本文主要是介绍[LLM] 大模型基础|预训练|有监督微调SFT | 推理,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
现在的大模型在进行预训练时大部分都采用了GPT的预训练任务,即 Next token prediction。
标题:Language Model Training and Inference: From Concept to Code
作者:CAMERON R. WOLFE
原文链接:https://cameronrwolfe.substack.com/p/language-model-training-and-inference
要理解大语言模型(LLM),首先要理解它的本质,无论预训练、微调还是在推理阶段,核心都是next token prediction,也就是以自回归的方式从左到右逐步生成文本。
基本概念:
- Token:在NLP中,一个“token”可以是一个词、一个字或一个标点符号。例如,句子“我爱北京”被切分成三个tokens: “我”, “爱” 和 “北京”。
- Prediction:预测是指根据模型的当前输入,猜测接下来应该出现的token是什么。
模型训练:
- 在训练过程中,模型通过大量的文本数据来学习文本之间的模式和结构。
- 例如,模型会看到成千上万次的“我爱X”这样的模式,其中X可以是各种不同的词。通过这样的训练,模型会学会哪些词最有可能出现在“我爱”之后。
要理解清楚这一训练过程,最主要的就是搞清楚预训练的数据怎么构造,数据怎么喂给模型,模型输出的是什么,以及如何计算loss。
什么是token?
