本文主要是介绍day31 第八章 贪心算法 part01● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
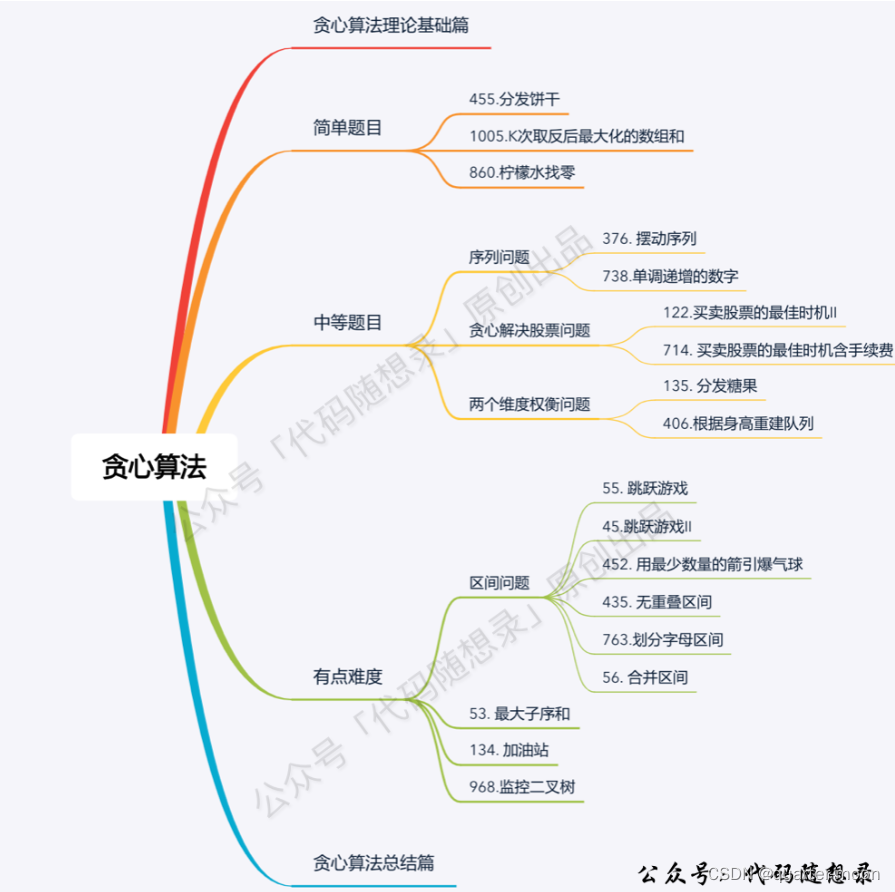
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
证明不用贪心的方法:最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。
贪心合理性证明:数学归纳法和反证法。
贪心没有套路,说白了就是常识性推导加上举反例。

一遍过。就是小的胃口用尽量小的饼干填饱。
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {int len1=g.size();int len2=s.size();sort(g.begin(),g.end());sort(s.begin(),s.end());int st=0;int en=0;int res=0;while(st<len1&&en<len2){while(en<len2&&g[st]>s[en]){en++;}if(en<len2&&st<len1&&g[st]<=s[en]){res++;en++;st++;}if(en==len2) break;}return res;}
}; 题解:大尺寸的饼干既可以满足胃口大的孩子也可以满足胃口小的孩子,那么就应该优先满足胃口大的。然后从后向前遍历小孩数组,用大饼干优先满足胃口大的,并统计满足小孩数量。
// 版本一
class Solution {
public:int findContentChildren(vector<int>& g, vector<int>& s) {sort(g.begin(), g.end());sort(s.begin(), s.end());int index = s.size() - 1; // 饼干数组的下标int result = 0;for (int i = g.size() - 1; i >= 0; i--) { // 遍历胃口if (index >= 0 && s[index] >= g[i]) { // 遍历饼干result++;index--;}}return result;}
};
一遍过。一开始分为两个方向,递增或递减,两种情况取更大值。假设一开始递增,那么假设第二个比第一个大,那么就摆动序列长度目前为2,假如第三个比第二个大,那么序列的末尾更新为第三个元素,这样下次选递减数的范围会变大。假如第三个比第二个小,但比第一个大,序列不更新。假如第三个比第二个小,那么摆动序列长度为3,以此类推。
