本文主要是介绍图解缓存淘汰算法 LRU、LFU | 最近最少使用、最不经常使用算法 | go语言实现,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在前面
无论是什么系统,在研发的过程中不可避免的会使用到缓存,而缓存一般来说我们不会永久存储,但是缓存的内容是有限的,那么我们如何在有限的内存空间中,尽可能的保留有效的缓存信息呢? 那么我们就可以使用 LRU/LFU算法 ,来维持缓存中的信息的时效性。
LRU 详解
原理
LRU (Least Recently Used:最近最少使用)算法在缓存写满的时候,会根据所有数据的访问记录,淘汰掉未来被访问几率最低的数据。也就是说该算法认为,最近被访问过的数据,在将来被访问的几率最大。
流程如下:
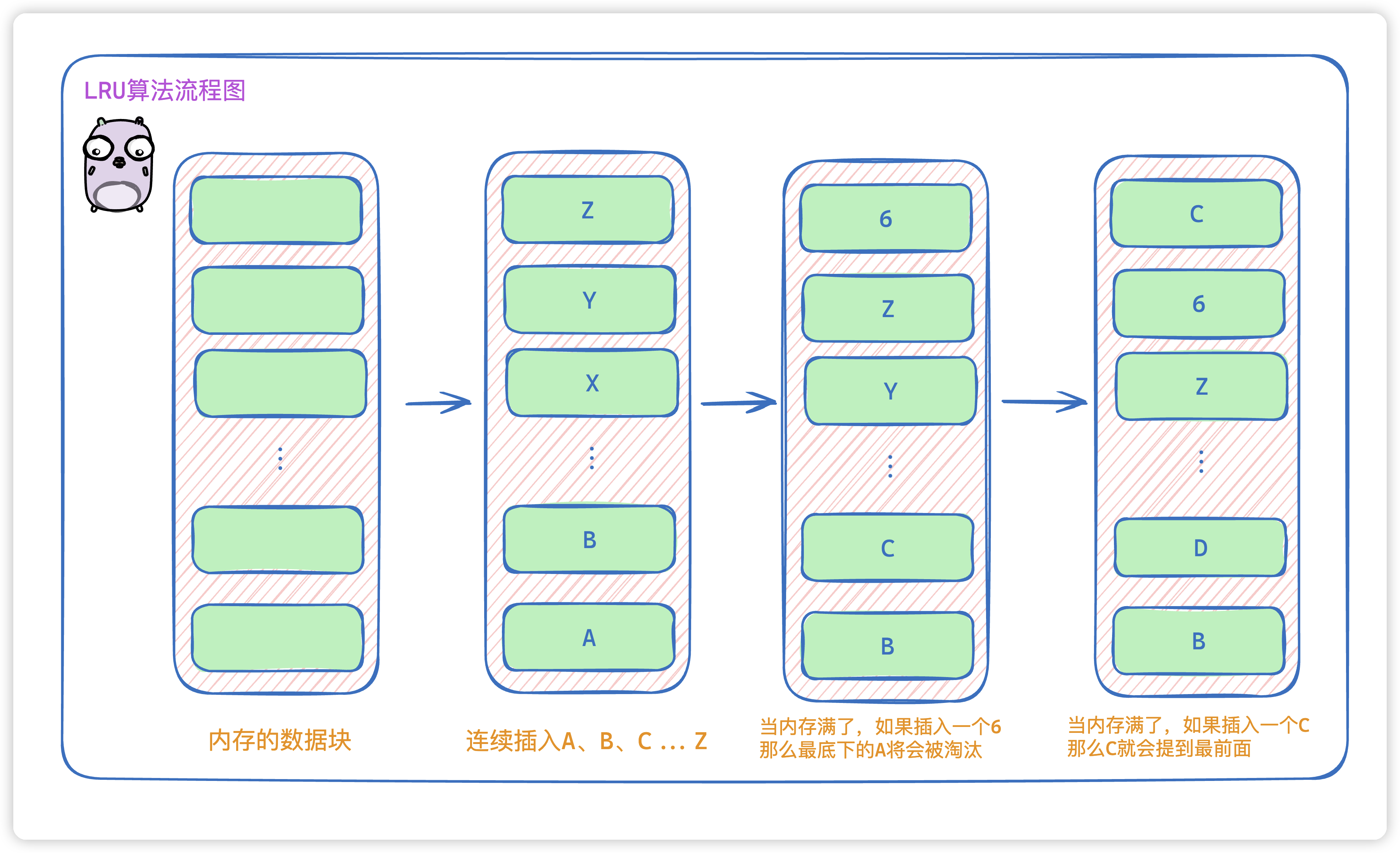
假设我们有这么一块内存,一共有26个数据存储块。
- 当我们连续插入A、B、C、…Z的时候,此时内存已经
插满了 - 那么当我们再插入一个6,那么此时会将内存存放时间最久的数据A淘汰掉。
- 当我们从外部读取数据C的时候,此时C就会
提到头部,这时候C就是最晚淘汰的了。
其实流程来说很简单。我们来拆分一下的话,不难发现这就是在维护一个双向链表。
代码实现
定义一个存放的数据块结构
type item struct {key stringvalue any// the frequency of keyfreq int
}
定义LRU算法的结构体
type LRU struct {dl *list.List // 维护的双端队列size int // 当前的容量capacity int // 限定的容量storage map[string]*list.Element // 存储的key
}
获取某个key的value的函数,如果存在这个key,那么我们就把这个值移动到最前面MoveToFront,否则返回一个nil。
func (c *LRU) Get(key string) any {v, ok := c.storage[key]if ok {c.dl.MoveToFront(v)return v.Value.(item).value}return nil
}
当我们需要put进去一些东西的时候。会分以下几个步骤
- 是否已经存在,如果已经存在则,直接返回,并且将
key移动到最前面。 - 如果没有存在,但是已经是到极限容量了,就把最后一个
Back(),淘汰掉,然后在塞入。 - 塞入的话,是塞入到最前面
PushFront
