本文主要是介绍execl多维度数据建模(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、建模过程
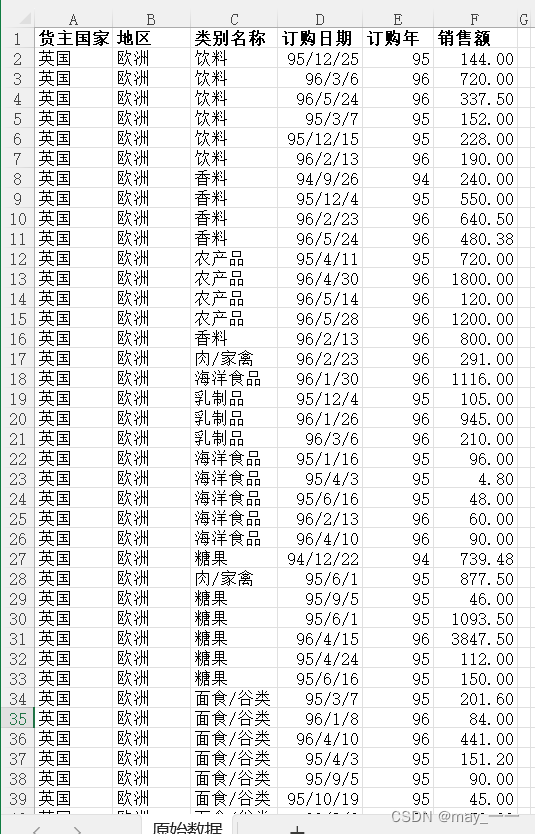
(1)打开原始数据表
原始数据如下:
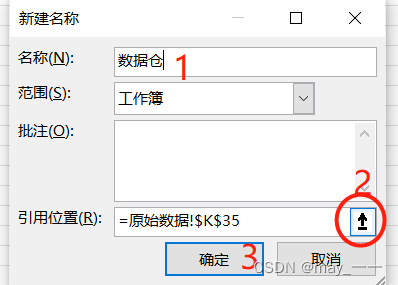
(2)公式--名称管理器--新建--定义名称:
a.输入“名称”
b.应用位置:手动选择数据(数据包含第一行的标签名)
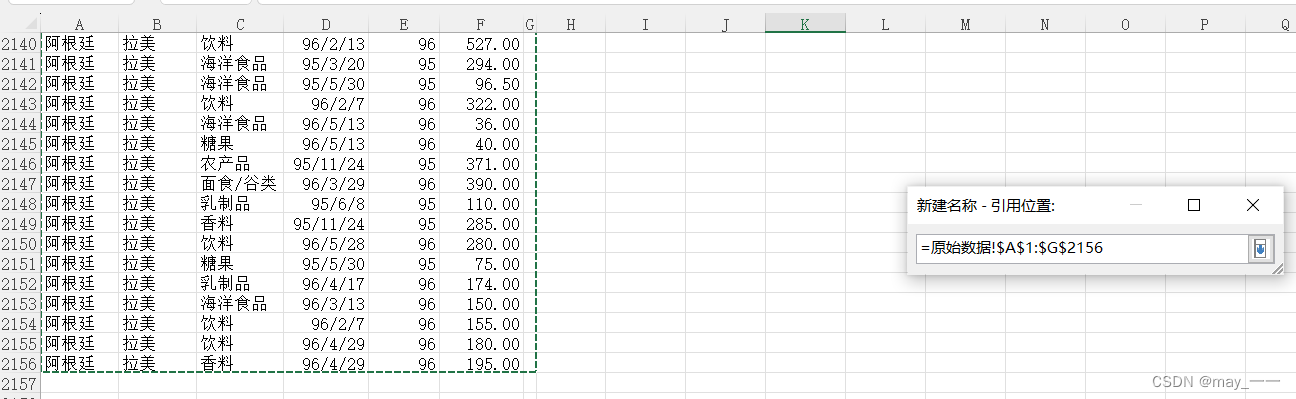
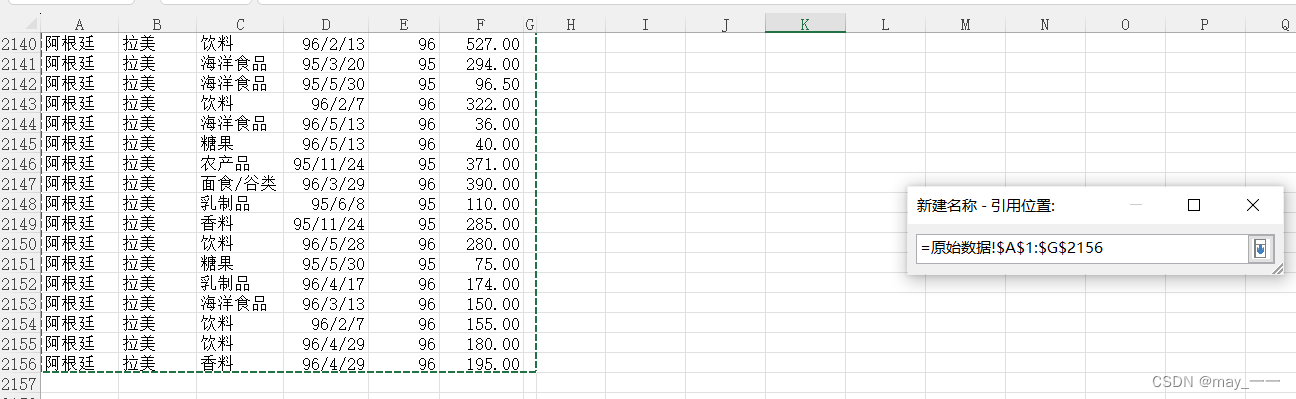
结果如下:
 (3)新增工作表,命名为“控制”
(3)新增工作表,命名为“控制”
(4)制作“地区”数据区,制作“产品类别”数据区(使用数据透视表或者手动输入也行)