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {int len1=nums.size();int st=0;int res=1;if(nums.size()==2){if(nums[0]==nums[1]) return 1;else return 2;}int res1=1;int flag=1;for(int i=1;i<len1;){if(flag==1){if(nums[i]>nums[st]) {res++;flag=0;st=i;i++;}else{st=i;i++;}}else{if(nums[i]<nums[st]) {res++;flag=1;st=i;i++;}else{st=i;i++;}}}flag=0;st=0;for(int i=1;i<len1;){if(flag==1){if(nums[i]>nums[st]) {res1++;flag=0;st=i;i++;}else{st=i;i++;}}else{if(nums[i]<nums[st]) {res1++;flag=1;st=i;i++;}else{st=i;i++;}}}return max(res,res1);}
};题解似乎更数形结合一些,另一种思考方法:

局部最优:删除单调坡度上的节点(不包括单调坡度两端的节点),那么这个坡度就可以有两个局部峰值。
整体最优:整个序列有最多的局部峰值,从而达到最长摆动序列。
在计算是否有峰值的时候,大家知道遍历的下标 i ,计算 prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i]),如果prediff < 0 && curdiff > 0 或者 prediff > 0 && curdiff < 0 此时就有波动就需要统计。
这是我们思考本题的一个大题思路,但本题要考虑三种情况:
- 情况一:上下坡中有平坡
- 情况二:数组首尾两端
- 情况三:单调坡中有平坡
#情况一:上下坡中有平坡
例如 [1,2,2,2,1]这样的数组,如图:
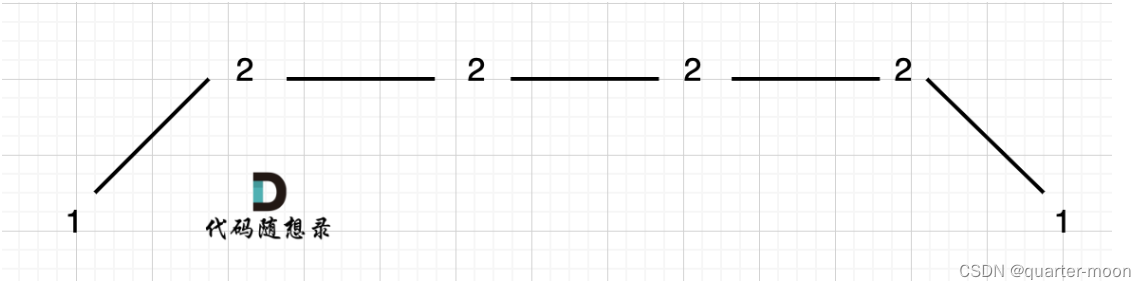
在图中,当 i 指向第一个 2 的时候,prediff > 0 && curdiff = 0 ,当 i 指向最后一个 2 的时候 prediff = 0 && curdiff < 0。
如果我们采用,删左面三个 2 的规则,那么 当 prediff = 0 && curdiff < 0 也要记录一个峰值,因为他是把之前相同的元素都删掉留下的峰值。
所以我们记录峰值的条件应该是: (preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0),为什么这里允许 prediff == 0 ,就是为了 上面我说的这种情况。
情况二:数组首尾两端
所以本题统计峰值的时候,数组最左面和最右面如何统计呢?
题目中说了,如果只有两个不同的元素,那摆动序列也是 2。
例如序列[2,5],如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
因为我们在计算 prediff(nums[i] - nums[i-1]) 和 curdiff(nums[i+1] - nums[i])的时候,至少需要三个数字才能计算,而数组只有两个数字。
这里我们可以写死,就是 如果只有两个元素,且元素不同,那么结果为 2。
不写死的话,如何和我们的判断规则结合在一起呢?
可以假设,数组最前面还有一个数字,那这个数字应该是什么呢?
