本文主要是介绍矢量分析之方圆两公里怎么做?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
布鲁斯李
按照处理的空间数据结构类型来看,GIS 的空间分析可以分为栅格数据分析和矢量数据分析两种不同的空间分析模式。今天我们就着重介绍一下SuperMap IDesktop中矢量分析的相关功能操作与实际应用。在idesktop中,矢量分析功能包括:缓冲区分析、叠加分析与邻近分析。那么如何灵活运用这些功能呢?举一个简单的例子:我想知道学校周边两公里的范围有多大,就需要做学校的缓冲区分析。我想知道这两公里范围内有多少饭店,就需要学校两公里的缓冲区范围与饭店数据做叠加分析。我想知道学校范围两公里内离学校最近的饭店,就需要做邻近分析。那么下面在介绍这些功能的同时,让我们也应用一下上面的小例子。
什么是缓冲区分析?
缓冲区分析是对一组或一类地图要素(点、线或面)按设定的距离条件,围绕这组要素而形成具有一定范围的多边形实体,从而实现数据在二维空间扩展的信息分析方法。用户可使用桌面应用程序的缓冲区分析功能对点、线、面数据生成缓冲区,包括单重缓冲区以及多重缓冲区。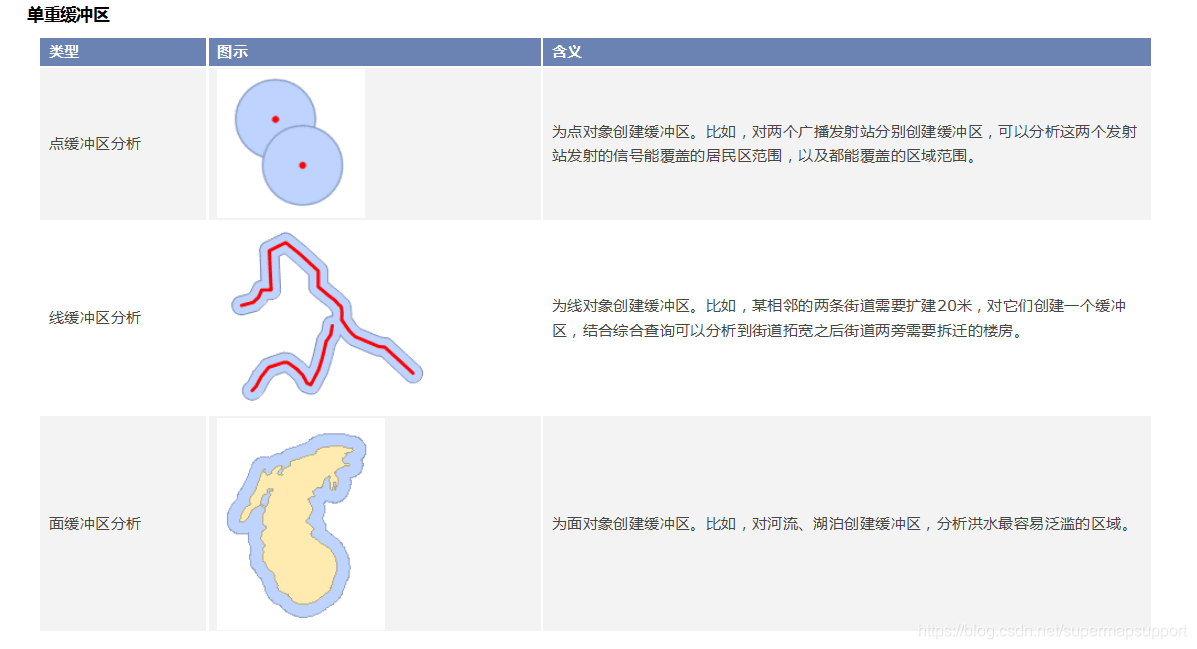

在上面的例子中,我们需要了解学校周边两公里的范围有多大。首先我们定位到学校,然后选择“空间分析”选项卡下矢量分析中的“缓冲区分析”。
