本文主要是介绍2.亿级积分数据分库分表:增量数据同步之代码双写,为什么没用Canal?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.亿级积分数据分库分表:总体方案设计 上一篇博客中写了一下积分数据分库分表的总体方案设计,里面说了采用应用程序代码双写的方式实现的增量数据同步,本篇就对这一块进行一些细化的介绍,包括:
为什么不用Canal监听数据库binlog,有哪些优缺点吗?
为什么要用代码双写,有哪些优缺点吗?代码双写怎么实现的?
Canal监听binlog
实现流程
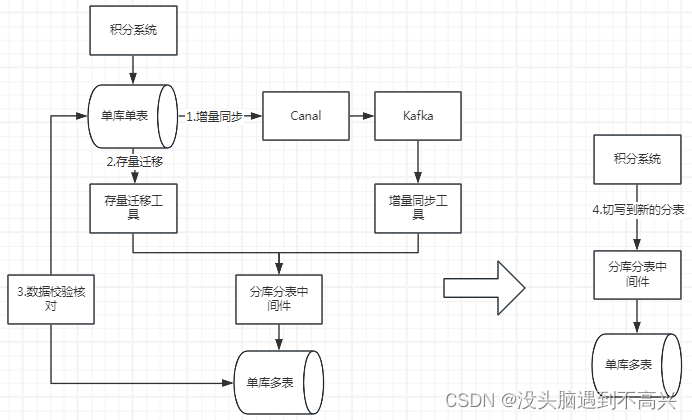
Canal监听binlog的方案大致流程如下图所示:
- 对原有老的单表添加Canal监听,老表的增删改操作会产生binlog,通过Canal将binlog转发到kafka,消费kafka的消息将增量的数据通过分库分表中间件写的新的分表中
- 对老的单表的创建时间在Canal监听时间点之前的数据全量迁移到新的分表
- 数据核对校验新老表的数据;灰度切流验证,这一步没有画出来
- 在运行一段时间后,发现没有什么数据不一致了,并且增量数据同步追上了老表数据,就可以将程序的写切到新分表了
上面说了要增量数据同步追上老表数据,但是因为应用程序一直在产生新的写操作导致一直有新的binlog产生,导致只能无限逼近老的数据而无法追平,所以在第4步切写分表之前要将老表先短暂停写一小段时间,等binlog消费完就可以切写了。
优缺点
优点:
-
功能逻辑实现简单
缺点:
- 数据增量同步有短暂的秒级延迟;
- 切写分表的时候要停写,对业务有影响;
- 积分应用程序代码没有通过分库分表中间件做过写入操作,直接切写分表有很大的风险
- 引入了新的Canal中间件,提升了复杂性
正是因为考虑到使用Canal做增量数据同步需要短暂停写,对业务有影响,还有就是切写分表的风险,所以我们这边才没有使用Canal,而是采用了代码双写。
代码双写
实现流程
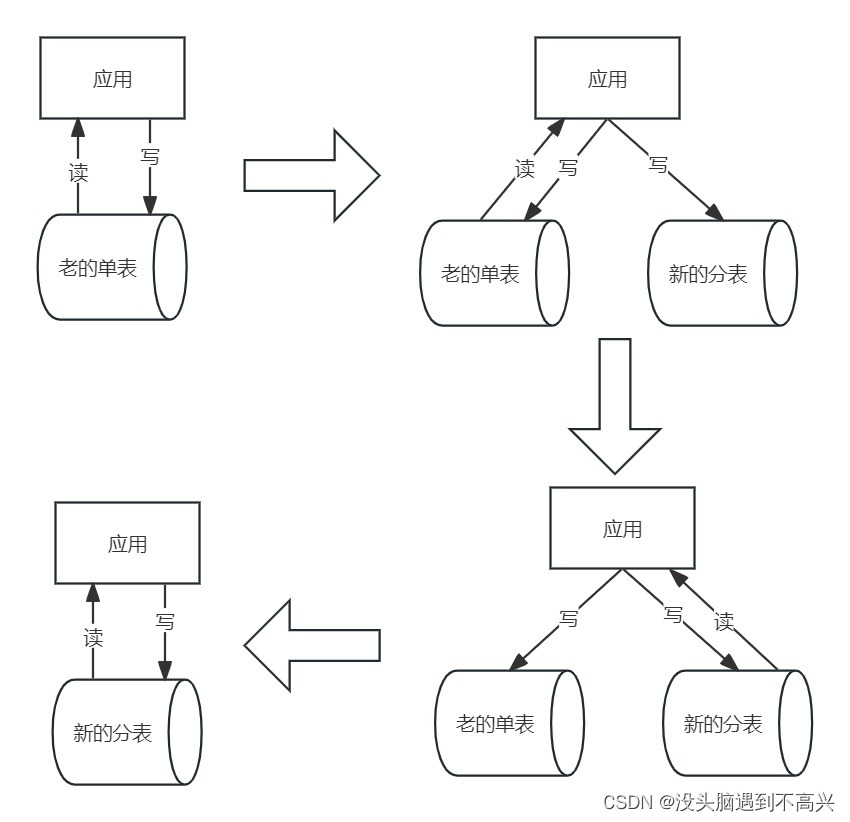
上一篇博客中关于双写有如下的操作步骤
- 改造双写代码预发测试(多种case跑一下,双写开关等校验),没问题发布上线,上线时双写开关默认关闭,可以通过配置中心动态开启,打开双写开关(新表写入失败先忽略,因为更新和删除操作会因为新表数据不存在而失败),记录双写开始时间点A
- 将老表的积分明细的createTime小于等于双写开始时间点A+5分钟(防止时间不同步导致少迁移数据,预留一些缓冲时间)的数据进行全量迁移到分表
- 新老数据全量数据校验,查看数据是否一致;同时定时任务每隔一小段时间进行增量校验,增量数据因为读取新老数据存在短暂时间差可能会瞬时不一致,这种数据隔一段时间再次校验,多次校验还不一致的数据进行数据订正(老表数据覆盖到新表数据)
- 改造代码,添加双读的逻辑上线(读新表的开关默认关闭)
- 低流量节点(凌晨过后)进行白名单、灰度切流userId%10000,进行验证,逐步流量打开,持续观察
- 双写开关切到新表,保证只写新表(也可以继续写老表一段时间,或者创建一个新表往老表同步的canal任务,方便回滚),完成数据迁移方案
- 系统稳定运行一段时间,迁移&双写代码下线,老表进行资源释放
优缺点
优点:
- 增量数据同步延迟比较低
- 切换写新的积分多表时可以直接切换,无需停写
- 积分应用程序代码通过分库分表中间件做过各种增删改查操作,各种条件case都跑过,后面切写分表就没有风险了
缺点:
- 双写逻辑实现起来相对复杂一些
具体实现
双写改造点:增、删、改
双写开关有两个(通过配置中心实时切换):