使用数据表:在“原始数据表”中,点击某个数据后,点击“插入”--“数据透视表”--“新工作表”--“确定”

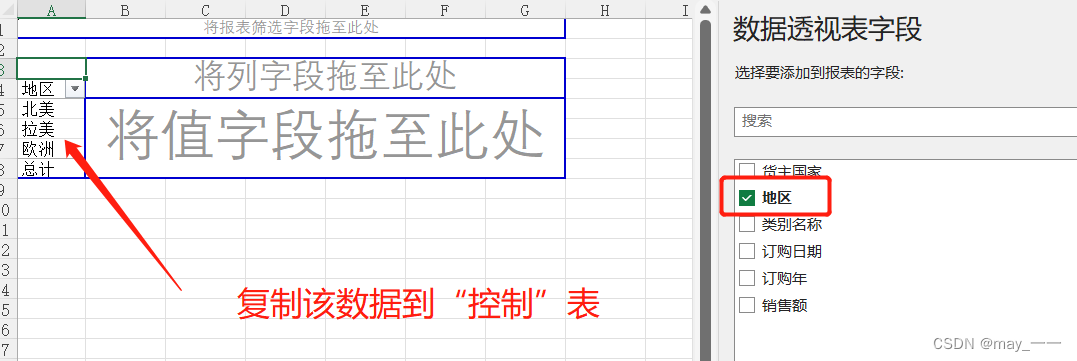
同理,复制“类别名称”
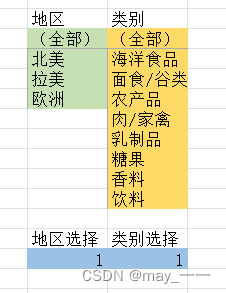
(5)制作“地区”维度单元格,和“类别名称”维度单元格。单元格中的初始数据为1(对应数据区中的全部数据)
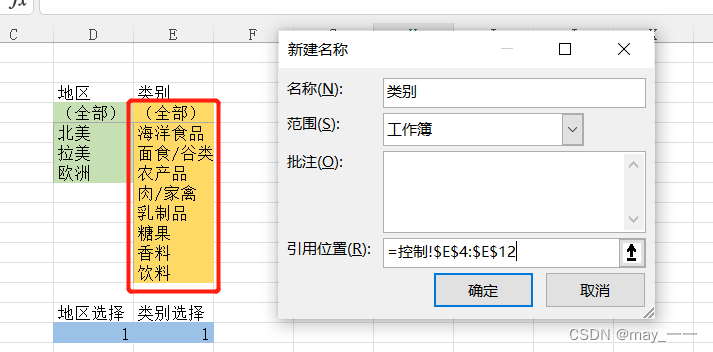
(6) 定义名称(公式--定义名称),分别定义“地区”“类别”“地区选择”“类别选择”4个名称
(记得“应用位置”不要选择第一行的标签名,和数据仓的不一样)例如:选择“类别”的应用位置是从“(全部)”到“饮料”
设置后查看名称管理器

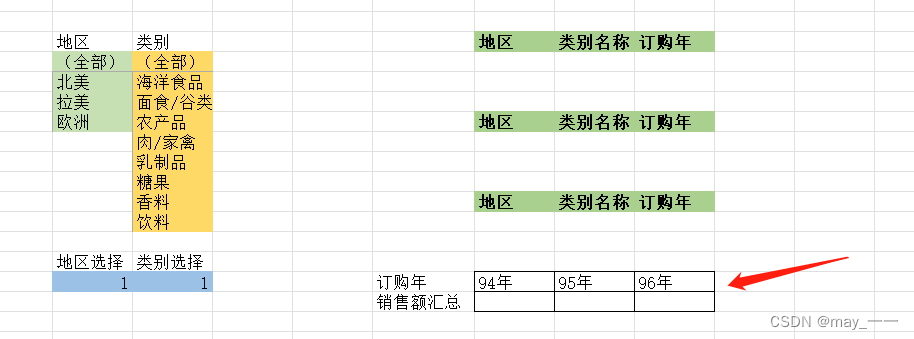