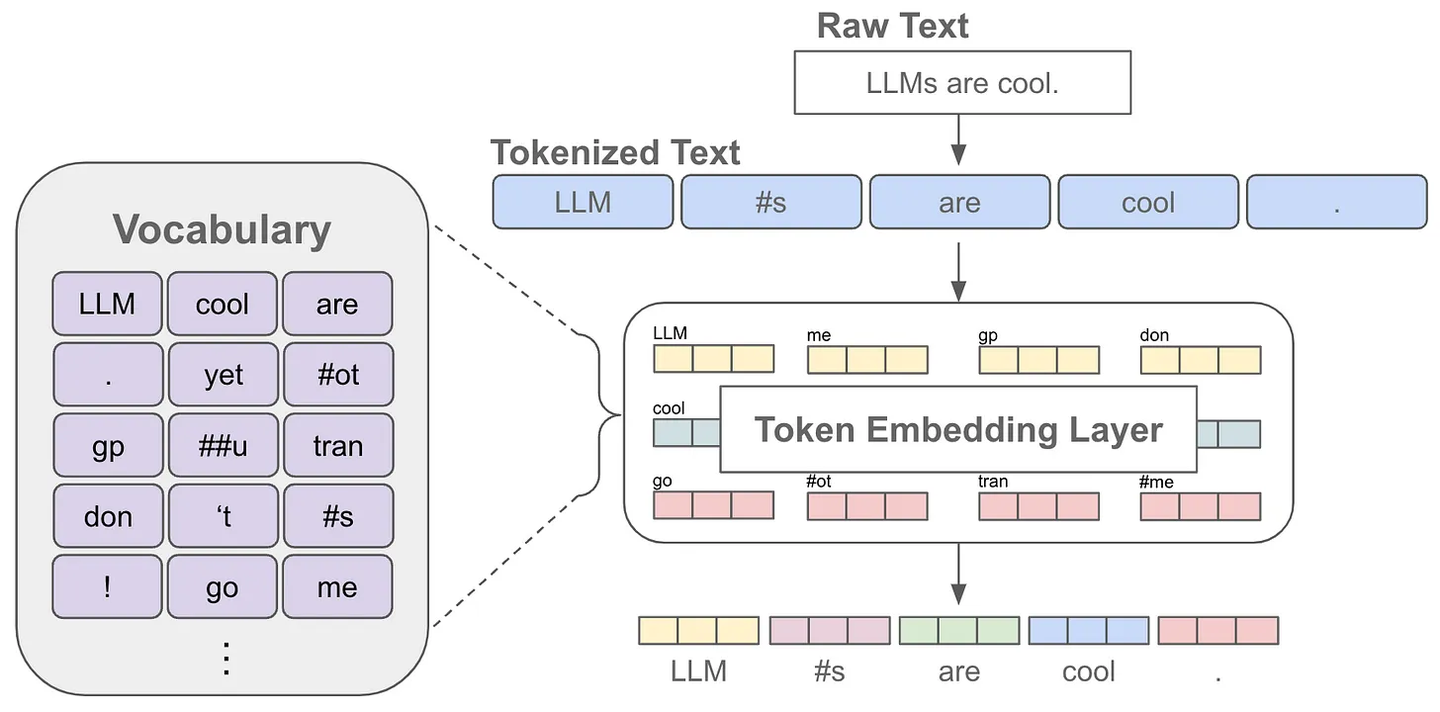
token是指文本中的一个词或者子词,给定一句文本,送入语言模型前首先要做的是对原始文本进行tokenize,也就是把一个文本序列拆分为离散的token序列

其中,tokenizer是在无标签的语料上训练得到的一个token数量固定且唯一的分词器,这里的token数量就是大家常说的词表,也就是语言模型知道的所有tokens。
当我们对文本进行分词后,每个token可以对应一个embedding,这也就是语言模型中的embedding层,获得某个token的embedding就类似一个查表的过程
我们知道文本序列是有顺序的,而常见的语言模型都是基于注意力机制的transformer结构,无法自动考虑文本的前后顺序,因此需要手动加上位置编码,也就是每个位置有一个位置embedding,然后和对应位置的token embedding进行相加
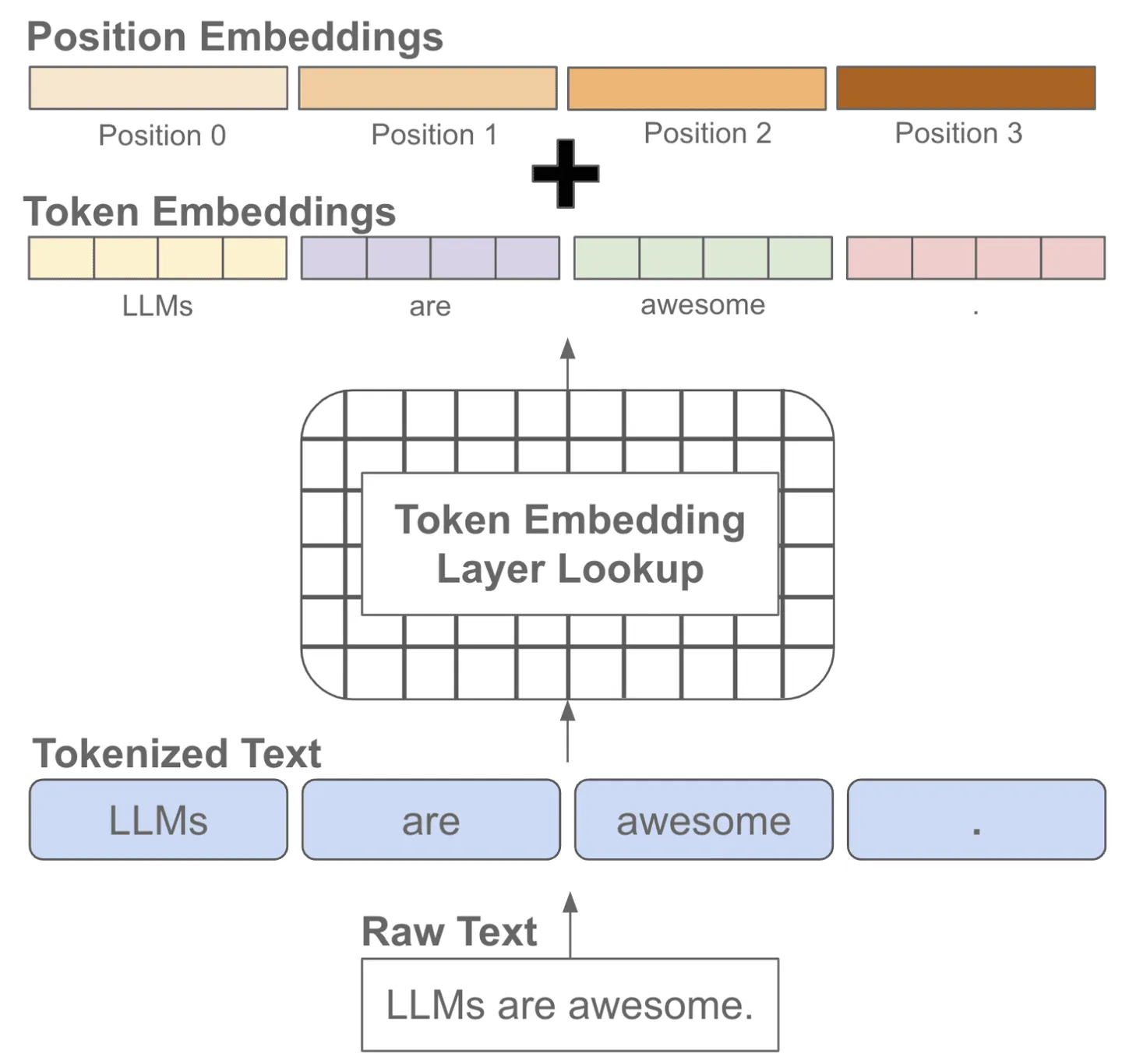
在模型训练或推理阶段大家经常会听到上下文长度这个词,它指的是模型训练时接收的token训练的最大长度,如果在训练阶段只学习了一个较短长度的位置embedding,那模型在推理阶段就不能够适用于较长文本(因为它没见过长文本的位置编码)
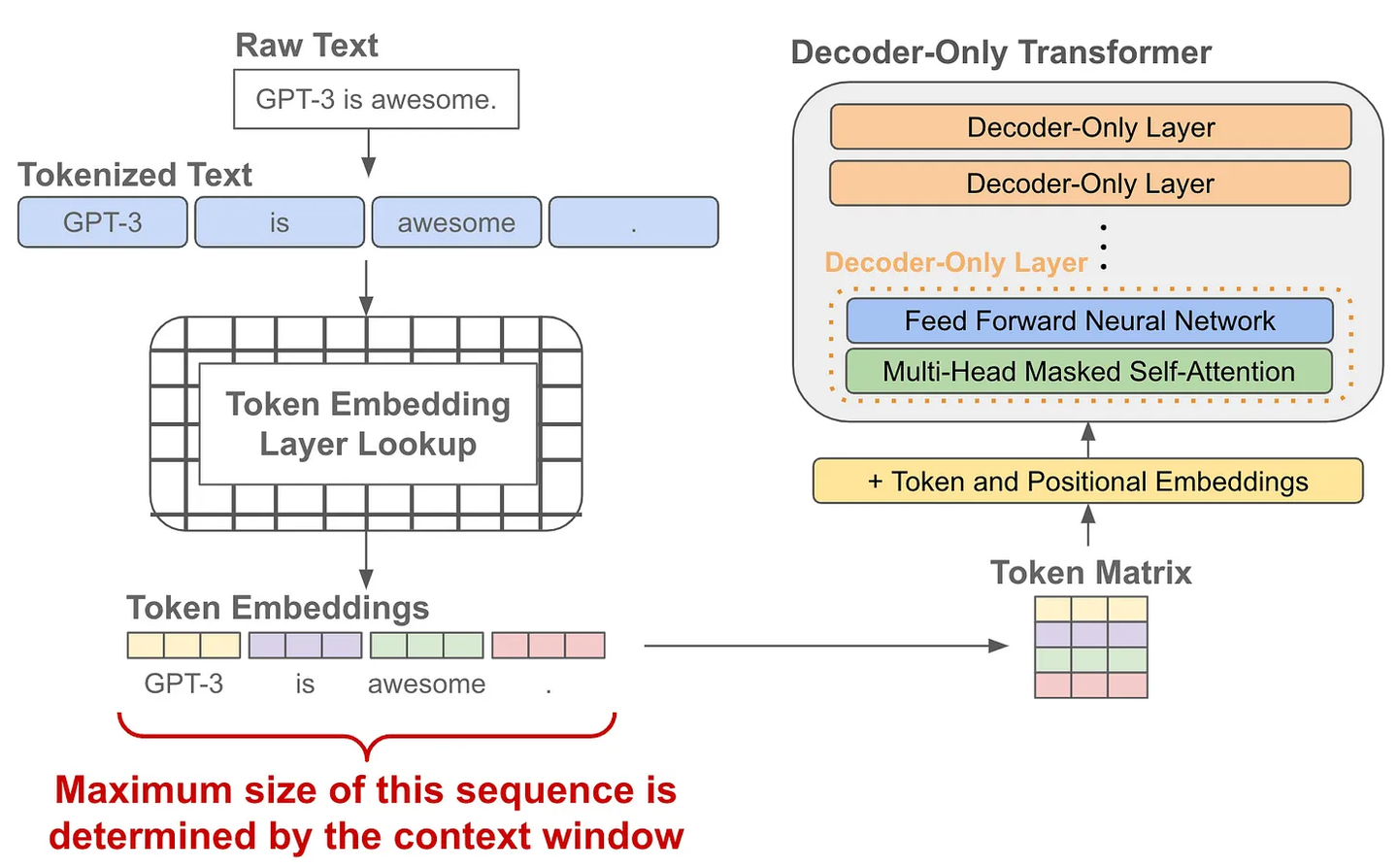
语言模型的预训练
当我们有了token embedding和位置embedding后,将它们送入一个decoder-only的transofrmer模型,它会在每个token的位置输出一个对应的embedding(可以理解为就像是做了个特征加工)