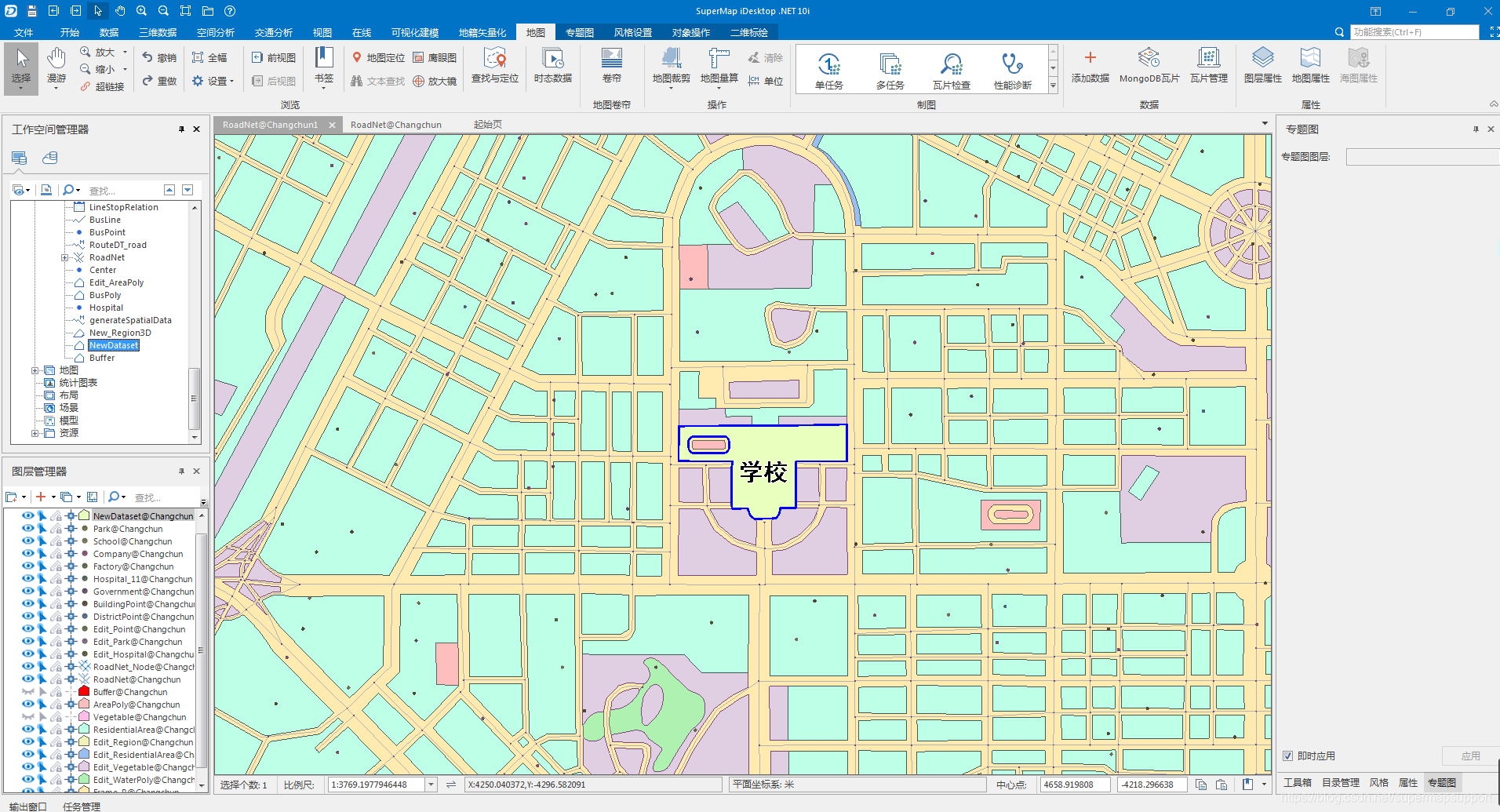
参数设置以及效果如下:
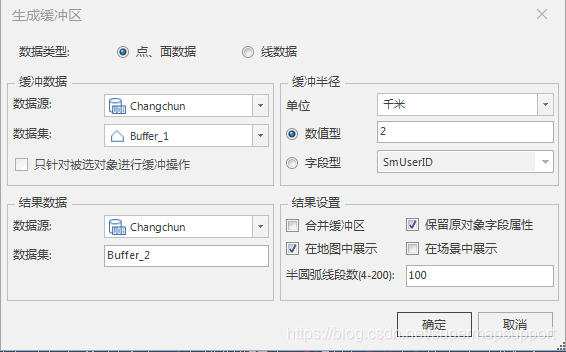
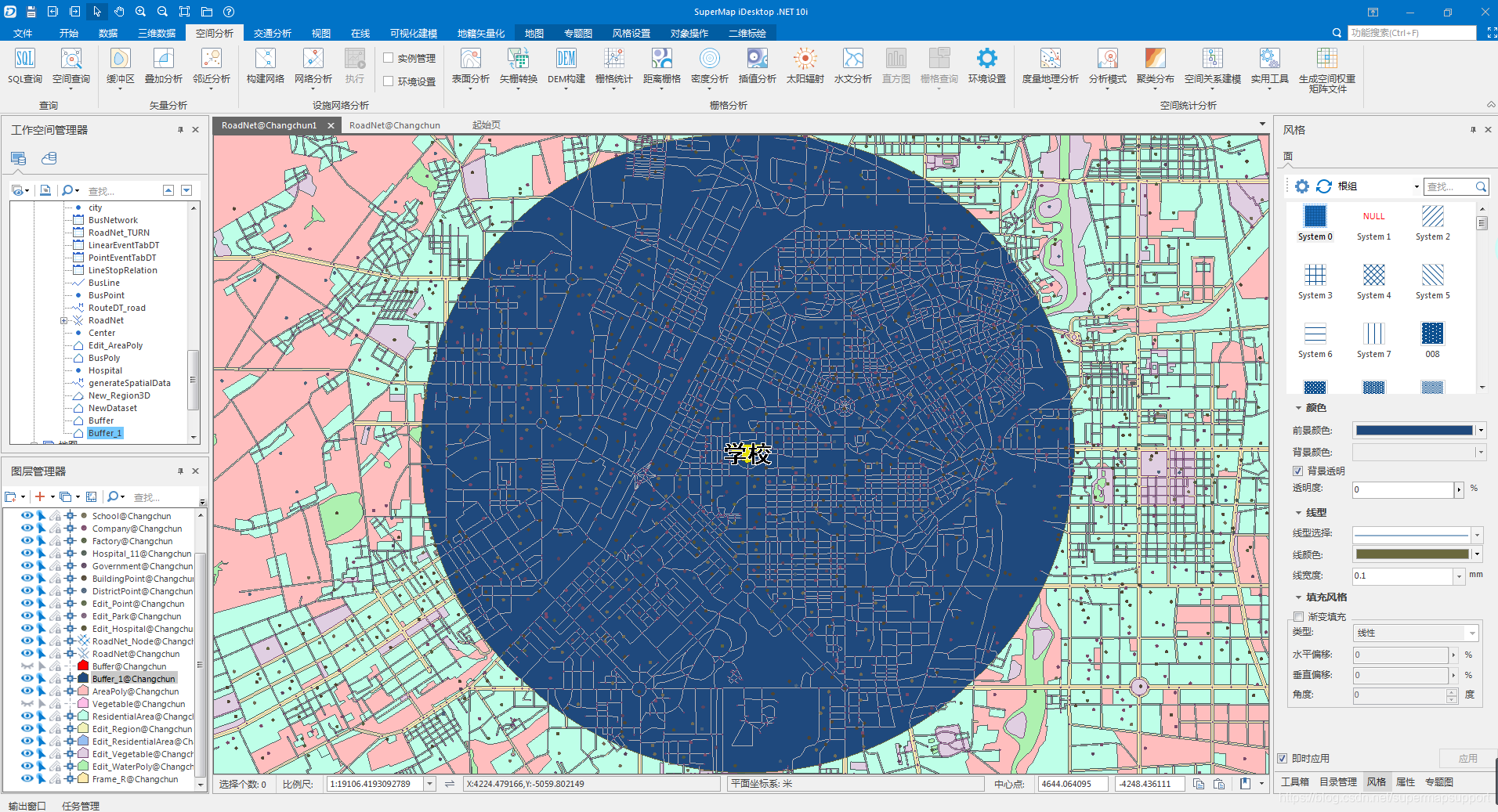
缓冲区分析是GIS的基本空间操作功能之一,是指根据指定的距离,在点、线、面几何对象周围自动建立一定宽度的区域的分析方法。例如,在环境治理时,常在污染的河流周围划出一定宽度的范围表示受到污染的区域;又如在飞机场,常根据健康需要在周围划分出一定范围的区域作为非居住区,等等。
什么是叠加分析?
