本文主要是介绍关于使用中加 前/后简历二叉树,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
中加后
unordered_map<int, int> pos;TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {int n = inorder.size();for (int i = 0; i < n; i++) {pos[inorder[i]] = i; //记录中序遍历的根节点位置}return dfs(inorder, postorder, 0, n - 1, 0, n - 1);}TreeNode* dfs(vector<int>& inorder, vector<int>& postorder, int il, int ir, int pl, int pr) {if (il > ir) return nullptr;int k = pos[postorder[pr]]; //中序遍历根节点位置TreeNode* root = new TreeNode(postorder[pr]); //创建根节点root->left = dfs(inorder, postorder, il, k - 1, pl, pl + k - 1 - il);root->right = dfs(inorder, postorder, k + 1, ir, pl + k - 1 - il + 1, pr - 1);return root;}根据二叉树的性质,我们可以依次采取下述步骤:
1、先利用后序遍历找根节点:后序遍历的最后一个数,就是根节点的值;
2、在中序遍历中找到根节点的位置 k,则 k 左边是左子树的中序遍历,右边是右子树的中序遍历;
3、假设il,ir对应子树中序遍历区间的左右端点, pl,pr对应子树后序遍历区间的左右端点。那么左子树的中序遍历的区间为 [il, k - 1],右子树的中序遍历的区间为[k + 1, ir];
4、由步骤3可知左子树中序遍历的长度为k - 1 - il + 1,由于一棵树的中序遍历和后序遍历的长度相等,因此后序遍历的长度也为k - 1 - il + 1。这样,根据后序遍历的长度,我们可以推导出左子树后序遍历的区间为[pl, pl + k - 1 - il],右子树的后序遍历的区间为[pl + k - 1 - il + 1, pr - 1];
仅凭文字可能不太好理解上述推导过程,我们画张图来辅助理解:
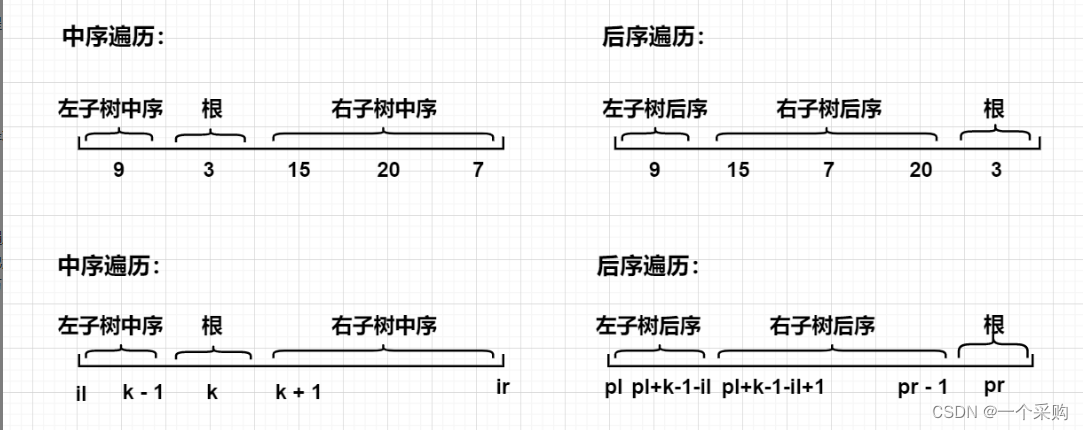
左右子树中序和后序遍历的边界确定是这道题最大的难点,理解了这点,这道题也就做完了一大半。
如何在中序遍历中对根节点快速定位?
具体过程如下:
1、创建一个哈希表pos记录记录每个值在中序遍历中的位置。
2、先利用后序遍历找根节点:后序遍历的最后一个数,就是根节点的值;
3、确定左右子树的后序遍历和中序遍历,先递归创建出左右子树,然后创建根节点;
4、最后将根节点的左右指针指向两棵子树;
同理 前加中
class Solution {
public:unordered_map<int, int> pos;TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {int n = inorder.size();for (int i = 0; i < n; i++) {pos[inorder[i]] = i; //记录中序遍历的根节点位置}//return dfs(inorder, postorder, 0, n - 1, 0, n - 1);return pfs(preorder, inorder, 0, n - 1, 0, n - 1);}TreeNode* pfs(vector<int>& preorder, vector<int>& inorder, int il, int ir, int pl, int pr) {if (il > ir || pl > pr ) return nullptr;int k = pos[preorder[pl]]; //中序遍历根节点位置TreeNode* root = new TreeNode(preorder[pl]); //创建根节点root->left = pfs(preorder, inorder, il, k - 1, pl + 1, k - il + pl);root->right = pfs(preorder, inorder, k + 1, ir, pr + 1 - ir + k, pr);return root;}
};这篇关于关于使用中加 前/后简历二叉树的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