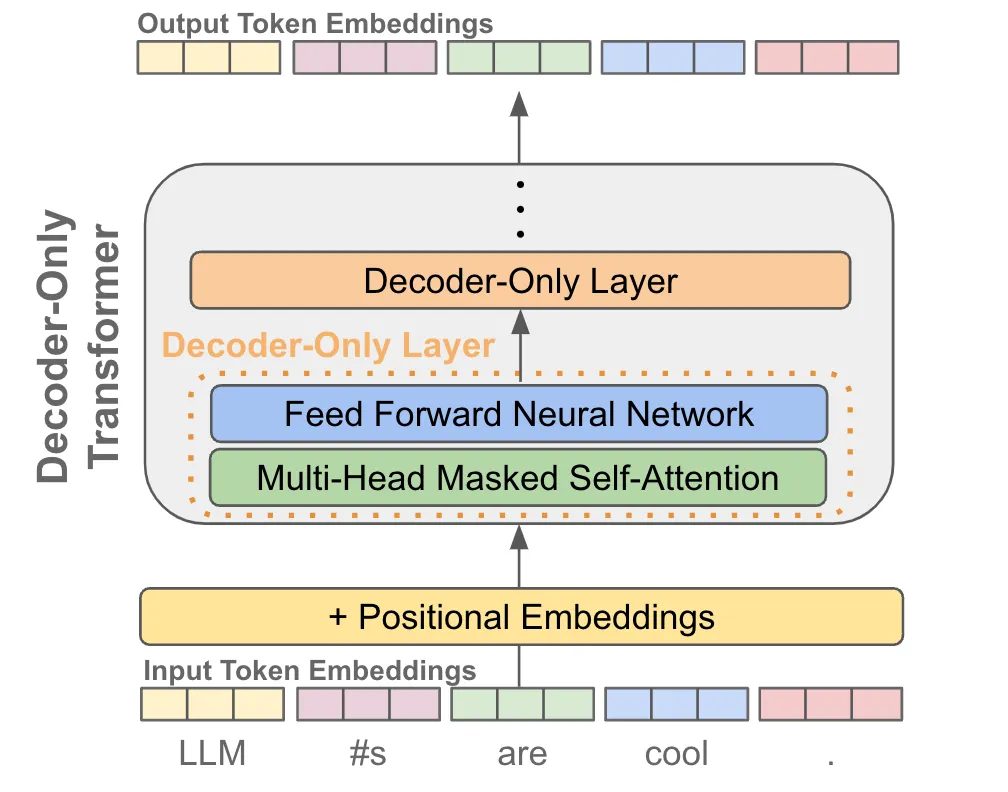
有了每个token的一个输出embedding后,我们就可以拿它来做next token prediction了,其实就是当作一个分类问题来看待:
- 首先我们把输出embedding送入一个线性层,输出的维度是词表的大小,就是让预测这个token的下一个token属于词表的“哪一类”
- 为了将输出概率归一化,需要再进行一个softmax变换
- 训练时就是最大化这个概率使得它能够预测真实的下一个token
- 推理时就是从这个概率分布中采样下一个token
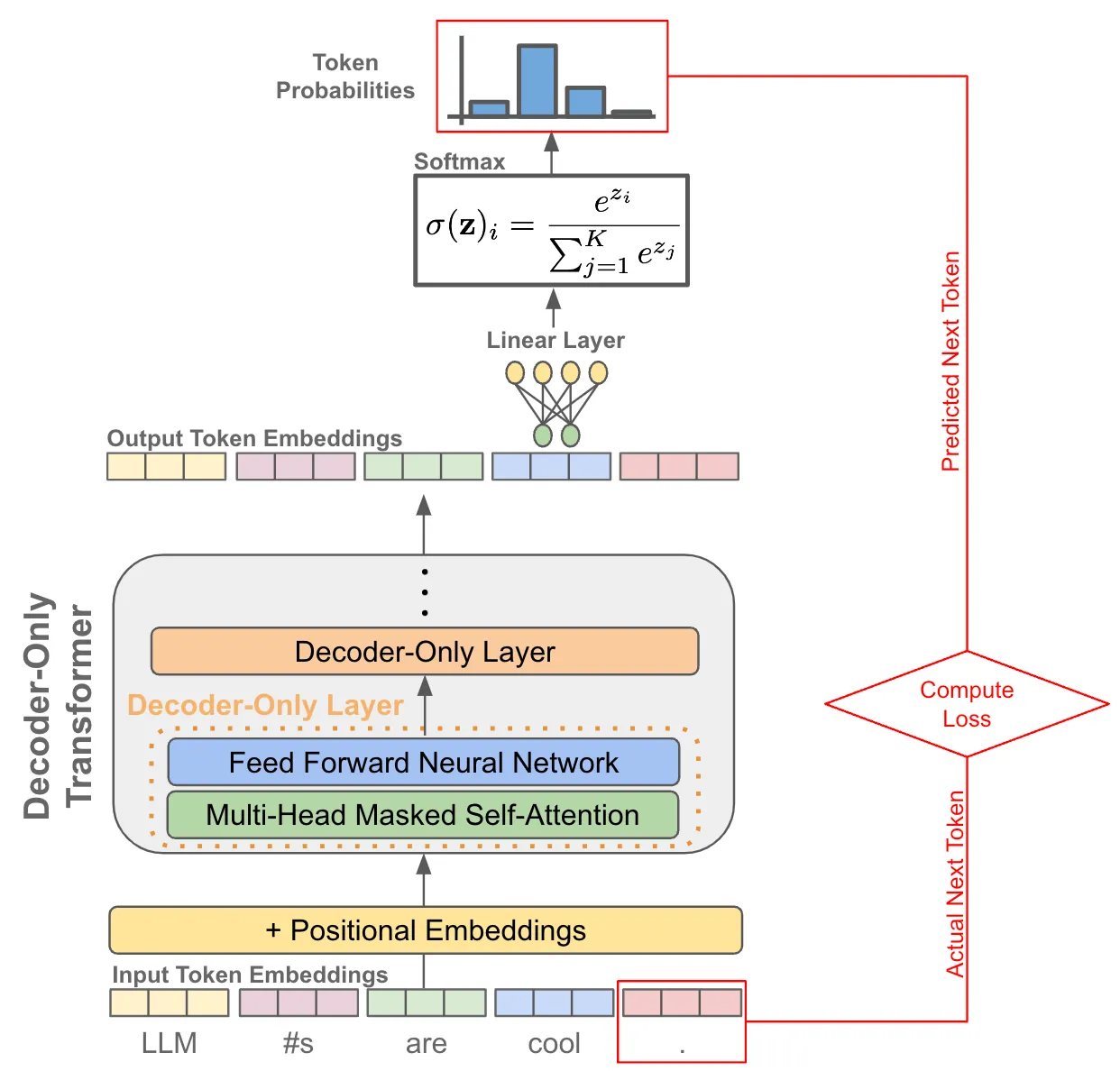
训练阶段:因为有causal自注意力的存在,我们可以一次性对一整个句子每个token进行下一个token的预测,并计算所有位置token的loss,因此只需要一forward
通过一个完整的例子来介绍一下这个过程,假设现在有一个用来预训练的数据集
你知道什么是预训练吗?假设经过分词后
你: 9
知道: 3
什么: 6
是: 4
预训练: 2
吗: 1
?: 5原来的数据变为如下序列,后面补了三个0(假设我们希望最大序列长度是10)
9 3 6 4 2 1 5 0 0 0预测下一个token就类似于9预测3,9 3预测6,以此类推,但是如果这样拆成很多个数据段其实比较低效,因此就可以考虑移位来构造数据,即
- 模型输入X为
9 3 6 4 2 1 5 0 0 0 - 模型输出targets为
3 6 4 2 1 5 0 0 0 0
这样就可以一次性把整条序列喂给模型,计算一次就包含了6个预测下一个token的损失了。