叠加分析也是 GIS 的基本空间操作功能之一,是指通过矢量数据间的集合运算,产生新数据的过程。桌面应用程序提供了对点、线、面类型数据集叠加分析的功能,如裁剪、合并、擦除、求交、同一、对称差、更新。在这里先详细介绍一下叠加分析的七个算子。
裁剪:裁剪是用裁剪数据集从被裁剪数据集中提取部分特征集合的运算。裁剪数据集中的多边形集合定义了裁剪区域,被裁剪数据集中凡是落在这些多边形区域外的特征都将被去除,而落在多边形区域内的特征要素都将被输出到结果数据集中。

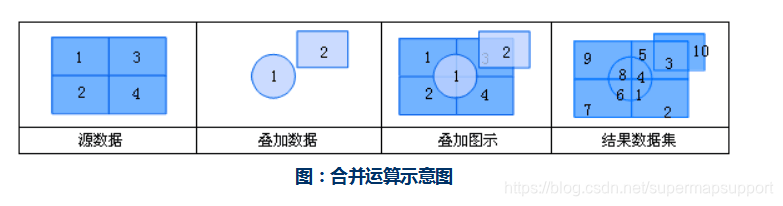
合并:合并是求两个数据集并的运算。进行合并运算后,两个面数据集在相交处多边形被分割,重建拓扑关系,且两个数据集的几何和属性信息都被输出到结果数据集中。
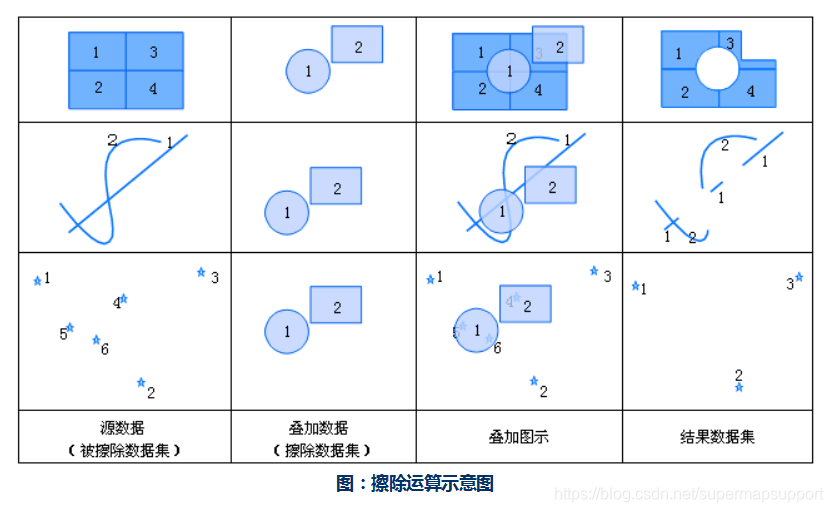
擦除:擦除是用来擦除掉被擦除数据集中多边形相重合部分的操作。擦除数据集中的多边形集合定义了擦除区域,被擦除数据集中凡是落在这些多边形区域内的特征都将被去除,而落在多边形区域外的特征要素都将被输出到结果数据集中。擦除运算与裁剪运算原理相同,只是对源数据集中保留的内容不同。
