本文主要是介绍客户案例|100M 768 维向量数据,Zilliz Cloud 稳定支持 Shulex VOC 业,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
日前,国际化 VOC SaaS 公司数里行间(Shulex)将上亿数据量的核心业务从开源向量数据库 Milvus 迁移至全托管的向量数据库云服务 Zilliz Cloud。
相比于 Milvus,Zilliz Cloud 实现了 Shulex VOC 评论分析洞察报告生成速度 30% 的提升,VOC 智能客服召回率 98%,且系统稳定,0 宕机,大大降低了企业在向量数据库的运维成本。

01.从内卷到出海,Shulex 为电商打造基于大模型的 VOC 服务
近几年,国内电商市场竞争日益激烈,跨境电商异军突起,这也无形中增高了中小商家入局的门槛,Shulex 正是在这样的背景下迅速崛起。Shulex 专注品牌出海,面向海外客户和中国出海客户,基于大模型为企业提供 VOC SaaS 服务,帮助企业通过数智化来引领产品创新、驱动客户品牌增长。
02.从 Milvus 到 Zilliz Cloud,向量数据库支撑 Shulex 核心业务场景
随着业务的高速发展,仅在 VOC 评论分析业务上,Shulex 就训练了 10,000 条以上电商类目的评论标签,产生了上亿规模的向量数据。以往基于开源向量数据库 Milvus 自建方案,费时费力,稳定性无法保障,运维成本非常高昂,当出现故障的时候往往需要几个小时甚至一天才能恢复,运营疲于处理由于系统不稳定导致的客户吐槽和投诉,客户满意度也持续走低。
Shulex 技术专家李辰辉表示:“业务发展到这个阶段,对向量数据库的要求也就更严苛了,要能弹性扩容以支撑海量的向量存储与搜索,向量匹配速度要更快、SLA 足够高,运维成本一定要够低。”
在与 Milvus 的背后商业公司 Zilliz 的专家团队进行充分沟通后,Shulex 技术团队决定将核心业务的向量数据库部分搬迁至 Milvus 的全托管云服务 Zilliz Cloud 上。目前 Zilliz Cloud 主要支持了 Shulex 的 VOC 评论分析及智能客服两大块核心业务。
| 文本搜索场景——VOC 评论分析
Shulex 是排名第一的 Amazon ChatGPT 选品工具,而 VOC 评论分析服务核心是通过向量数据库对海量的 Amazon 评论/社媒数据,进行分类打标和实时分析,为客户提供实时的商品评论洞察报告,包括但不限于:用户画像、使用场景、购买动机、商品卖点、商品不足点等。
向量数据库是该业务场景的关键组件,基于 Zilliz Cloud 的 VOC 评论分析流程包含建库、选品、分析样本、全量打标、报表生成 5 个步骤,具体来看:
-
建立用来判断评论的标签库:在向量数据里面存储的表结构包括评论文本、评论的 embedding、评论的正负情感标签等等;
-
选择待分析的商品类目:在上万个类目的商品中选择感兴趣的品类作为后续进行评论分析的对象;
-
基于大模型的评论分析:选择上一步中品类的数万条评论(包含正负评论、意思相近的评论)输入给大模型,让 GPT-4 对每个评论进行标签,将这些标签而后进行聚类后生成标签的样本库;
-
用向量数据库做分类打标:将生成的标签样本输出给向量数据库里进行该类目商品的全部评论 embedding数据的检索,结合向量数据库来进行分类,判断这些评论的正负情感;
-
生成结构化的统计报表:基于向量数据库的分类情况,进行用户对该商品属性的情感、正负向的分析,然后生成报表。
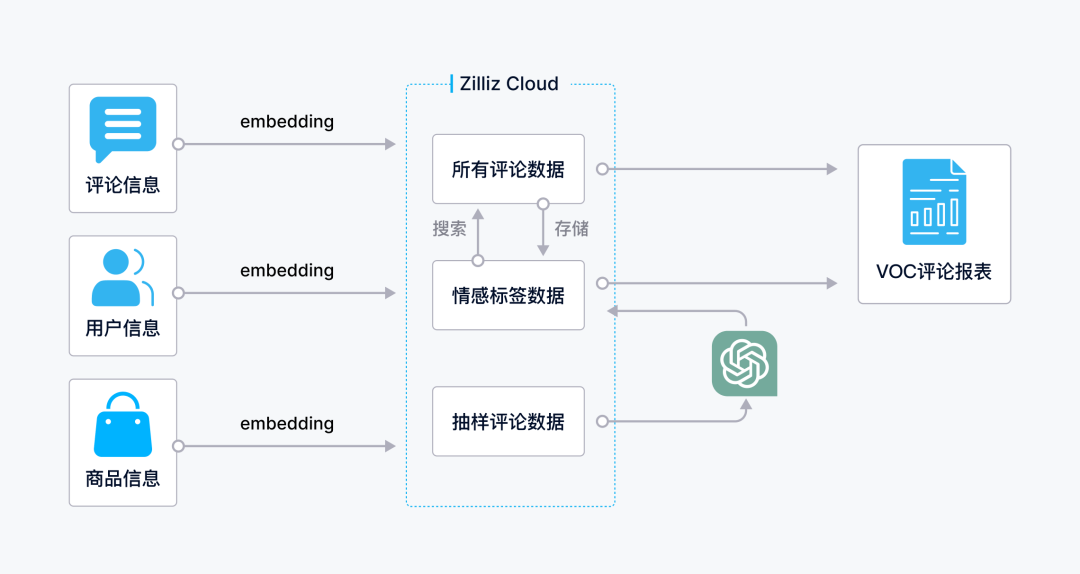 图 1 |基于 Zilliz Cloud 的 VOC 评论分析流程
图 1 |基于 Zilliz Cloud 的 VOC 评论分析流程
Zilliz Cloud 的引入在 Shulex VOC 评论分析业务中取得的收益显著,总结而言包括以下几点:
报表生成速度提升 30%:Zilliz Cloud 提供更高性能的向量搜索能力,其搜索引擎性能比开源 Milvus 提升超过 5 倍,稳定支持了 1000 QPS 的商品评论的高频次搜索。同时,相比于 Milvus,搜索时延降低了 50%,这使生成结构化的统计报表速度提升 30%;
数据分析成本降低 50%:由于无需将所有的商品评论信息通过大模型进行分析来获取评论标签,仅需要基于评论原文与向量数据库,实时召回评论标签即可生成高质量标签,去除了对大模型的依赖,极大的降低了评论数据分析的成本。
分钟级响应大促等突发流量:对于突发的客户访问量剧增,如大促周期,以往需要客户请求排队半个小时甚至 1 个小时,而 Zilliz Cloud 支持弹性扩缩容,集群增减分钟级即可完成,客户排队的状况也顺利解决。
| 大模型 RAG 应用——VOC 智能问答系统
Shulex 提供 VOC 企业智能问答系统,通过训练企业与外部数据,自动解析成 FAQ,2 分钟生成专业客服机器人,可以显著提升响应效率,同时降低运营成本。
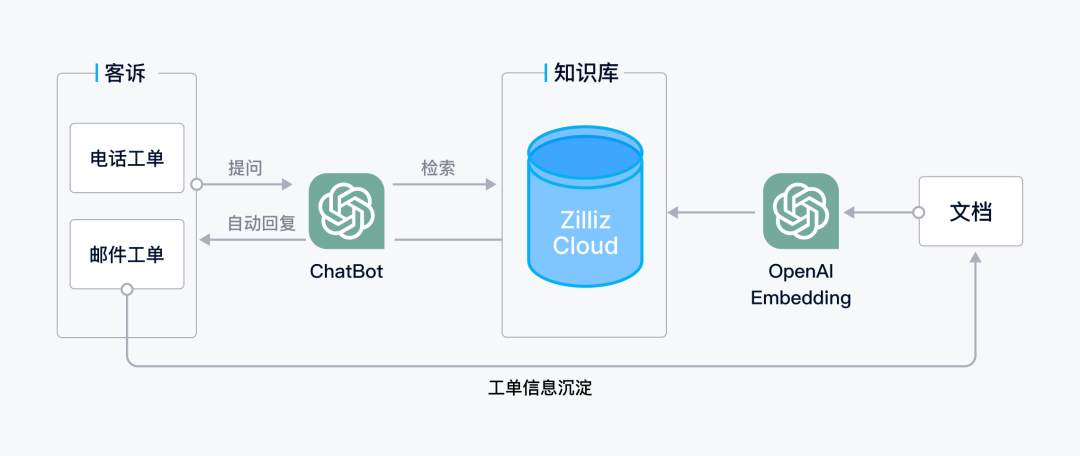 图 2 |基于 Zilliz Cloud 的 VOC 智能问答系统
图 2 |基于 Zilliz Cloud 的 VOC 智能问答系统
当前,Shulex VOC 智能客服业务采用大模型+向量数据库的标准范式构建了 RAG 应用,除了自动提取公网链接,还将企业文件、邮件、工单等多渠道的知识 embedding 后存入 Zilliz Cloud 来构建企业专属知识库,为大模型增加外接记忆体。而 Zilliz Cloud 使得大模型能够快速有效地检索和处理大量的向量数据,实时召回知识,稳定支撑 Shulex VOC 智能客服业务每秒 90 次的客户询问,稳定召回率在 98% 以上,据统计,Shulex 智能客服机器人已经可以承担 80% 以上的客服工作。
03.客户说
Shulex CTO 潘胜一表示:“从开源的向量数据库 Milvus 切换到托管云服务 Zilliz Cloud 后,我们的业务收益显著提升,实现了更低的运维成本、更高的业务速度、更灵活的系统架构以及更稳定的用户体验。通过使用 Zilliz Cloud,我们能够享受到专家团队的支持,他们能够高效沟通并快速解决业务中遇到的问题。总的来说,Zilliz Cloud 为我们带来了更大的便利和竞争优势,我们对这一转变感到非常满意和乐观。”
04.关于 Zilliz
Zilliz 作为向量数据库技术的开创者,推出的全球最受欢迎的的开源向量数据库--Milvus,受到了全球 5000 家以上企业用户的支持与青睐。2023 年,Zilliz推出了基于 Milvus 的全托管云服务 Zilliz Cloud。
截至目前,Zilliz Cloud 已实现全球 4 大云 11 个节点的全覆盖,是全球首个提供海内外多云服务的向量数据库企业,其企业注册用户已超过 40,000 家,付费用户遍及全球多个国家和地区,覆盖 AIGC 领域、电商、在线教育等场景。作为 AIGC 关键基础设施和 RAG 技术的基本组件提供商,Zilliz 完成了与全球头部大模型生态的对接,赋能大模型应用落地。
加入 Zilliz AI 初创计划
Zilliz AI 初创计划是面向 AI 初创企业推出的一项扶持计划,预计提供总计 1000 万元的 Zilliz Cloud 抵扣金,致力于帮助 AI 开发者构建高效的非结构化数据管理系统,助力打造高质量 AI 服务与运用,加速产业落地。点击 https://zilliz.com.cn/ 了解更多。
本文由 mdnice 多平台发布
这篇关于客户案例|100M 768 维向量数据,Zilliz Cloud 稳定支持 Shulex VOC 业的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