(7)选择三个区域,每个区域手工输入“地区 ”、“类别名称 ”、“订购年 ”三列。
(注意这三 列的名称要同“数据仓 ”中列名称一致,否则 DSUM 函数不能进行识别。

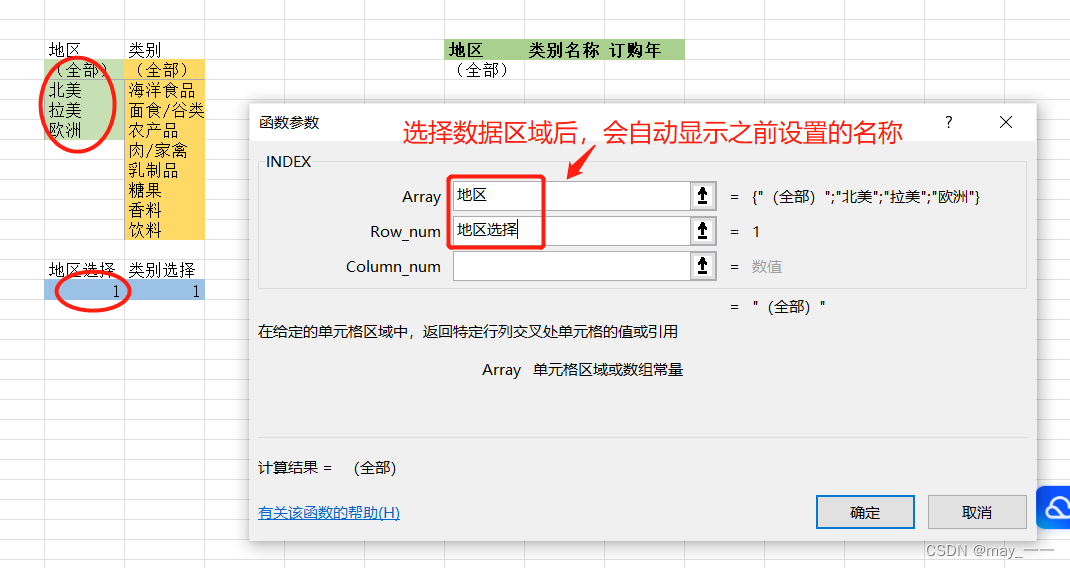
(8) 在第 7 步创建的“地区 ”和“类别名称 ”对应列插入“index” 函数,引用“地区选择 ”和“类别选择 ”控制单元格 返回的数据值。
(注意,当控制单元格=1 时返回的 值为(全部)时,显示为空)
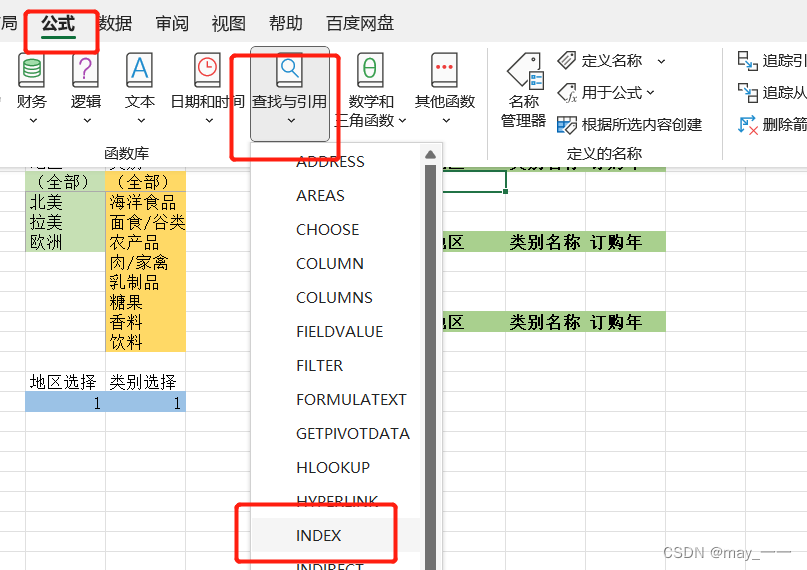


当地区选择为“1”是,会显示全部,现在要让1显示为空
公式为 “=IF(地区选择=1,"",INDEX(地区,地区选择)) ”,注意公式中的“地区 选择 ”,“地区 ”等都是之前定义好的名称,所以不会以单元格地址的形式出现了。