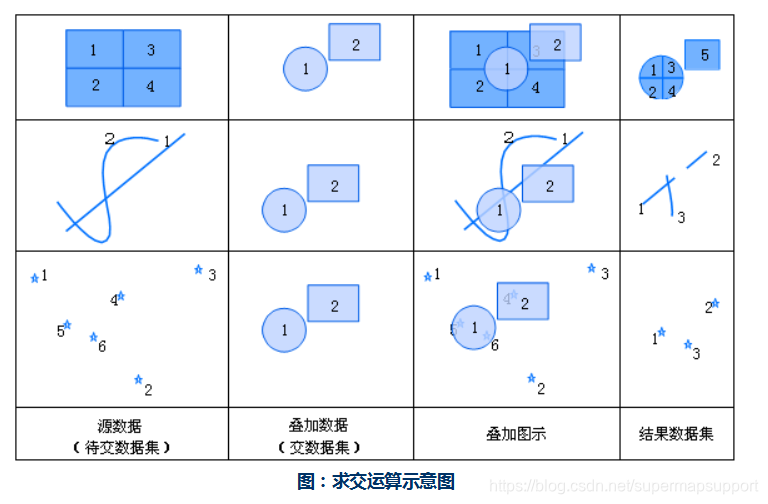
求交:求交运算是求两个数据集的交集的操作。待求交数据集的特征对象在与交数据集中的多边形相交处被分割(点对象除外)。求交运算与裁剪运算得到的结果数据集的空间几何信息是相同的,但是裁剪运算不对属性表做任何处理,而求交运算可以让用户选择需要保留的属性字段。
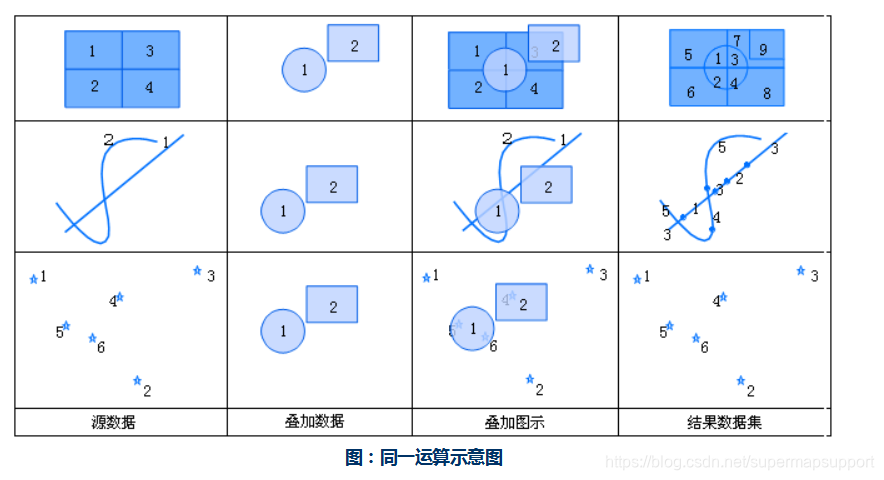
同一:同一运算结果图层范围与源数据集图层的范围相同,但是包含来自叠加数据集图层的几何形状和属性数据。同一运算就是源数据集与叠加数据集先求交,然后求交结果再与源数据集求并的一个运算。如果第一个数据集为点数集,则新生成的数据集中保留第一个数据集的所有对象;如果第一个数据集为线数据集,则新生成的数据集中保留第一个数据集的所有对象,但是把与第二个数据集相交的对象