本文主要是介绍KDD CUP99数据预处理三个步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
入侵检测实验一般使用的是KDD CUP99中的kddcup.data_10percent数据集。由于数据集中包含有符号型的数据属性,不适合直接处理,所以需要进行预处理,数据集的预处理一般由三个步骤:
1.将字符型特征转换成数值型特征
2.数值标准化
3.数值归一化
关于KDD CUP99的数据预处理看了两个博客,两个博客合在一起比较完整,所以这里转载过来,记录下来方便学习。
!!!以下部分转自:https://blog.csdn.net/asialee_bird/article/details/80491256
1、数据集下载:http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html
2、KDDCup99网络入侵检测数据集介绍:
https://blog.csdn.net/com_stu_zhang/article/details/6987632
https://www.cnblogs.com/gongyanc/p/6703532.html
3、Weka进阶——基于KDD99数据集的入侵检测分析:
https://blog.csdn.net/jbfsdzpp/article/details/44099849
4、符号型特征数值化
采用one-hot方法进行数值化:https://blog.csdn.net/qq_28617019/article/details/79717184
5、KDD CUP99数据集预处理
(1)字符型特征转换为数值型特征(即符号型特征数值化)
Python3对KDD CUP99数据集预处理代码实现(仅实现字符型特征转为数值型特征)
#kdd99数据集预处理
#将kdd99符号型数据转化为数值型数据#coding:utf-8import numpy as np
import pandas as pd
import csv
import time
global label_list #label_list为全局变量#定义kdd99数据预处理函数
def preHandel_data():source_file='kddcup.data_10_percent_corrected'handled_file='kddcup.data_10_percent_corrected.csv'data_file=open(handled_file,'w',newline='') #python3.x中添加newline=''这一参数使写入的文件没有多余的空行with open(source_file,'r') as data_source:csv_reader=csv.reader(data_source)csv_writer=csv.writer(data_file)count=0 #记录数据的行数,初始化为0for row in csv_reader:temp_line=np.array(row) #将每行数据存入temp_line数组里temp_line[1]=handleProtocol(row) #将源文件行中3种协议类型转换成数字标识temp_line[2]=handleService(row) #将源文件行中70种网络服务类型转换成数字标识temp_line[3]=handleFlag(row) #将源文件行中11种网络连接状态转换成数字标识temp_line[41]=handleLabel(row) #将源文件行中23种攻击类型转换成数字标识csv_writer.writerow(temp_line)count+=1#输出每行数据中所修改后的状态print(count,'status:',temp_line[1],temp_line[2],temp_line[3],temp_line[41])data_file.close()#将相应的非数字类型转换为数字标识即符号型数据转化为数值型数据
def find_index(x,y):return [i for i in range(len(y)) if y[i]==x]#定义将源文件行中3种协议类型转换成数字标识的函数
def handleProtocol(input):protocol_list=['tcp','udp','icmp']if input[1] in protocol_list:return find_index(input[1],protocol_list)[0]#定义将源文件行中70种网络服务类型转换成数字标识的函数
def handleService(input):service_list=['aol','auth','bgp','courier','csnet_ns','ctf','daytime','discard','domain','domain_u','echo','eco_i','ecr_i','efs','exec','finger','ftp','ftp_data','gopher','harvest','hostnames','http','http_2784','http_443','http_8001','imap4','IRC','iso_tsap','klogin','kshell','ldap','link','login','mtp','name','netbios_dgm','netbios_ns','netbios_ssn','netstat','nnsp','nntp','ntp_u','other','pm_dump','pop_2','pop_3','printer','private','red_i','remote_job','rje','shell','smtp','sql_net','ssh','sunrpc','supdup','systat','telnet','tftp_u','tim_i','time','urh_i','urp_i','uucp','uucp_path','vmnet','whois','X11','Z39_50']if input[2] in service_list:return find_index(input[2],service_list)[0]#定义将源文件行中11种网络连接状态转换成数字标识的函数
def handleFlag(input):flag_list=['OTH','REJ','RSTO','RSTOS0','RSTR','S0','S1','S2','S3','SF','SH']if input[3] in flag_list:return find_index(input[3],flag_list)[0]#定义将源文件行中攻击类型转换成数字标识的函数(训练集中共出现了22个攻击类型,而剩下的17种只在测试集中出现)