之前我们在 讨论 情况一:相同数字连续 的时候, prediff = 0 ,curdiff < 0 或者 >0 也记为波谷。
那么为了规则统一,针对序列[2,5],可以假设为[2,2,5],这样它就有坡度了即 preDiff = 0,如图:
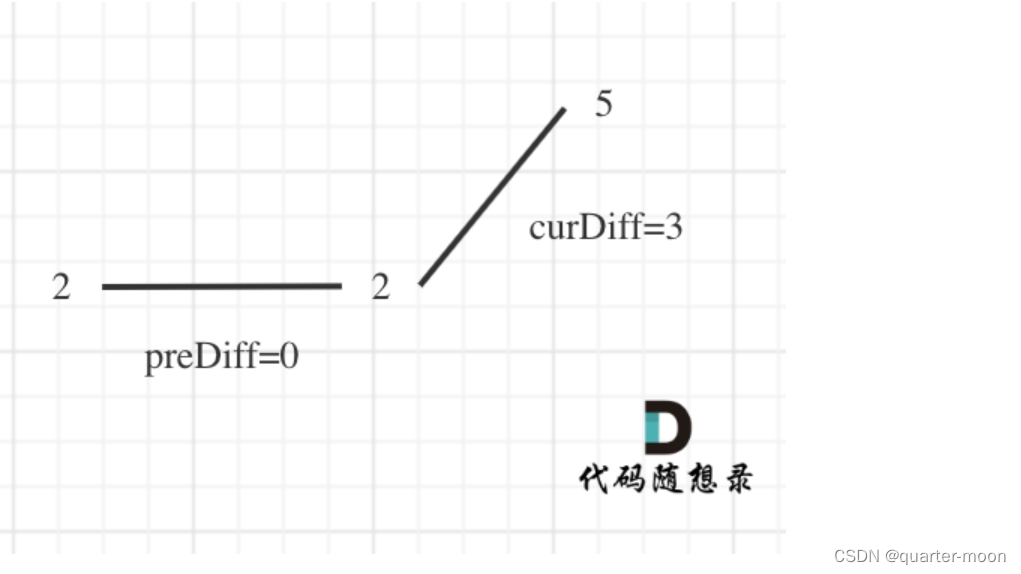
针对以上情形,result 初始为 1(默认最右面有一个峰值),此时 curDiff > 0 && preDiff <= 0,那么 result++(计算了左面的峰值),最后得到的 result 就是 2(峰值个数为 2 即摆动序列长度为 2)
情况三:单调坡度有平坡
在版本一中,我们忽略了一种情况,即 如果在一个单调坡度上有平坡,例如[1,2,2,2,3,4],如图:
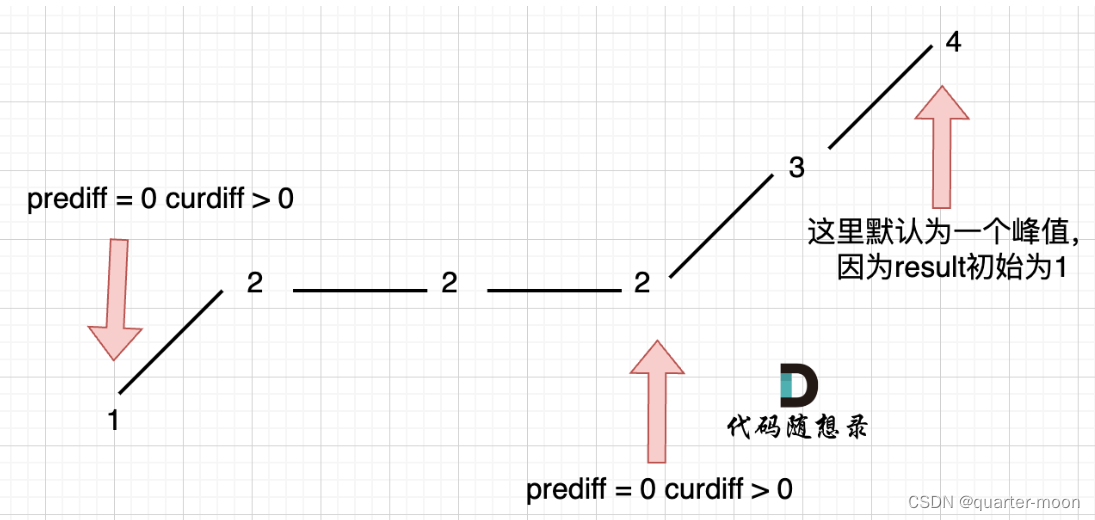
图中,我们可以看出,版本一的代码在三个地方记录峰值,但其实结果因为是 2,因为 单调中的平坡 不能算峰值(即摆动)。
之所以版本一会出问题,是因为我们实时更新了 prediff。
那么我们应该什么时候更新 prediff 呢?
