本文主要是介绍模型部署——RKNN模型量化精度分析及混合量化提高精度,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型部署——RKNN模型量化精度分析及混合量化提高精度(附代码)-CSDN博客
3.1 量化精度分析流程
计算不同情况下,同一层网络输入值的余弦距离,来近似的查看每一层精度损失的情况。具体量化精度分析的流程如下:
3.2 量化精度分析accuracy_analysis接口
量化精度分析调用accuracy_analysis接口,推理并产生快照,也就是dump出每一层的tensor数据。会dump出包括fp32和quant两种数据类型的快照,用于计算量化误差。
注:
该接口只能在 build或 hybrid_quantization_step2之后调用,并且原始模型应该为非量化的模型,否则会调用失败。
该接口使用的量化方式与config_中指定的一致。
3.3.1 参数修改
量化精度分析代码对应于源码包中accuracy_analysis.py脚本,需要修改的地方如下:
from rknn.api import RKNN
import cv2
import numpy as npif __name__=='__main__':rknn = RKNN(verbose=True) # 打印详细日志# 调用config接口设置模型的预处理、量化方法等参数rknn.config(mean_values = [[123.675,116.28,103.53]], # mean_values表示预处理要减去的均值化参数std_values = [[58.395,58.395,58.395]], # std_values 表示预处理要除的标准化参数target_platform = "rk3588" # target_platform表示生成的RKNN模型要运行在哪个RKNPU平台上。通常有rk3588,rk3566,rv1126等)# 添加load_xxx接口,进行常用深度学习模型的导入 将深度学习模型导入rknn.load_pytorch(model = "./resnet18.pt",input_size_list = [[1, 3,224,224]])# 使用build接口来构建RKNN模型rknn.build(do_quantization = True,dataset = "dataset.txt",rknn_batch_size = -1)# 调用export_rknn接口导出RKNN模型rknn.export_rknn(export_path="resnet18.rknn")# 使用accuracy_analysis 接口进行模型量化精度分析rknn.accuracy_analysis(inputs = ["space_shuttle_224.jpg"], # inputs 表示进行推理的图像output_dir = 'snapshot', # 表示精度分析的输出目录target = None, # 表示目标硬件平台device_id = None, # 表示设备的编号)rknn.release()4.2.2.2 代码
具体代码对应于源码包中hrhrid_quantization文件夹中的setp1.py脚本,具体代码如下:
from rknn.api import RKNN
import cv2