- 写老表开关:默认开启,新表写入没有问题时可以进行关闭,也可以继续写一段时间老表
- 写新表开关:默认关闭,需要开启时打开
新老表的开关同时打开时,表示要进行双写
通过配置中心动态进行切换,双写期间需要注意的问题如下:
- 对写新表操作需要记录日志
- 新表不要求一定写成功(不影响服务,记录错误日志告警通知等,有数据校验订正任务兜底)
程序双写的逻辑,可以通过对mapper接口添加AOP切面,拦截到需要分表的mapper的写方法,判断需要双写的时候切换数据源双写到新的分表中,通过这种方式,可以对原有代码基本上实现零侵入。
AOP切面代码大致如下所示:
@Aspect
@Component
@Slf4j
public class DoubleWriteMapperAop {Set<String> shardMapperSet = Sets.newHashSet(PointInfoMapper.class.getSimpleName());@Around("execution(* com.wkp.sharding.mapper.*.*(..))")public Object doAroundMapper(ProceedingJoinPoint proceedingJoinPoint) throws Throwable {MethodSignature signature = (MethodSignature) proceedingJoinPoint.getSignature();Method method = signature.getMethod();String clazzName = method.getDeclaringClass().getSimpleName();//不用分表的mapper不用特殊处理直接返回if (!shardMapperSet.contains(clazzName)) {return proceedingJoinPoint.proceed();}//双写前和双写时这里写的老表,最后切到写分表时这里写的分表Object result = proceedingJoinPoint.proceed();//获取当前mapper的方法上有没有加分片写的注解ShardWrite shardWrite = method.getAnnotation(ShardWrite.class);//是写方法 && threadlocal里面获取到了需要双写的标识if (shardWrite != null && DoubleWriteThreadLocal.needDoubleWrite()) {//切数据源,写分表,这里执行双写逻辑 proceedingJoinPoint.proceed();}return result;}
}DoubleWriteThreadLocal.needDoubleWrite(),DoubleWriteThreadLocal是个ThreadLocal,里面获取到是否需要双写的标识,这个ThreadLocal的值是前面通过配置中心判断是否双写开关开着,如果开着双写会将ThreadLocal的双写标识设置为true。
AOP切面这里通过ThreadLocal判断,而没有通过读取配置中心,原因是可能前面配置中心打开了双写,但是执行到切面时恰好配置中心将开关从双写切到写分表了,那么这里就不会双写分表了,分表就会丢失一条数据。
后面切写的时候直接通过配置中心切换开关,即可动态切换只写到分表中。
这篇关于2.亿级积分数据分库分表:增量数据同步之代码双写,为什么没用Canal?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