func (c *LRU) Put(key string, value any) {e, ok := c.storage[key]if ok {n := e.Value.(item)n.value = valuee.Value = nc.dl.MoveToFront(e)return}if c.size >= c.capacity {e = c.dl.Back()dk := e.Value.(item).keyc.dl.Remove(e)delete(c.storage, dk)c.size--}n := item{key: key, value: value}c.dl.PushFront(n)ne := c.dl.Front()c.storage[key] = nec.size++
}
以上就是LRU算法的所有内容了,那我们看一下LFU算法。
LFU
原理
LFU全称是最不经常使用算法(Least Frequently Used),LFU算法的基本思想和所有的缓存算法一样,一定时期内被访问次数最少的页,在将来被访问到的几率也是最小的。
相比于LRU(Least Recently Use)算法,LFU更加注重于使用的频率 。LRU是其实可以看作是频率为1的LFU的。
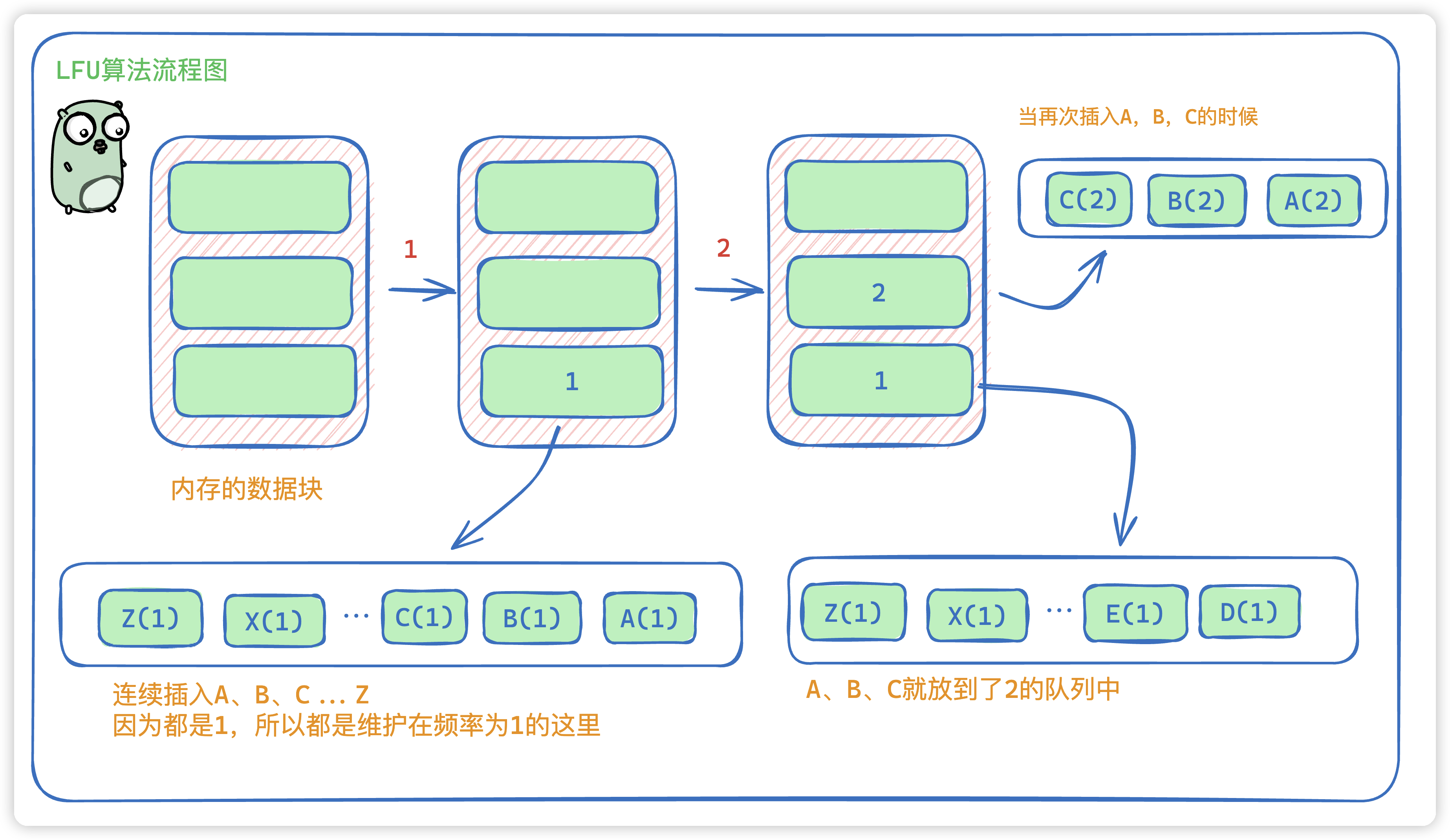
和LRU不同的是,LFU是根据频率排序的,当我们插入的时候,一般会把新插入的放到链表的尾部,因为新插入的一定是没有出现过的,所以频率都会是1 , 所以会放在最后。
所以LFU的插入顺序如下:
- 如果A没有出现过,那么就会放在双向链表的最后,依次类推,就会是Z、Y。。C、B、A的顺序放到频率为1的链表中。
- 当我们新插入 A,B,C 那么A,B,C就会到频率为2的链表中
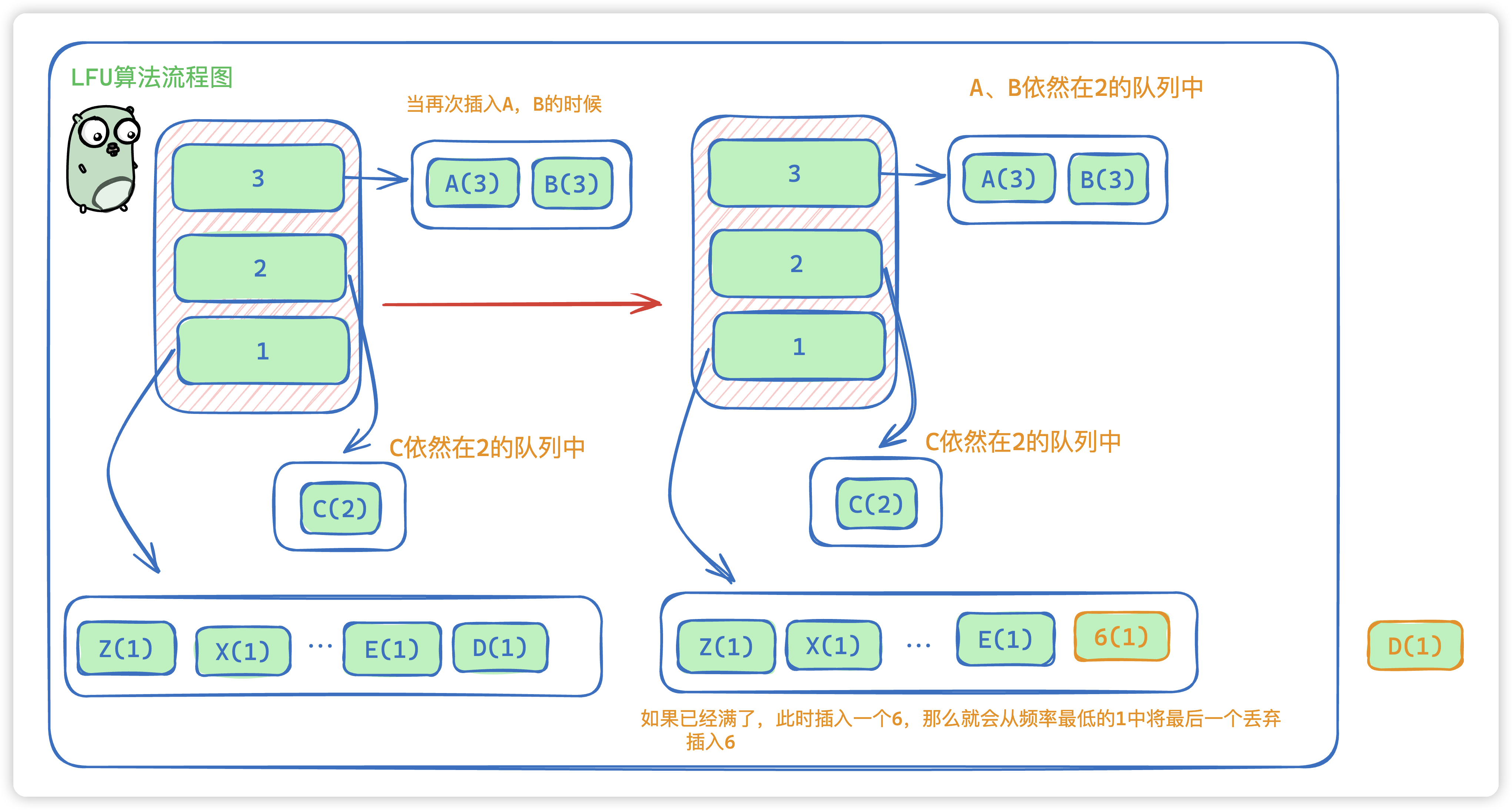
- 如果再次插入A,B那么A,B会在频率为3中。C依旧在2中
- 如果此时已经满了 ,新插入一个的话,我们会把最后一个D移除,并插入 6
代码
定义一个LFU的结构体:
// LFU the Least Frequently Used (LFU) page-replacement algorithm