注意这里模型的设计是有讲究的,我们不能让输入看到后面的词(如果看得到的话就没必要进行预测了),也就是“你”在模型内看不到“知道”,“你 知道”在模型内看不到“什么”,这个可以通过注意力机制实现,不是本文的关注点,这里就不展开了。
现在模型的输入的维度为(1,10),第一维为batch_size,然后经过embedding层后变为(1,10,768),这里假设embedding的维度为768。
记住进入transfomer前后数据的维度不会发生变化,把transfomer当作一个黑盒,也就是transformer(X)的维度还是(1,10,768),接下来就是基于它来进行预测了,因为要预测哪个词,词的可能情况就是词表的大小,所以做的就是一个分类任务,预测下一个token是词表中的哪一个(词表中的每一个词当作一个类别)。
为了完成分类任务,需要对transformer的输出做一个映射,映射到跟词表一样大,也就需要定义这样一个线性变换
output_layer = nn.Linear(768, vocab_size, bias=False)
然后logits=output_layer(transformer(X))的维度就是(1,10,vocab_size),接下来就可以计算loss了,具体来说就是计算logits(模型预测)与targets(真实标签)之间的交叉熵损失,同时忽略了填充值对应的损失。
语言模型的的Supervised fine-tuning (SFT)阶段
“有监督微调”意味着使用有标签的数据来调整一个已预训练好的语言模型(LLM),使其更适应某一特定任务。通常LLM的预训练是无监督的,但微调过程往往是有监督的。
