本文主要是介绍MaskRCNN训练自己的数据集 小白篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文旨在帮助对代码无从下手的小白训练自己数据集,分享一些自己遇到的坑&解决方案,以及一些方便大家制作数据集的代码。
附成品代码:download.csdn.net/download/weixin_43758528/11965024
参考博客见下文链接。
博主电脑配置:win10 + GTX1050Ti + cuda9.0 + cudnn7 + tensorflow-gpu1.5.0(配置见下文链接)
博主使用jupyter notebook对直接对源码进行更改,方便大家修改代码。
预先准备
maskrcnn配置教程:https://blog.csdn.net/chenmoran0928/article/details/79999073
注:win10若遇到cuda9安装不上的情况(显示NVIDIA驱动程序与此Windows版本不兼容),请将win10版本升级至1803及以上,并在NVIDIA官网https://www.geforce.cn/drivers安装自己显卡对应的最新驱动。
mask rcnn训练自己的数据集:https://blog.csdn.net/qq_29462849/article/details/81037343
注:该博客有些地方一带而过,像博主一样的小白可能会有诸多疑问。接下来我列举一些我曾经遇到的问题。
正文
数据集制作
labelme制作数据集方法:https://blog.csdn.net/u012746060/article/details/81871733
注:当你成功生成 .json 文件后想进行转换,可能会发现上文给出的转换代码不能使用(报错显示没有labelme_json_to_dataset.exe文件)。如果你遇到了这个问题,可以试试如下代码:
import os
path = 'D:/label' # path为json文件存放的路径
json_file = os.listdir(path)
os.system("activate labelme")
for file in json_file: os.system("labelme_json_to_dataset.exe %s"%(path + '/' + file))
博主用以上代码成功实现了转换。
数据集格式:
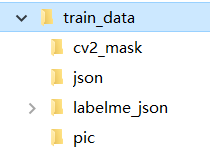
json文件夹下存放labelme生成的json文件
pic文件夹下存放原图
labelme_json文件夹下存放json文件转换生成的文件夹
cv2_mask文件夹下存放mask文件
何为mask文件? 打开json转换而来的文件夹,里面的label.png文件即为mask文件。
新版labelme能看到标注的mask(类似下图的红色区域),则此文件可直接使用(反之若图片全黑,则必须利用代码对图片进行修改)。
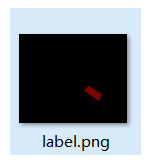
mask文件需要重命名为原图的名字,如test.jpg/png对应的mask文件需要修改为test.png。
人工操作比较复杂,此处给出博主使用的代码(需要先完成除cv2_mask外所有步骤):
#! /usr/bin/env python
# coding=utf-8
import os
import shutil
import time
import sys
import importlib
importlib.reload(sys)def copy_and_rename(fpath_input, fpath_output):for file in os.listdir(fpath_input):for inner in os.listdir(fpath_input+file+'/'):print(inner)if os.path.splitext(inner)[0] == "label":former = os.path.join(fpath_input, file)oldname = os.path.join(former, inner)print(oldname)newname_1 = os.path.join(fpath_output,file.split('_')[0] + ".png")#os.rename(oldname, newname)shutil.copyfile(oldname, newname_1)if __name__ == '__main__':print('start ...')t1 = time.time() * 1000#time.sleep(1) #1sfpath_input = ".../train_data/labelme_json/" #...为train_data文件夹地址,按自己的地址修改fpath_output = ".../train_data/cv2_mask/"copy_and_rename(fpath_input, fpath_output)t2 = time.time() * 1000print('take time:' + str(t2 - t1) + 'ms')print('end.')
运行后即可得到对应的文件。
(若报错split(’_’)[0],则先删掉split命令运行一次,再恢复原代码运行一次,就不报错了。玄学)
代码修改
博主使用sample中的train_shapes.ipynb文件进行修改。(参考https://blog.csdn.net/l297969586/article/details/79140840/)
1、修改ROOT_DIR

修改为MaskRCNN根目录(以防更改后的train_shapes.ipynb被移动到其他地址)
补充: from PIL import Image
2、修改配置

将NUM_CLASSES修改为1+N(背景+标签数)。如你的数据集中标注了2种物体,则N=2 。
修改IMAGE_MIN_DIM为你的数据集图片中最小维度
修改IMAGE_MAX_DIM为最大维度
3、修改训练代码:参考https://blog.csdn.net/l297969586/article/details/79140840/
(1)删除dataset中前两个模块的所有代码(仅保留Load and display random samples)
(2)将参考文章中”△4、重新写一个训练类 “内所有代码复制下来
(3)根据自己标签的名称和数量,修改函数load_shapes中的 Add_classes
(4)将函数load_shapes中,图中所示内容替换为以下代码
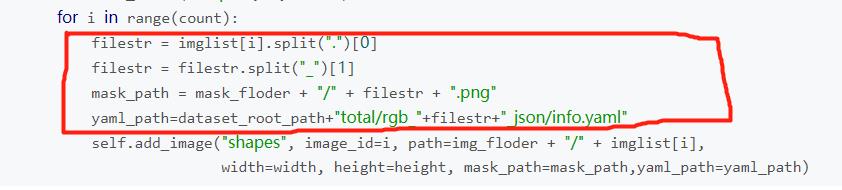
filestr = imglist[i].split(".")[0]mask_path = mask_floder + "/" + filestr + ".png"yaml_path=dataset_root_path+"/labelme_json/"+filestr+"_json/info.yaml"
(5)根据自己标签的名称和数量,修改函数load_mask中 if labels[i].find("…")!=-1: labels_form.append("…")
4、代码主体修改:参考文章同上
(1)将参考文章中”4、代码主体修改“内所有代码复制下来
(2)将各folder地址改为对应地址(如dataset_root_path 改为 dataset_root_path = os.path.join(ROOT_DIR, “train_data”)),同理更改img_folder和mask_folder
(3)修改width和height为自己图片的宽和高
(4)修改函数load_shapes中的宽和高与上一步一致

5、开始测试代码吧!
常见报错
1、class_ids = class_ids[_idx] IndexError: boolean index did not match indexed array along dimension 0; dimension is 0 but corresponding boolean dimension is 128
出现类似此错误的原因有很多,所以请依次检查以下内容:
(1)mask文件是否正确。
(2)配置中NUM_CLASSES是否修改。
(3)上文“代码修改”第三条中(3)(5)是否正确修改。
2、缺少pillow
安装PIL即可
3、找不到指定模块…xx/Shapely
pip install shapely
参考文章:
[1]: https://blog.csdn.net/chenmoran0928/article/details/79999073
[2]: https://blog.csdn.net/qq_29462849/article/details/81037343
[3]: https://blog.csdn.net/u012746060/article/details/81871733
[4]: https://blog.csdn.net/l297969586/article/details/79140840/
[5]: https://blog.csdn.net/u012746060/article/details/82143285
这篇关于MaskRCNN训练自己的数据集 小白篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