type LFU struct {len int // lengthcap int // capacityminFreq int // The element that operates least frequently in LFU// key: key of element, value: value of elementitemMap map[string]*list.Element// key: frequency of possible occurrences of all elements in the itemMap// value: elements with the same frequencyfreqMap map[int]*list.List // 维护一个频率和list的集合
}
我们使用LFU算法的话,我们插入的元素就需要带上频率了
// initItem to init item for LFU
func initItem(k string, v any, f int) item {return item{key: k,value: v,freq: f,}
}
如果我们获取某个元素,那么这个元素如果存在,就会对这个元素的频率进行加1
// Get the key in cache by LFU
func (c *LFU) Get(key string) any {// if existed, will return valueif e, ok := c.itemMap[key]; ok {// the frequency of e +1 and change freqMapc.increaseFreq(e)obj := e.Value.(item)return obj.value}// if not existed, return nilreturn nil
}
增加频率
// increaseFreq increase the frequency if element
func (c *LFU) increaseFreq(e *list.Element) {obj := e.Value.(item)// remove from low frequency firstoldLost := c.freqMap[obj.freq]oldLost.Remove(e)// change the value of minFreqif c.minFreq == obj.freq && oldLost.Len() == 0 {// if it is the last node of the minimum frequency that is removedc.minFreq++}// add to high frequency listc.insertMap(obj)
}
插入key到LFU缓存中
- 如果存在就对频率加1
- 如果不存在就准备插入
- 如果溢出了,就把最少频率的删除