当进行有监督微调时,模型权重会根据与真实标签的差异进行调整。通过这个微调过程,模型能够捕捉到标签数据中特定于某一任务的模式和特点。使得模型更加精确,更好地适应某一特定任务。
以一个简单的例子来说,你有一个已经预训练好的LLM。当输入“我不能登录我的账号,我该怎么办?”时,它可能简单地回答:“尝试使用‘忘记密码’功能来重置你的密码。”
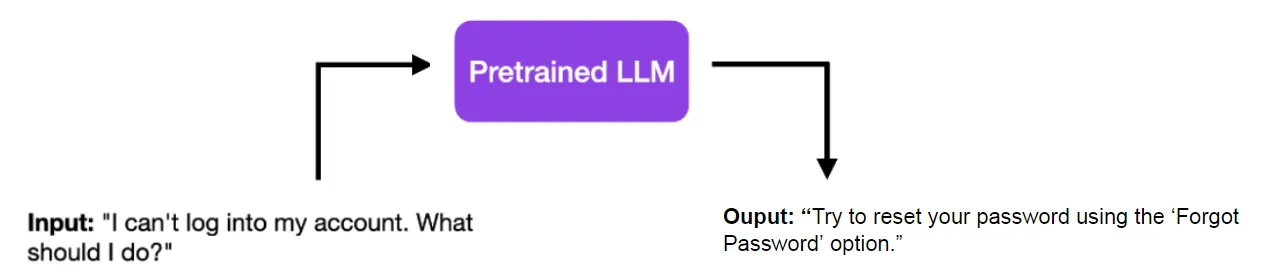
这个回答很直接,适用于一般问题,但如果是客服场景,可能就不太合适了。一个好的客服回答应该更有同情心,并且可能不会这么直接,甚至可能包含联系信息或其他细节。这时候,有监督微调就显得非常重要了。
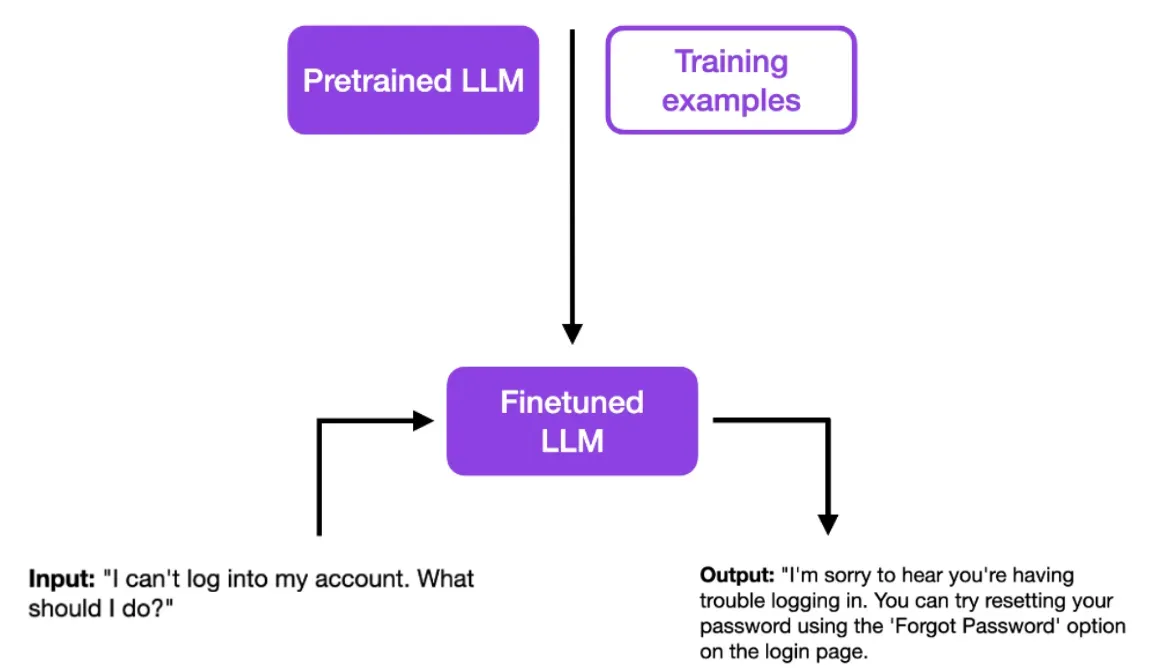
经过有监督微调后,你的模型可以提供更加符合特定指导原则的答案。例如,经过一系列专业的培训示例后,你的模型可以更有同情心地回答客服问题。
接下来我们还是从数据到模型输出,计算loss的步骤来看看SFT的实现原理。
首先还是来看看数据怎么构造,SFT的每一条样本一般由两部分组成,也就是prompt(instruction)+ answer,比如:
- prompt:
翻译以下句子: What is pretrain - answer:
什么是预训练
也就是我们要给模型提供一些类似于问答形式的答案来学习,有了前面预训练的经验后,SFT其实就很好理解的,它本质上也在做next token prediction,只是我们更希望模型关注answer部分的预测,这可以通过生成一个mask向量来屏蔽不希望计算loss的部分,下面就是数据构造的一个示意:做的事情就是拼接prompt和answer,并在answer两侧添加一个开始和结束的符号,算一下prompt/instruction的长度,以及后面需要pad的长度,然后生成一个mask向量,answer部分为1,其他部分为0。