在相交的地方打断;如果第一个数据集为面数据集,则结果数据集保留以源数据集为控制边界之内的所有多边形,并且把与第二个数据集相交的对象在相交的地方分割成多个对象。
对称差:对称差运算是两个数据集的异或运算。操作的结果是,对于每一个面对象,去掉其与另一个数据集中的几何对象相交的部分,而保留剩下的部分。
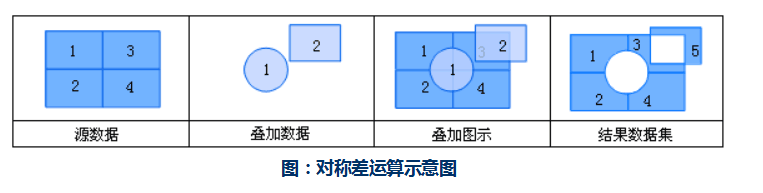
更新:更新运算是用更新数据集替换与被更新数据集重合的部分,是一个先擦除后粘贴的过程。结果数据集中保留了更新数据集的几何形状和属性信息。
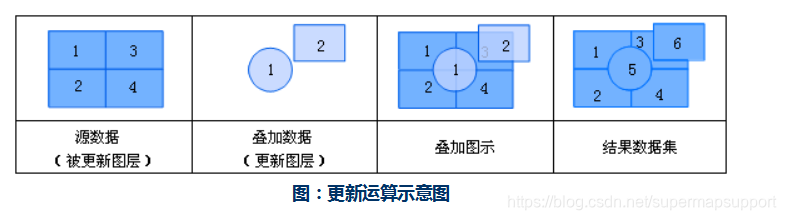
那么在上面的小例子中,我们想知道学校两公里范围内有哪些饭店,可以使用叠加分析,算子选择相交。参数设置以及结果如下:
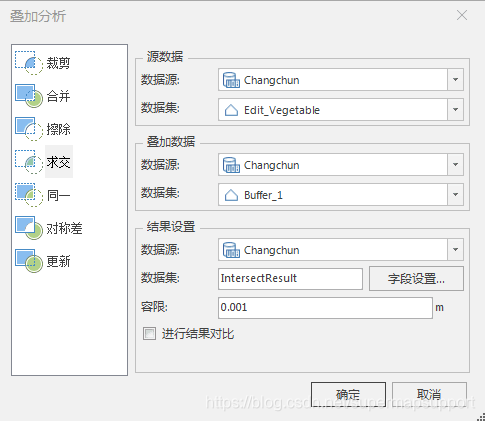
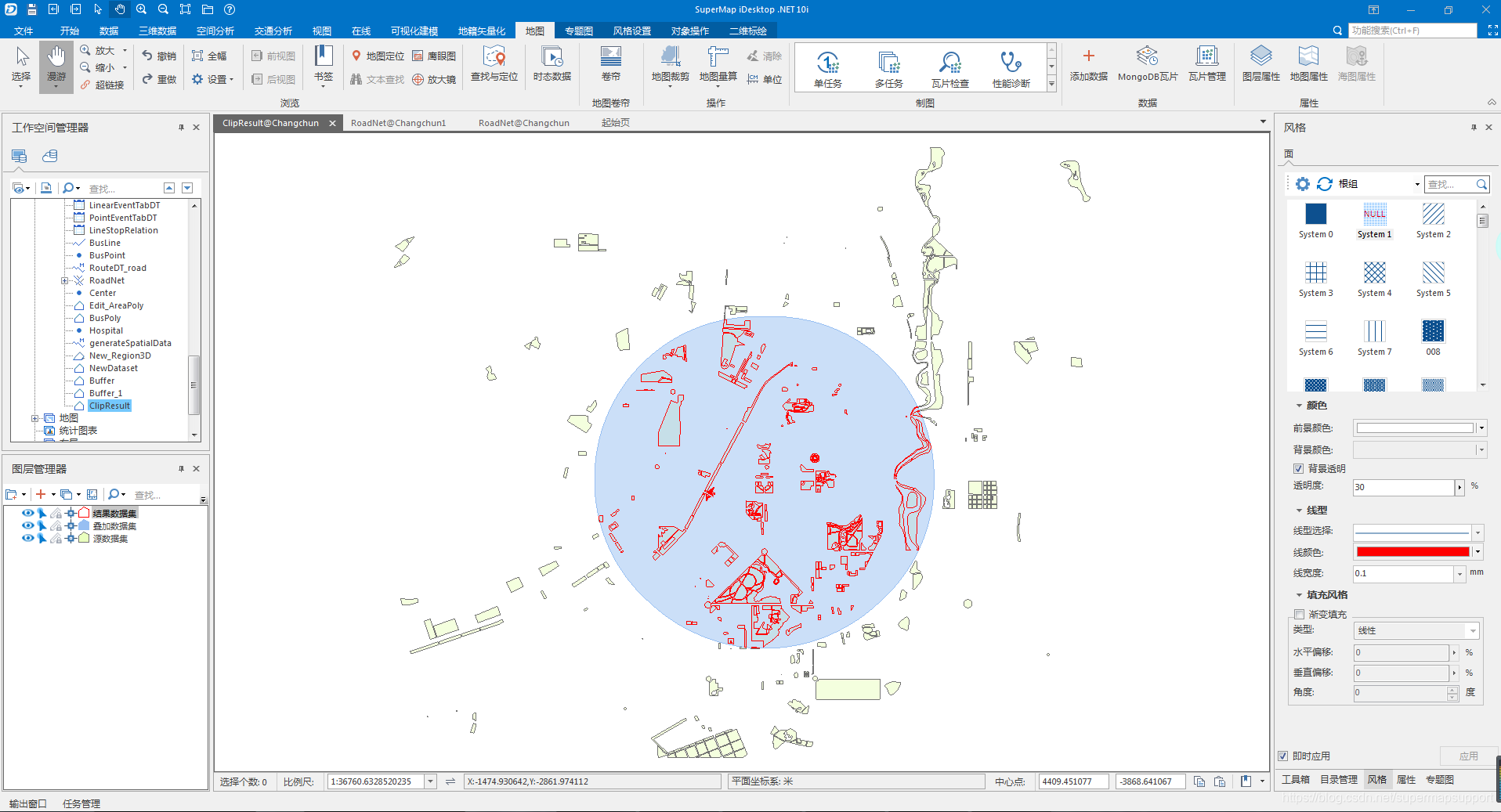
