本文主要是介绍源于一区| 改善性能的5种高效而小众的变异策略,一键调用 (Matlab),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
基于群体的优化算法在达到迭代后期时种群多样性往往会速降,进化将陷入停滞,而许多算法本身并没有突变机制,一旦受到局部最优值的约束,就很难摆脱这些约束。它还将减少种群多样性,减缓收敛速度。
变异策略可以增加种群的多样性,防止算法陷入局部最优。因此为克服算法易陷入局部最优的局限性,本文复现了一区期刊Knowledge-Based Systems中的五篇文章的变异策略,并将其分别应用于蜣螂优化算法中,结果表明,引入了这些变异策略后,算法能够有效避免陷入局部最优的困境,算法性能得到了提升。
00 目录
1 各“变异”策略简介
2 代码目录
3 算法性能
4 源码获取
01 各“变异”策略简介
1.1 多尺度协同变异
变异尺度对算法的搜索与收敛性能都有影响,若变异尺度过大,则可能越过极值点,若变异尺度过小,则需要大量迭代以实现空间的遍历,因此引入不同尺度的高斯变异算子能够有利于搜索全局最优,加快收敛。
多尺度协同变异即是本文的第一个变异策略。
1.2 正态云模型
在众多的不确定性中,随机性和模糊性无疑是最常见的属性。为了克服处理不确定性的不足,文献[1]提出了云模型来实现定量描述与定性概念之间的不确定性转换。云模型的特征在于3个数学参数:期望(Ex)、熵(En)和超熵(He)。由云模型的理论可知,数字特征中的期望Ex表示搜索范围的中心位置,熵En表示搜索范围,En越大,云滴的水平覆盖范围越大,超熵He表示云滴的离散程度,其示意图如下:
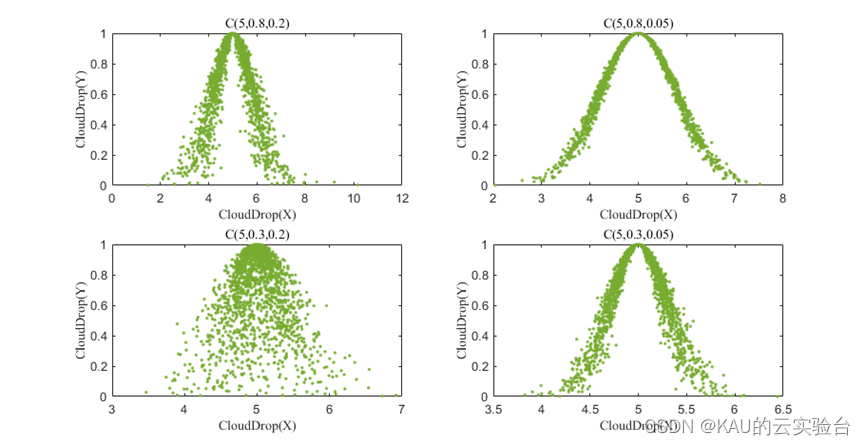
因此,引入正态云模型作为本文的第二个变异策略,通过对正态云模型的期望值、熵、超熵的设置对其解所在位置进行开发。
1.3 融合高斯突变与布谷鸟的变异
高斯变异使用服从正态分布的随机数作用于原始位置向量,从而生成新的位置,能够对当前位置进行小范围的邻域搜索,同时两个随机个体的引入融合为新的高斯算子,使其包含一定的种群信息,将布谷鸟搜索机制引入与高斯算子结合,也增加了搜索效率。
融合高斯突变与布谷鸟的变异是本文的第三个变异策略。
1.4 镜面反射学习变异
镜面反射是一种非常常见的物理现象:光从具有光泽表面的物体上反射。如下:

该策略和反向学习有一点相似性,实际上,反向学习就是镜面反向学习的一种特殊情况,通过这种策略能够有效丰富种群的多样性。
镜面反射学习变异是本文的第四个变异策略。
1.5 平滑开发变异
包含无序维数采样、随机交叉与顺序变异,这三种机制能够相互补充,提高算法的搜索能力。
平滑开发变异是本文的第五个变异策略。
02 代码目录
文件说明:

代码为MATLAB,。考虑到很多同学获取代码后,MATLAB代码部分有乱码(MATLAB版本问题),有几个方法:
①可以将MATLAB版本改为2020及以上;
②将m文件用记事本打开,再将记事本中的代码复制到Matlab即可