input_id=prompt+[bos]+answer+[eos]
context_length = input_id.index(bos)
mask_position = context_length - 1
pad_len = max_length - len(input_id)
input_id = input_id + [pad] * pad_len
loss_mask = [0]*context_length+[1]*(len(input_id[mask_position+1:])) + [0]*pad_len
构造好输入后,token转为embedding,经过transformer的过程跟之前预训练完全一样,也就是我们又得到了一个维度是(1,10,vocab_size)的输出logits=output_layer(transformer(X)),进一步就可以计算answer部分的loss了,其实就是通过mask把不希望考虑的地方乘以0,保留answer部分loss。
loss = F.cross_entropy(logits.view(-1, logits.size(-1)), Y.view(-1), ignore_index=0,reduce=False)
loss_mask = loss_mask.view(-1)
loss = torch.sum(loss*loss_mask)/loss_mask.sum()有了loss,进行反向传播更新模型参数就OK啦。
Reference:Supervised Fine-tuning: customizing LLMs
语言模型的推理阶段
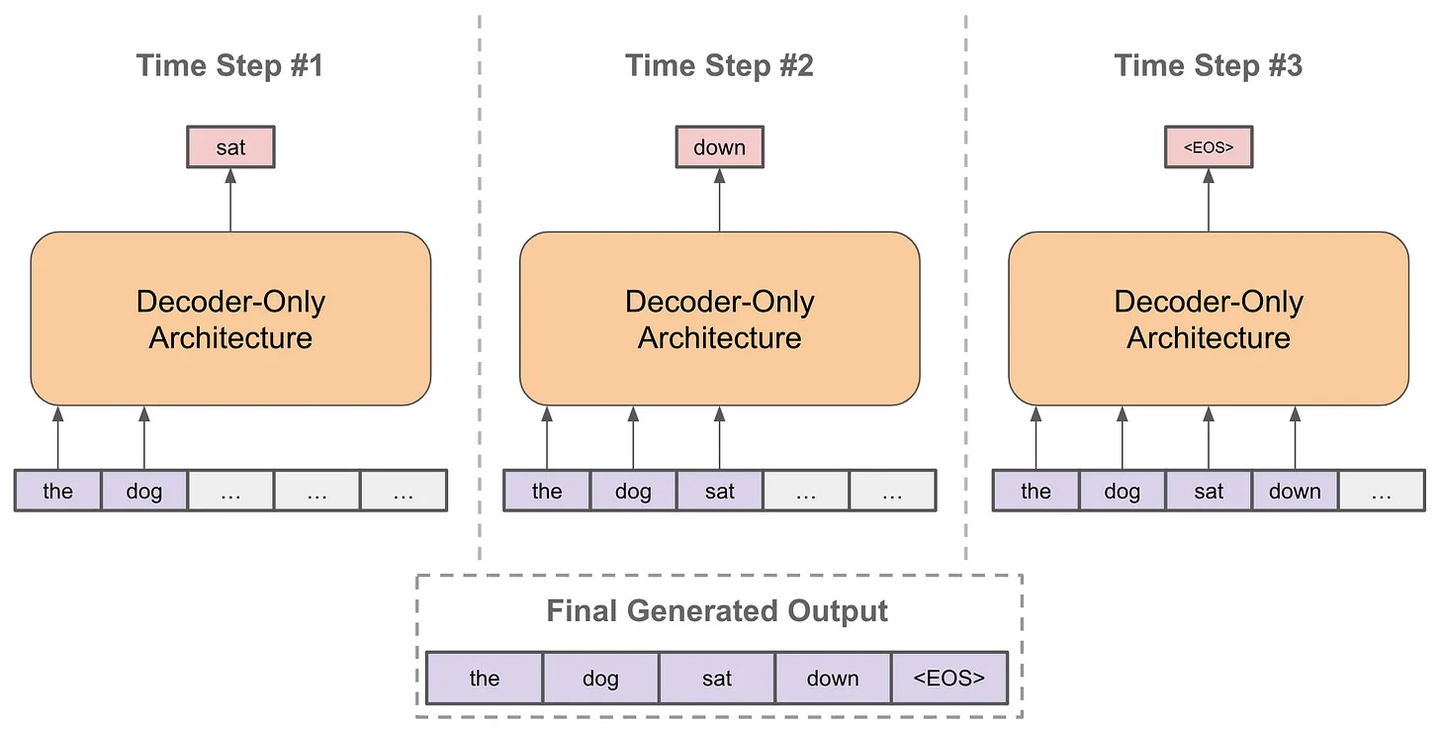
以自回归的方式进行预测
- 每次预测下一个token
- 将预测的token拼接到当前已经生成的句子上
- 再基于拼接后的句子进行预测下一个token
- 不断重复直到结束
其中,在预测下一个token时,每次我们都有一个概率分布用于采样,根据不同场景选择采样策略会略有不同,不然有贪婪策略、核采样、Top-k采样等,另外经常会看到Temperature这个概念,它是用来控制生成的随机性的,温度系数越小越稳定。
代码实现
下面代码来自项目https://github.com/karpathy/nanoGPT/tree/master,同样是一个很好的项目,推荐初学者可以看看。
对于各种基于Transformer的模型,它们都是由很多个Block堆起来的,每个Block主要有两个部分组成:
- Multi-headed Causal Self-Attention
- Feed-forward Neural Network
结构的示意图如下:
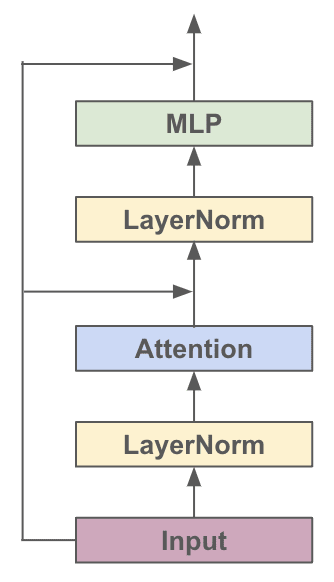
看图搭一下单个Block
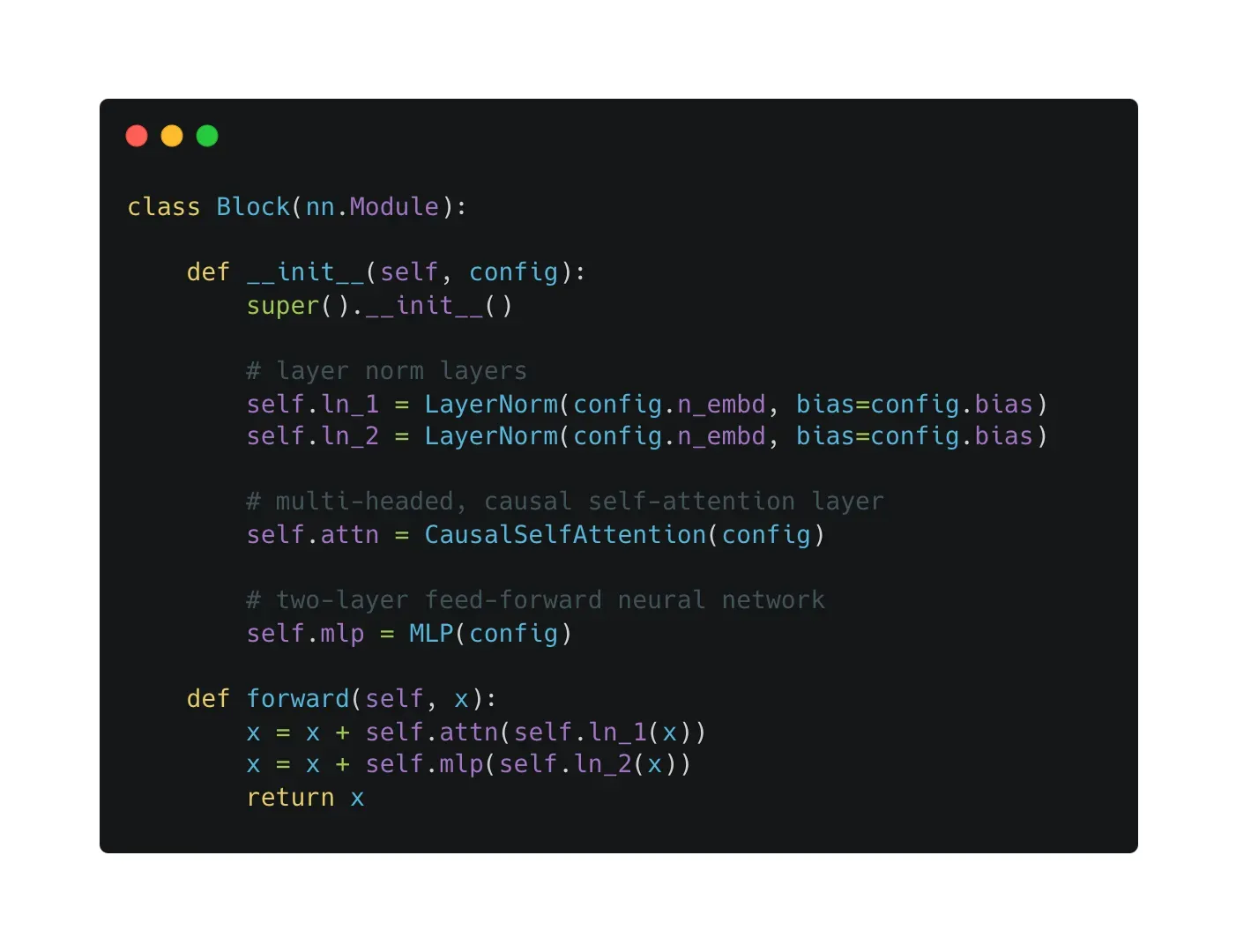
然后看下一整个GPT的结构

主要就是两个embedding层(token、位置)、多个block、一些额外的dropout和LayerNorm层,以及最后用来预测下一个token的线性层。说破了就是这么简单。