def handleLabel(input):#label_list=['normal.', 'buffer_overflow.', 'loadmodule.', 'perl.', 'neptune.', 'smurf.',# 'guess_passwd.', 'pod.', 'teardrop.', 'portsweep.', 'ipsweep.', 'land.', 'ftp_write.',# 'back.', 'imap.', 'satan.', 'phf.', 'nmap.', 'multihop.', 'warezmaster.', 'warezclient.',# 'spy.', 'rootkit.']global label_list #在函数内部使用全局变量并修改它if input[41] in label_list:return find_index(input[41],label_list)[0]else:label_list.append(input[41])return find_index(input[41],label_list)[0]if __name__=='__main__':start_time=time.clock()global label_list #声明一个全局变量的列表并初始化为空label_list=[]preHandel_data()end_time=time.clock()print("Running time:",(end_time-start_time)) #输出程序运行时间
该代码仅对10%的训练集(kddcup.data_10_percent_corrected)进行处理
!!!以下部分转自:https://blog.csdn.net/jsh306/article/details/86536707
(2)数值标准化
首先计算各属性的平均值和平均绝对误差,公式为

其中,X_k 表示第k个属性的均值,S_k表示第k个属性的平均绝对误差,X_ik表示第i条记录的第k个属性。
然后对每条数据记录进行标准化度量,即

其中,Z_ik表示标准化后的第i条数据记录的第k个属性值。
Python3 对数据集的数据标准化方法实现如下:
def Handle_data():source_file = "kddcup.data_10_percent_corrected.csv"handled_file = "kddcup1.data_10_percent_corrected.csv"data_file = open(handled_file,'w',newline='')with open(source_file,'r') as data_source:csv_reader = csv.reader(data_source) count = 0 row_num = "" for row in csv_reader:count = count+1 row_num = row sum = np.zeros(len(row_num)) #和sum.astype(float) avg = np.zeros(len(row_num)) #平均值avg.astype(float)stadsum = np.zeros(len(row_num)) #绝对误差stadsum.astype(float) stad = np.zeros(len(row_num)) #平均绝对误差stad.astype(float) dic = {} lists = [] for i in range(0,len(row_num)):with open(source_file,'r') as data_source:csv_reader = csv.reader(data_source)for row in csv_reader:sum[i] += float(row[i])avg[i] = sum[i] / count #每一列的平均值求得 with open(source_file,'r') as data_source:csv_reader = csv.reader(data_source)for row in csv_reader:stadsum[i] += math.pow(abs(float(row[i]) - avg[i]), 2)stad[i] = stadsum[i] / count #每一列的平均绝对误差求得 with open(source_file,'r') as data_source:csv_reader = csv.reader(data_source)list = [] for row in csv_reader: temp_line=np.array(row) #将每行数据存入temp_line数组里 if avg[i] == 0 or stad[i] == 0:temp_line[i] = 0else:temp_line[i] = abs(float(row[i]) - avg[i]) / stad[i] list.append(temp_line[i]) lists.append(list) for j in range(0,len(lists)): dic[j] = lists[j] #将每一列的元素值存入字典中 df = pd.DataFrame(data = dic)df.to_csv(data_file,index=False,header=False) data_file.close()
(3)数值归一化
将标准化后的每个数值归一化到[0,1]区间。公式为
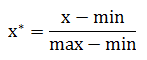
其中max为样本数据的最大值,min为样本数据的最小值,x为标准化后的数据。
Python3 对数据集的数据归一化方法实现如下:
def Find_Maxmin():source_file = "kddcup1.data_10_percent_corrected.csv" handled_file = "kddcup2.data_10_percent_corrected.csv"dic = {}data_file = open(handled_file,'w',newline='')with open(source_file,'r') as data_source:csv_reader=csv.reader(data_source) count = 0 row_num = "" for row in csv_reader:count = count+1 row_num = row with open(source_file,'r') as data_source:csv_reader=csv.reader(data_source)final_list = list(csv_reader)print(final_list)jmax = []jmin = []for k in range(0, len(final_list)): jmax.append(max(final_list[k]))jmin.append(min(final_list[k]))jjmax = float(max(jmax)) jjmin = float(min(jmin)) listss = [] for i in range(0,len(row_num)):lists = [] with open(source_file,'r') as data_source:csv_reader=csv.reader(data_source) for row in csv_reader: if (jjmax-jjmin) == 0:x = 0else:x = (float(row[i])-jjmin) / (jjmax-jjmin) lists.append(x)listss.append(lists)for j in range(0,len(listss)): dic[j] = listss[j]df = pd.DataFrame(data = dic)df.to_csv(data_file,index=False,header=False)data_file.close()
这篇关于KDD CUP99数据预处理三个步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