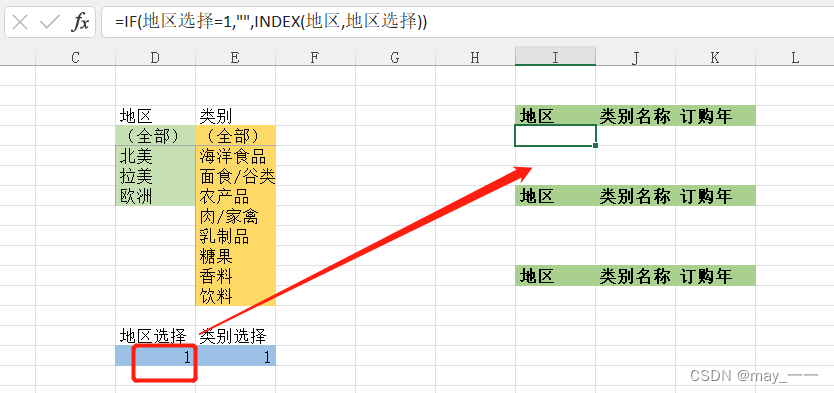
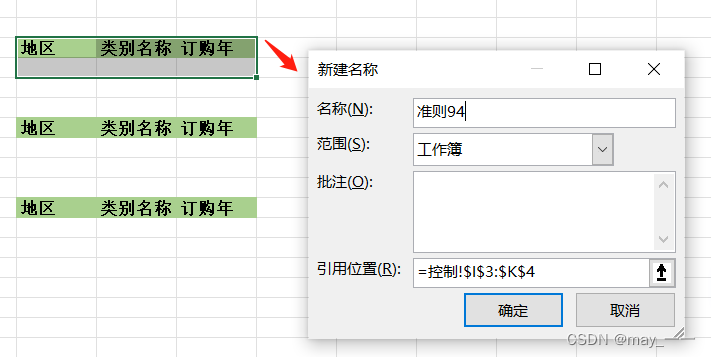
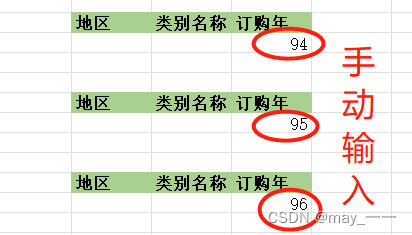
(9) 再次点击“定义名称 ”,将第(8) 的三个区域分别定义为“准则 94 ”、“准则 95 ”、 “准则 96 ”。
这 3 个名称同“数据仓 ”一样,引用位置包含行标签和数值行,见框住的部分(2 行 3 列)。
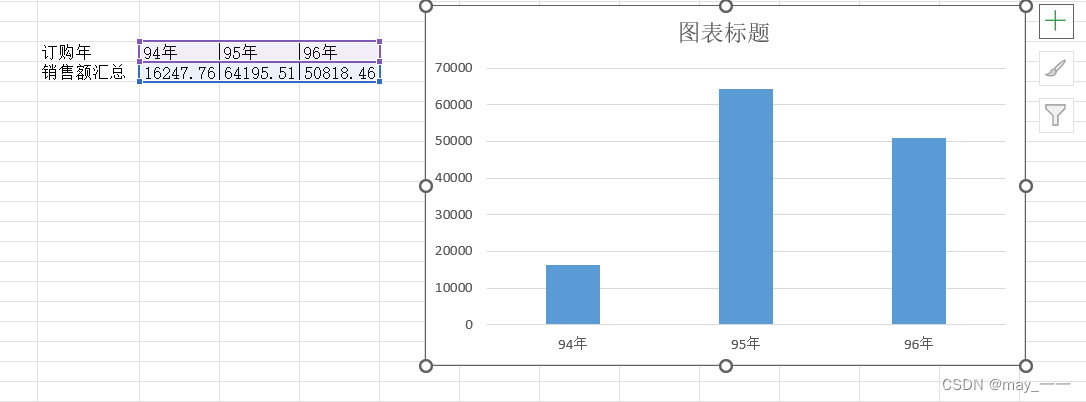
(10) 选择一个 2 行 3 列的区域作为数据汇总区,分别是 94 年、95 年、96 年。
订购年手动输入。
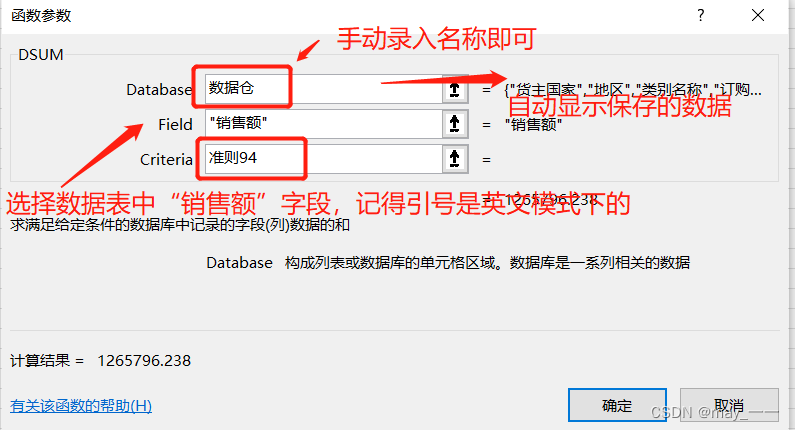
(11)在“94 年 ”下方插入 DSUM() 函数,