这边还用到了weight tying的技巧,就是最后一层用来分类的线性层的权重和token embedding层的权重共享。
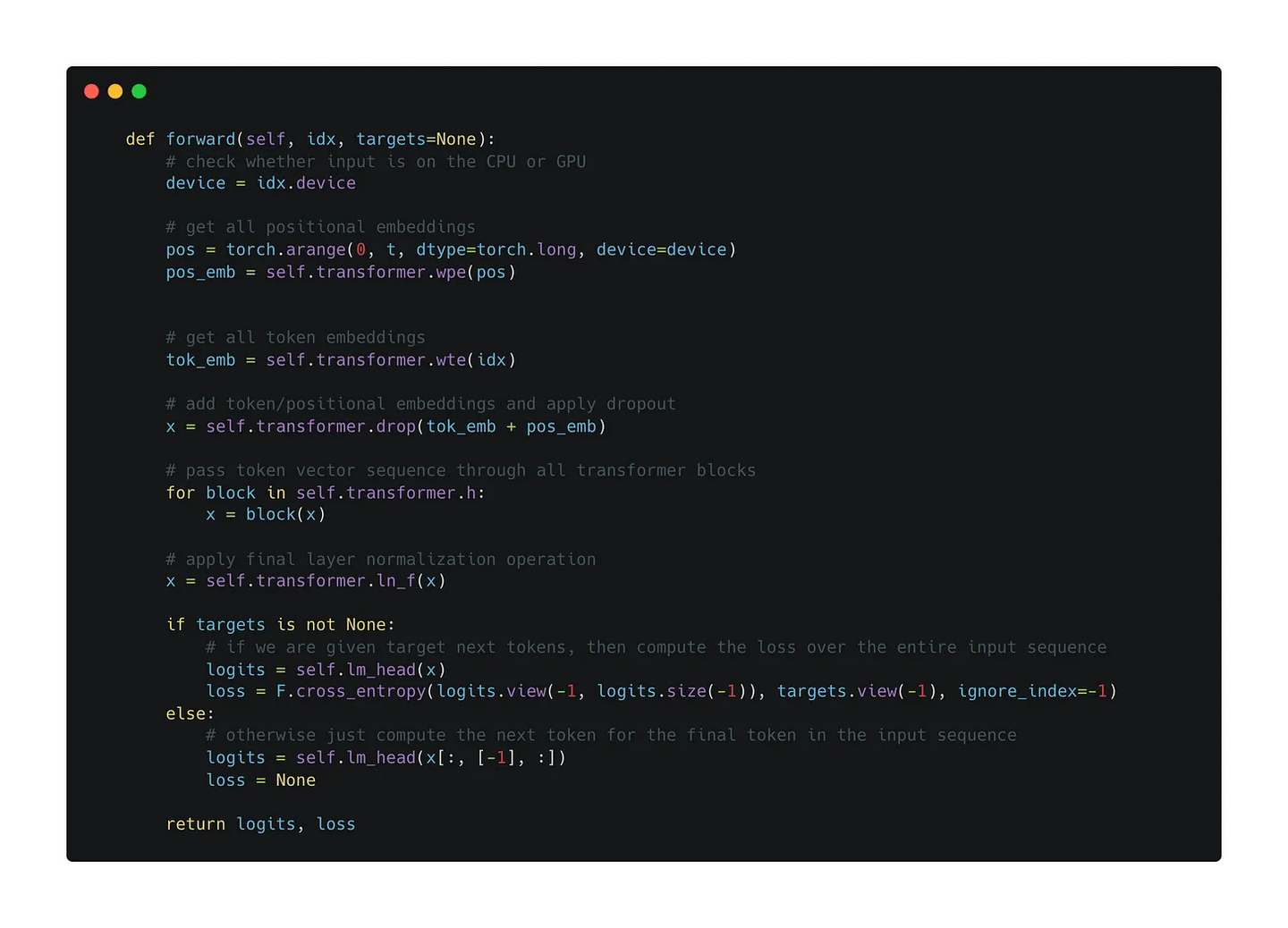
接下来重点来关注一下训练和推理的forward是如何进行的,这能帮助大家更好的理解原理。
首先需要构建token embedding和位置embedding,把它们叠加起来后过一个dropout,然后就可以送入transformer的block中了。
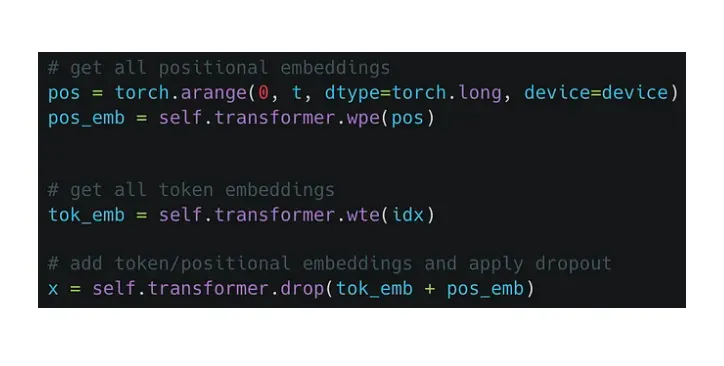
需要注意的是经过transforemr block后出来的tensor的维度跟之前是一样的。拿到每个token位置对应的输出embedding后,就可以通过最后的先行层进行分类,然后用交叉熵损失来进行优化。

再看一下完整的过程,其中只需要将输入左移一个位置就可以作为target了
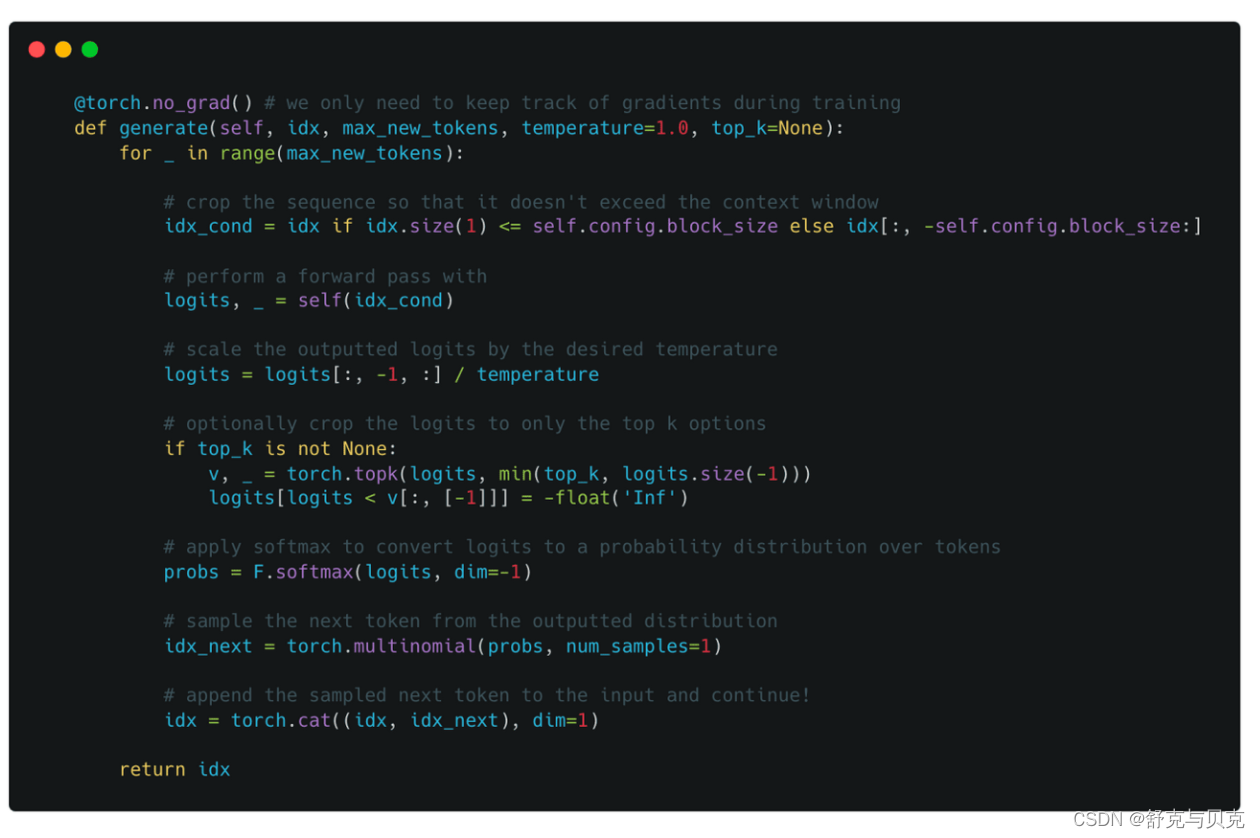
接下来看推理阶段:
- 根据当前输入序列进行一次前向传播
- 利用温度系数对输出概率分布进行调整
- 通过softmax进行归一化
- 从概率分布进行采样下一个token
- 拼接到当前句子并再进入下一轮循环
大模型基础|预训练|有监督微调SFT - 知乎 (zhihu.com)
从原理到代码理解语言模型训练和推理 - 知乎 (zhihu.com)
这篇关于[LLM] 大模型基础|预训练|有监督微调SFT | 推理的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