import numpy as npif __name__=='__main__':rknn = RKNN(verbose=True) # 打印详细日志# 调用config接口设置模型的预处理、量化方法等参数rknn.config(mean_values = [[123.675,116.28,103.53]], # mean_values表示预处理要减去的均值化参数std_values = [[58.395,58.395,58.395]], # std_values 表示预处理要除的标准化参数target_platform = "rk3588" # target_platform表示生成的RKNN模型要运行在哪个RKNPU平台上。通常有rk3588,rk3566,rv1126等)# 添加load_xxx接口,进行常用深度学习模型的导入 将深度学习模型导入rknn.load_pytorch(model = "./resnet18.pt",input_size_list = [[1, 3,224,224]])# 使用hybrid_quantization_step 接口进行混合量化第一步rknn.hybrid_quantization_step1(dataset="dataset.txt", # 表示模型量化所需要的数据集rknn_batch_size=-1, # 表示自动调整模型输入batch数量proposal=False, # 设置为True,可以自动产生混合量化的配置建议,比较耗时# proposal= True, # 设置为True,可以自动产生混合量化的配置建议,比较耗时proposal_dataset_size=1, # 第三步骤所用的图片)rknn.release()
4.2.2.5 添加量化层
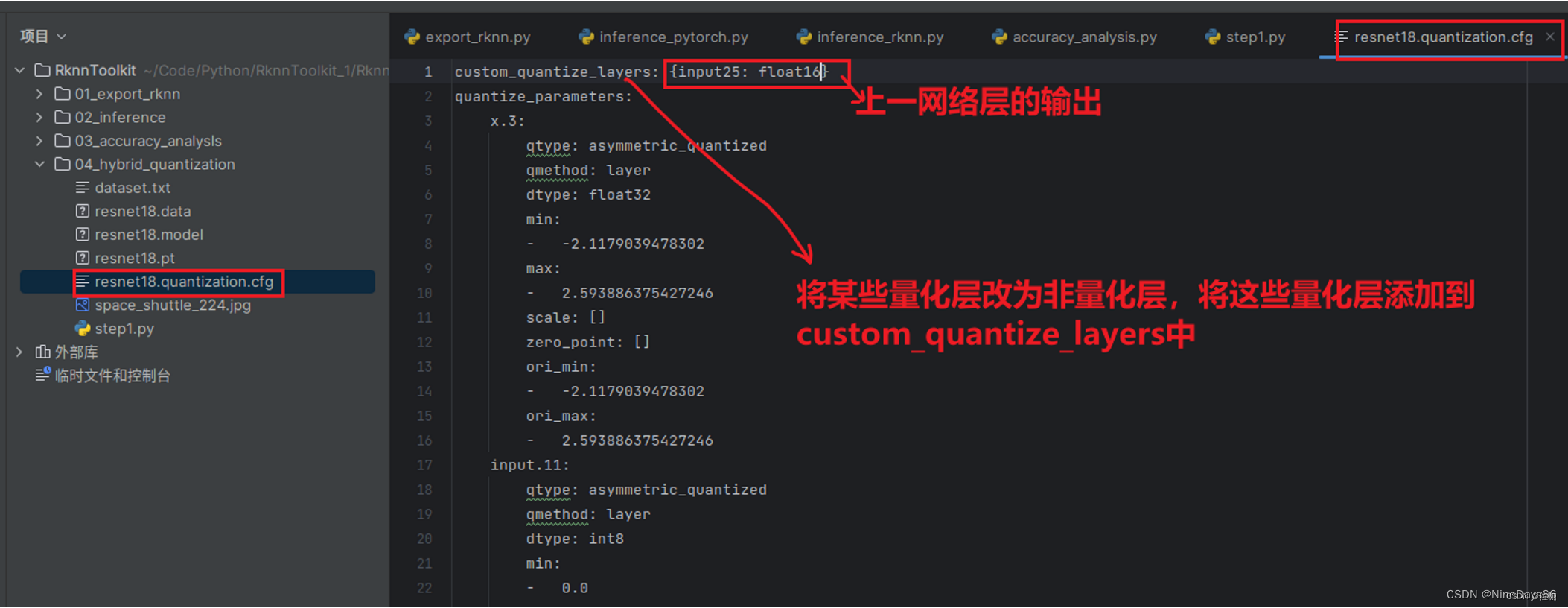
从上面可以看出25层,33层,43层,51层等损失较大,这里举例选取其中input.25层,将该层从量化层转为非量化层,在resnet18.quantization.cfg文件夹添加,如下:
4.3.3 代码
代码对应源码包中的step2.py,具体代码如下:
from rknn.api import RKNNif __name__=="__main__":rknn = RKNN(verbose=True)# 调用hyborid_quantization_step2接口进行混合量化的第二个步骤rknn.hybrid_quantization_step2(model_input = "resnet18.model", # 表示第一步生成的模型文件data_input= "resnet18.data", # 表示第一步生成的配置文件model_quantization_cfg="resnet18.quantization.cfg" # 表示第一步生成的量化配置文件)# 调用量化精度分析接口(评估RKNN模型)rknn.accuracy_analysis(inputs=["space_shuttle_224.jpg"],output_dir="./snapshot",target = None)# 调用RKNN模型导出RKNN模型rknn.export_rknn(export_path="./resnet18.rknn")rknn.release()这篇关于模型部署——RKNN模型量化精度分析及混合量化提高精度的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







