本文主要是介绍PGSQL中按照周维度汇总数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在网上看到多种写法,但是最后汇总出来的数据计算方法有差异,周日为周一,不满足条件。
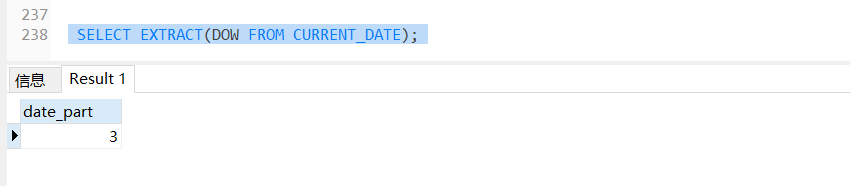
SELECT EXTRACT(DOW FROM CURRENT_DATE);
这个sql查询的时候一周中的第几天 我执行的时候是2020年7月1号所以为第三天,
在这个基础上可以返回不同想要的时间如下,
1-7分别是周一到周日这是换算成国内的写法,但是其实际还是安装国际周来统计,即周日为周一。
SELECT CURRENT_DATE-(EXTRACT(DOW FROM CURRENT_DATE)-1||‘day‘)::interval diffday;
其中当换成这个写法则是按照周进行分组汇总其中当我的查询时间为7号到14号时实际汇总数据就会有差异,实际为7到13号的数据汇总,这是因为默认把7号当周一计算了,当查询条件为8到14则是正常周数据汇总金额。
SELECT SUM(
f_value
) AS "f_produce_value",
SUBSTR( to_date ( SUBSTR( '20200607', 1, 8 ), 'yyyyMMdd' )::DATE - ( extract ( dow FROM to_date ( SUBSTR( '20200614', 1, 8 ), 'yyyyMMdd' )::TIMESTAMP ) - 7 || 'day' ) :: INTERVAL ,1,10) week
from t_integral_analysis WHERE
1=1
AND f_statistics_time BETWEEN '20200607'
AND '20200614'
GROUP BY week

下面就需要改造下,把对应的时间时间进行转换
SELECT
f_statistics_time , -- 当前时间
cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int), -- 获取第几天
to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE - cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int) + 7 week, -- 获取周日期
case cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int) when 0 then to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE else to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE - cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int) + 7 end -- 转换之后日期,若为周日则增加7天换算
from t_integral_analysis WHERE
1=1
AND f_statistics_time BETWEEN '20200607'
AND '20200614'

SELECT SUM(
f_value
) AS "f_produce_value",
SUBSTR( case cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int) when 0 then to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE else to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE - cast(extract(dow from to_date ( SUBSTR( f_statistics_time, 1, 8 ), 'yyyyMMdd' )::DATE) as int) + 7 end ,1,10) as week
from t_integral_analysis WHERE 1=1
AND f_statistics_time BETWEEN '20200607'
AND '20200614'
GROUP BY week
当最后把sql这样转换后变成这样则统计的总数据不会遗漏。
这篇关于PGSQL中按照周维度汇总数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





