数据executeJob(subTaskInfo);});
}
这篇关于[自研开源] MyData 数据集成之任务调度模式 v0.7的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