见下图。以此类推插入 95 年和 96 年的,分别对应“准则 95 ”和“准则 96 ”。

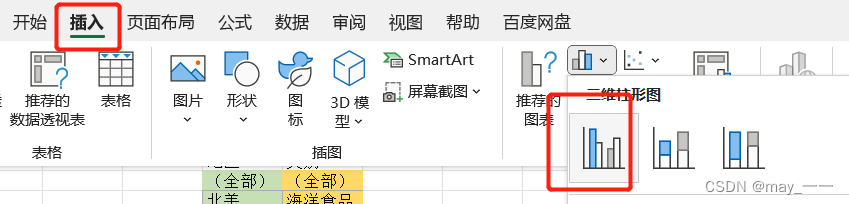
(12)选择数据汇总区数据,制作柱形图。
(选择数据--插入--柱形图)

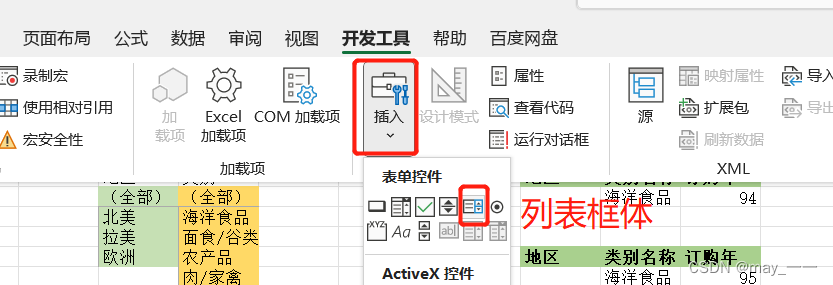
(13) 制作地区列表框
(注意:数据源区和单元格链接是之前定义好的名称,所以不会出现 单元格地址信息)
a. 先打开开发工具(文件--更多--自定义功能区--开发工具)
b. 插入列表框
c. 选择列表框--右键--设置控件格式--设置
 确定后效果如下:
确定后效果如下:

2.整体效果如下:
当1.2部分的选择改变时,3,4,5,6部分的数据都会联动改变

这篇关于execl多维度数据建模(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