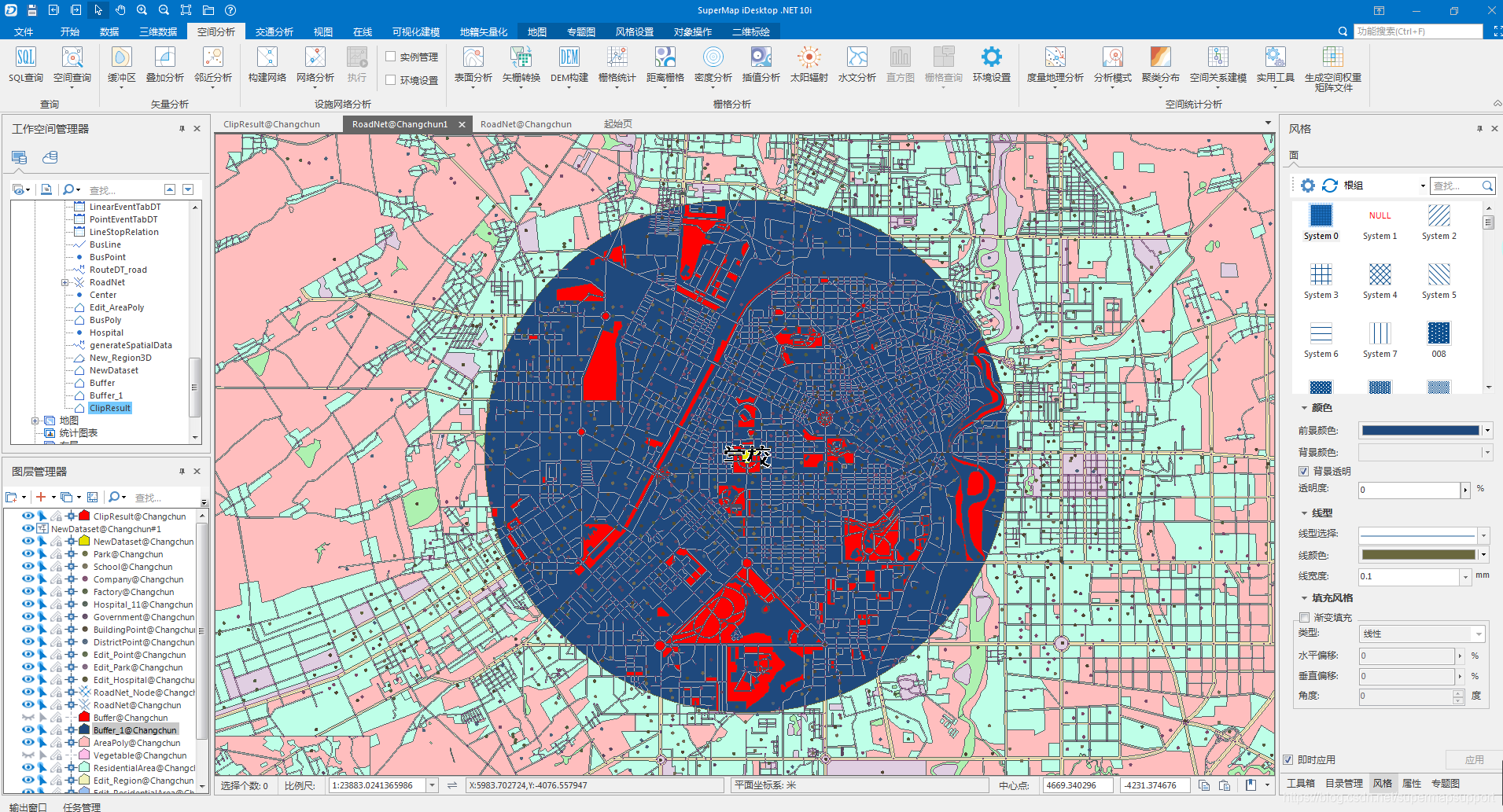
叠加分析是通过对空间数据的加工或分析,提取用户需要的新的空间几何信息。比如,我们需要了解某一个行政区内的土壤分布情况,就可以根据全国的土地利用图和行政区规划图这两个数据集进行叠加分析,得到我们需要的结果。同时,通过叠加分析,还可以对数据的各种属性信息进行处理。叠加分析广泛应用于资源管理、城市建设评估、国土管理、农林牧业、统计等领域。
邻近分析:
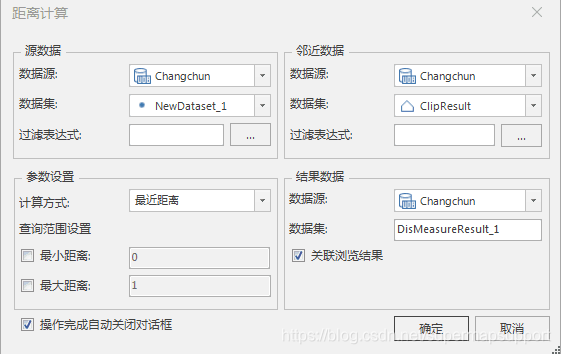
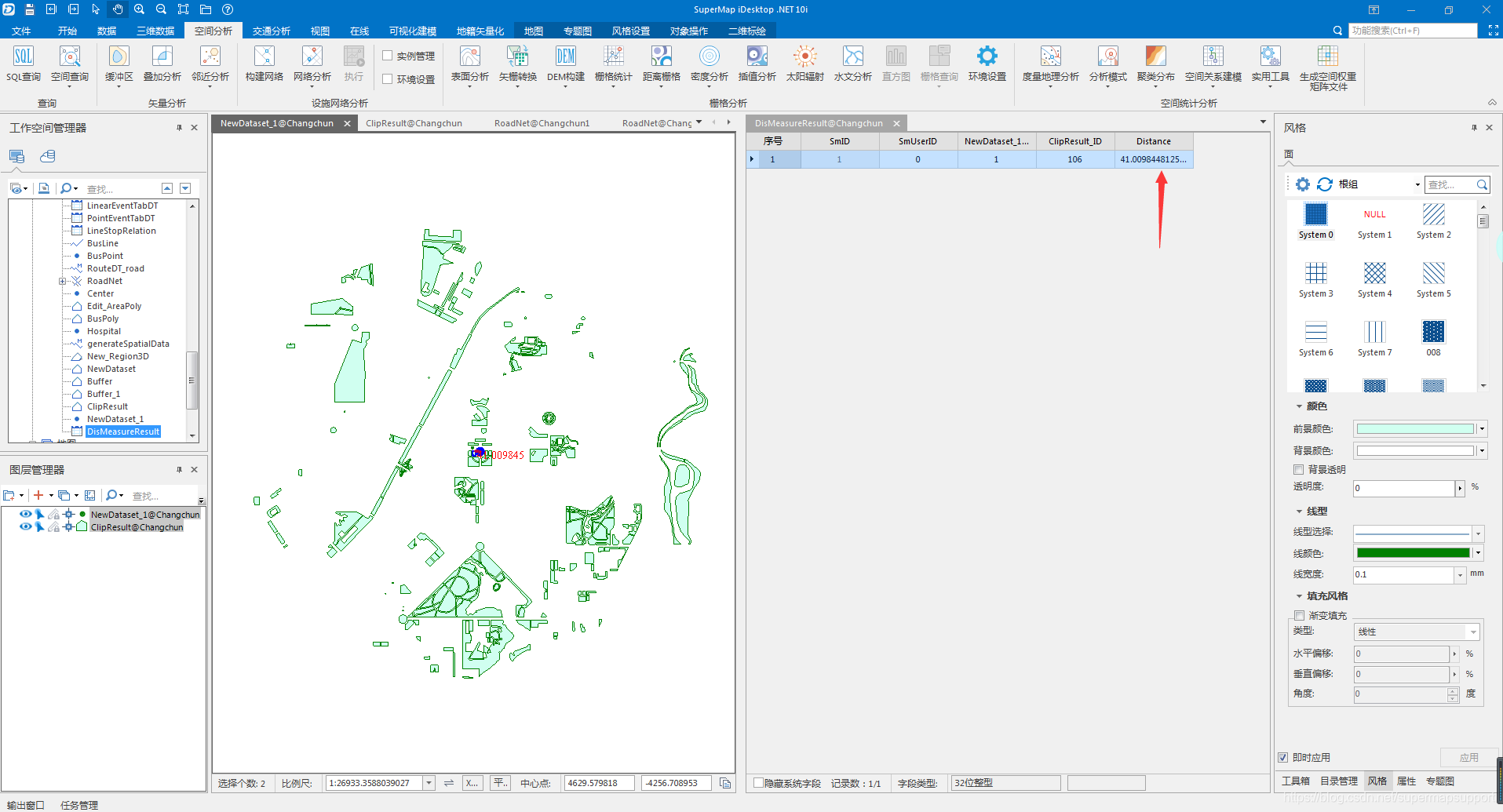
在我们上述的例子里,我们需要知道两公里范围内离学校最近的饭店,可以使用到邻近分析中的距离量算功能。
距离量算用于计算点对象到其它点、线、面对象之间的最短间距,即两个对象之间最接近的距离。分析结果输出到属性表中,属性表中分别记录了源对象和邻近对象的 ID 及两对象之间的距离。
距离计算原则:

需要使用到上一步中获得的面数据。
参数设置以及效果如下:
在实际应用中,通常会遇到一些距离相关的问题,例如:
• 离泥石流发生地最近的居民点?
• 从国家体育场出发,2公里内最近的两家超市?
• 某地区的各个移动通信信号发射塔按强弱等级逐渐递减所覆盖的范围?
• 某条被污染的河流周围1000米内,有多少家食品加工厂?
• 瑞士国内所有足球比赛场馆和酒店分别表示在两个图层上,从任意一家酒店到最近的场馆的距离是多少?
以上的实际问题大部分与空间上地物的位置与距离相关,邻近分析提供了用于确定多个或两个要素类间邻近性的功能,邻近分析功能包括缓冲区分析、泰森多边形、距离计算、距离查询、空间查询等功能,这些分析功能可用于解决此类问题。
矢量分析在实际综合应用中还有着更加丰富复杂的使用,在这里只是简单为大家介绍了冰山一角,重要的是gis分析只是一种工具,这需要我们带着gis思想去解决遇见的各种现实问题。
这篇关于矢量分析之方圆两公里怎么做?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