- 如果没有溢出,那么就放到最后
// Put the key in LFU cache
func (c *LFU) Put(key string, value any) {if e, ok := c.itemMap[key]; ok {// if key existed, update the valueobj := e.Value.(item)obj.value = valuec.increaseFreq(e)} else {// if key not existedobj := initItem(key, value, 1)// if the length of item gets to the top line// remove the least frequently operated elementif c.len == c.cap {c.eliminate()c.len--}// insert in freqMap and itemMapc.insertMap(obj)// change minFreq to 1 because insert the newest onec.minFreq = 1// length++c.len++}
}
插入一个新的
// insertMap insert item in map
func (c *LFU) insertMap(obj item) {// add in freqMapl, ok := c.freqMap[obj.freq]if !ok {l = list.New()c.freqMap[obj.freq] = l}e := l.PushFront(obj)// update or add the value of itemMap key to ec.itemMap[obj.key] = e
}
找到最少的链表,并且删除
// eliminate clear the least frequently operated element
func (c *LFU) eliminate() {l := c.freqMap[c.minFreq]e := l.Back()obj := e.Value.(item)l.Remove(e)delete(c.itemMap, obj.key)
}以上就是所有LFU的算法实现了。
这篇关于图解缓存淘汰算法 LRU、LFU | 最近最少使用、最不经常使用算法 | go语言实现的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