我们只需要在 这个坡度 摆动变化的时候,更新 prediff 就行,这样 prediff 在 单调区间有平坡的时候 就不会发生变化,造成我们的误判。
所以本题的最终代码为:
// 版本二
class Solution {
public:int wiggleMaxLength(vector<int>& nums) {if (nums.size() <= 1) return nums.size();int curDiff = 0; // 当前一对差值int preDiff = 0; // 前一对差值int result = 1; // 记录峰值个数,序列默认序列最右边有一个峰值for (int i = 0; i < nums.size() - 1; i++) {curDiff = nums[i + 1] - nums[i];// 出现峰值if ((preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0)) {result++;preDiff = curDiff; // 注意这里,只在摆动变化的时候更新prediff}}return result;}
};其实本题看起来好像简单,但需要考虑的情况还是很复杂的,而且很难一次性想到位。
本题异常情况的本质,就是要考虑平坡, 平坡分两种,一个是 上下中间有平坡,一个是单调有平坡,如图:
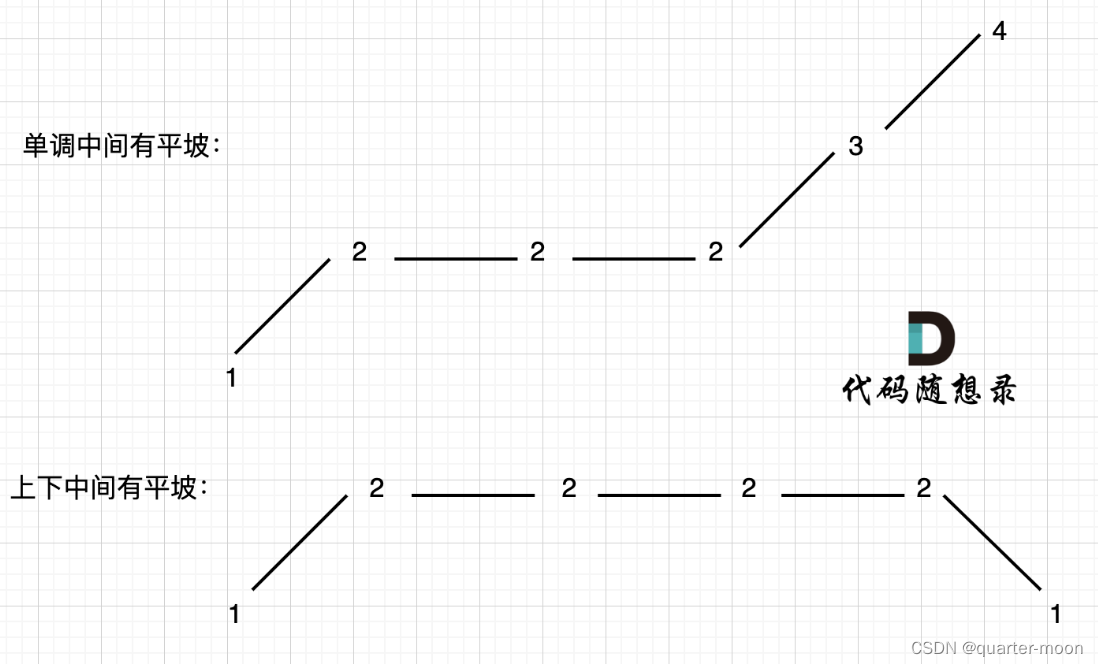
另外一种方法,动态规划
考虑用动态规划的思想来解决这个问题。
很容易可以发现,对于我们当前考虑的这个数,要么是作为山峰(即 nums[i] > nums[i-1]),要么是作为山谷(即 nums[i] < nums[i - 1])。
- 设 dp 状态
dp[i][0],表示考虑前 i 个数,第 i 个数作为山峰的摆动子序列的最长长度 - 设 dp 状态
dp[i][1],表示考虑前 i 个数,第 i 个数作为山谷的摆动子序列的最长长度
则转移方程为:
dp[i][0] = max(dp[i][0], dp[j][1] + 1),其中0 < j < i且nums[j] < nums[i],表示将 nums[i]接到前面某个山谷后面,作为山峰。dp[i][1] = max(dp[i][1], dp[j][0] + 1),其中0 < j < i且nums[j] > nums[i],表示将 nums[i]接到前面某个山峰后面,作为山谷。
初始状态:
由于一个数可以接到前面的某个数后面,也可以以自身为子序列的起点,所以初始状态为:dp[0][0] = dp[0][1] = 1。
class Solution {
public:int dp[1005][2];int wiggleMaxLength(vector<int>& nums) {memset(dp, 0, sizeof dp);dp[0][0] = dp[0][1] = 1;for (int i = 1; i < nums.size(); ++i) {dp[i][0] = dp[i][1] = 1;for (int j = 0; j < i; ++j) {if (nums[j] > nums[i]) dp[i][1] = max(dp[i][1], dp[j][0] + 1);}for (int j = 0; j < i; ++j) {if (nums[j] < nums[i]) dp[i][0] = max(dp[i][0], dp[j][1] + 1);}}return max(dp[nums.size() - 1][0], dp[nums.size() - 1][1]);}