代码都经过作者注释,代码清爽,可读性强。
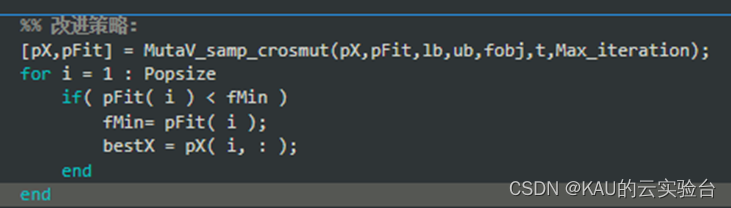
改进策略只需一行代码即可实现调用
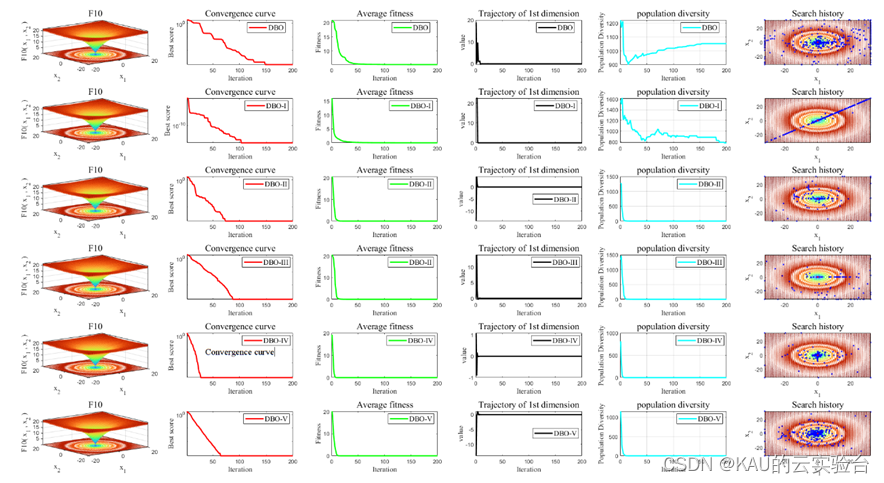
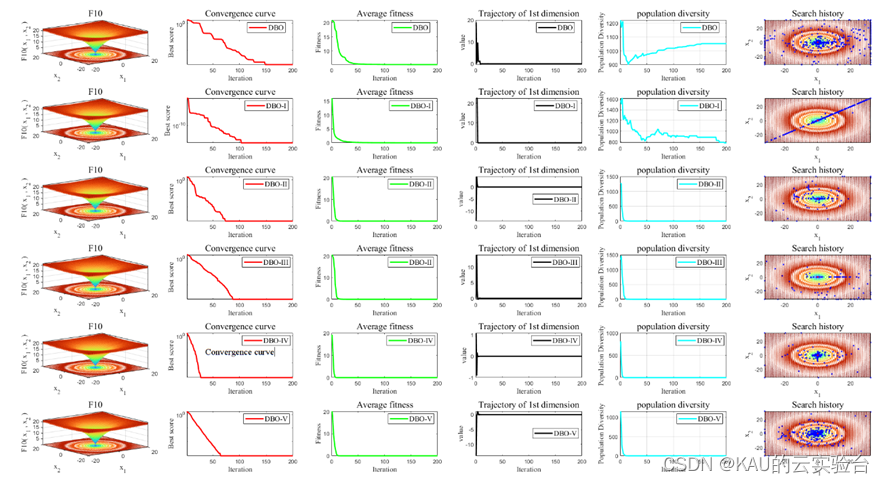
03 算法性能
采用标准测试函数检验其引入变异策略后算法的性能 (部分)
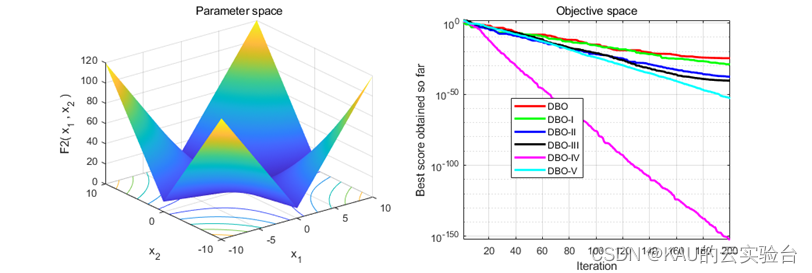
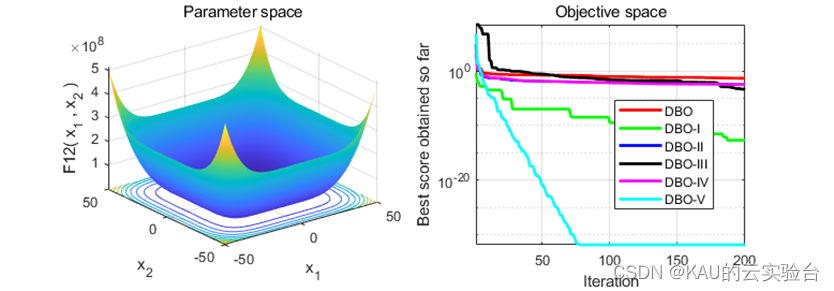
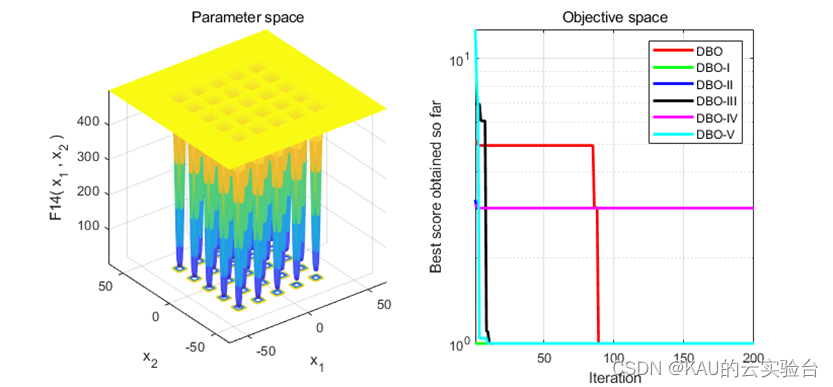
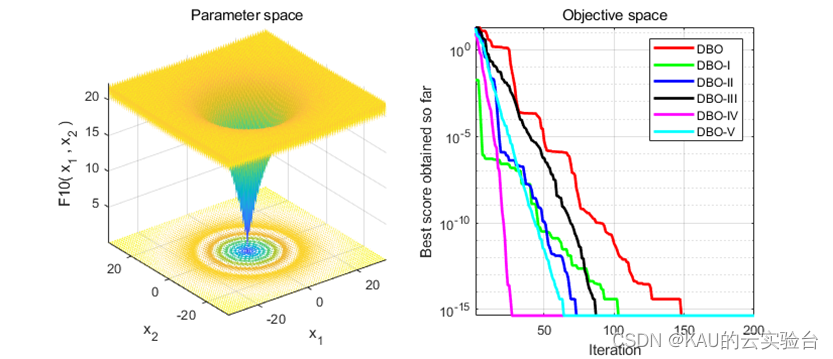
04 源码获取
在公众号(KAU的云实验台)后台回复 BY1
参考文献
[1]Li D Y, Meng H J, Shi X M. Membership clouds and membership cloud generators[J]. Journal of Computer Research and Development, 1995,32( 6) : 15-20.
这篇关于源于一区| 改善性能的5种高效而小众的变异策略,一键调用 (Matlab)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