};
进阶
可以用两棵线段树来维护区间的最大值
- 每次更新
dp[i][0],则在tree1的nums[i]位置值更新为dp[i][0] - 每次更新
dp[i][1],则在tree2的nums[i]位置值更新为dp[i][1] - 则 dp 转移方程中就没有必要 j 从 0 遍历到 i-1,可以直接在线段树中查询指定区间的值即可。
时间复杂度:O(nlog n)
空间复杂度:O(n)
线段树这部分内容我有些遗忘了,先留个空位?

看了题解。
如果 -2 1 在一起,计算起点的时候,一定是从 1 开始计算,因为负数只会拉低总和,这就是贪心贪的地方!
局部最优:当前“连续和”为负数的时候立刻放弃,从下一个元素重新计算“连续和”,因为负数加上下一个元素 “连续和”只会越来越小。
全局最优:选取最大“连续和”
局部最优的情况下,并记录最大的“连续和”,可以推出全局最优。
从代码角度上来讲:遍历 nums,从头开始用 count 累积,如果 count 一旦加上 nums[i]变为负数,那么就应该从 nums[i+1]开始从 0 累积 count 了,因为已经变为负数的 count,只会拖累总和。
这相当于是暴力解法中的不断调整最大子序和区间的起始位置。
区间的终止位置,其实就是如果 count 取到最大值了,及时记录下来了。
常见误区
误区一:
不少同学认为 如果输入用例都是-1,或者 都是负数,这个贪心算法跑出来的结果是 0, 这是又一次证明脑洞模拟不靠谱的经典案例,建议大家把代码运行一下试一试,就知道了,也会理解 为什么 result 要初始化为最小负数了。
误区二:
大家在使用贪心算法求解本题,经常陷入的误区,就是分不清,是遇到 负数就选择起始位置,还是连续和为负选择起始位置。
在动画演示用,大家可以发现, 4,遇到 -1 的时候,我们依然累加了,为什么呢?
因为和为 3,只要连续和还是正数就会 对后面的元素 起到增大总和的作用。 所以只要连续和为正数我们就保留。
这里也会有录友疑惑,那 4 + -1 之后 不就变小了吗? 会不会错过 4 成为最大连续和的可能性?
其实并不会,因为还有一个变量 result 一直在更新 最大的连续和,只要有更大的连续和出现,result 就更新了,那么 result 已经把 4 更新了,后面 连续和变成 3,也不会对最后结果有影响。
class Solution {
public:int maxSubArray(vector<int>& nums) {int res=INT_MIN;int count=0;for(int i=0;i<nums.size();i++){count+=nums[i];res=max(res,count);if(count<0) count=0;}return res;}
};这篇关于day31 第八章 贪心算法 part01● 理论基础 ● 455.分发饼干 ● 376. 摆动序列 ● 53. 最大子序和的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




