本文主要是介绍NASA和IBM联合开发的 2022 年多时相土地分类数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
美国国家航空航天局(NASA)和国际商业机器公司(IBM)合作,利用大规模卫星和遥感数据,包括大地遥感卫星和哨兵-2 号(HLS)数据,创建了地球观测人工智能基础模型。通过奉行开放式人工智能和开放式科学的原则,两家机构都在积极为促进知识共享和加快创新以应对重大环境挑战的全球使命做出贡献。通过Hugging Face的平台,他们简化了地理空间模型的训练和部署,使开放科学用户、初创企业和企业能够在watsonx等多云人工智能平台上使用这些模型。此外,Hugging Face 还能在社区内轻松共享模型系列(我们的团队称之为 Prithvi)的管道,促进全球合作和参与。有关 Prithvi 的更多详情,请参阅 IBM NASA 联合技术论文。
多时作物分类数据集
数据集摘要
本数据集包含 2022 年美国毗连地区不同土地覆被和作物类型类别的统一陆地卫星-圣天诺时空影像。目标标签来自美国农业部的作物数据层(CDL)。它的主要用途是训练分割地理空间机器学习模型。
数据集结构
TIFF 文件
每个 TIFF 文件覆盖 224 x 224 像素区域,空间分辨率为 30 米。每个输入卫星文件包含 18 个波段,其中包括三个时间步长叠加在一起的 6 个光谱波段。每个掩膜的 GeoTIFF 文件包含一个波段,每个像素包含目标类别。
Band Order
在每个输入的 GeoTIFF 中,以下波段在整个生长季节的三次观测中重复三次: 通道、名称、HLS S30 波段编号
1, Blue, B02
2, Green, B03
3, Red, B04
4, NIR, B8A
5, SW 1, B11
6, SW 2, B12
Masks are a single band with values:
0 : "No Data" 1 : "Natural Vegetation" 2 : "Forest" 3 : "Corn" 4 : "Soybeans" 5 : "Wetlands" 6 : "Developed/Barren" 7 : "Open Water" 8 : "Winter Wheat" 9 : "Alfalfa" 10 : "Fallow/Idle Cropland" 11 : "Cotton" 12 : "Sorghum" 13 : "Other"
训练数据
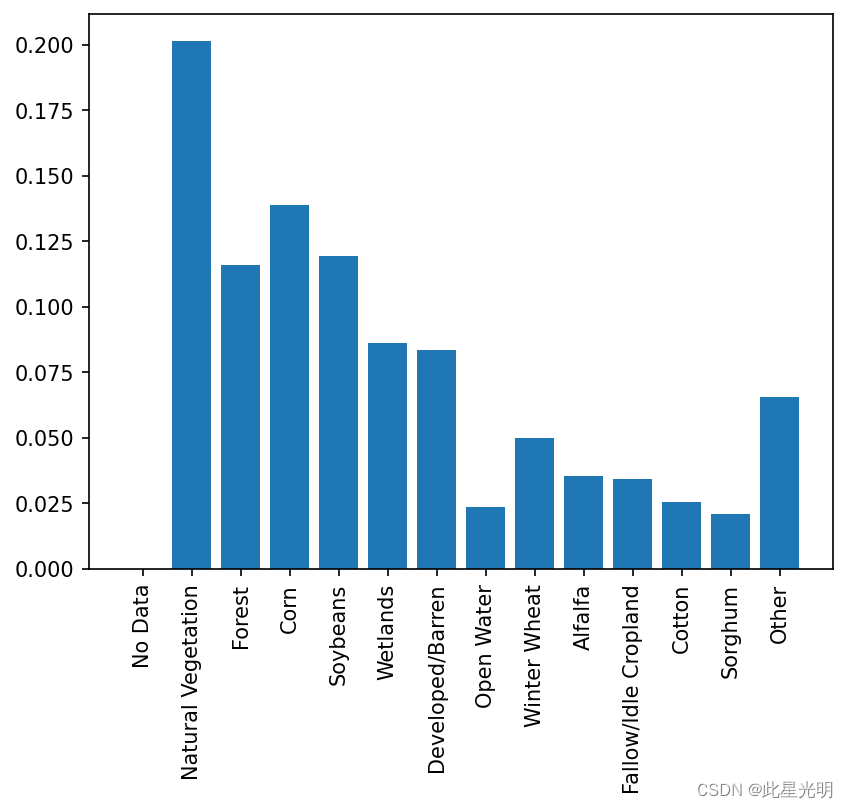
验证数据
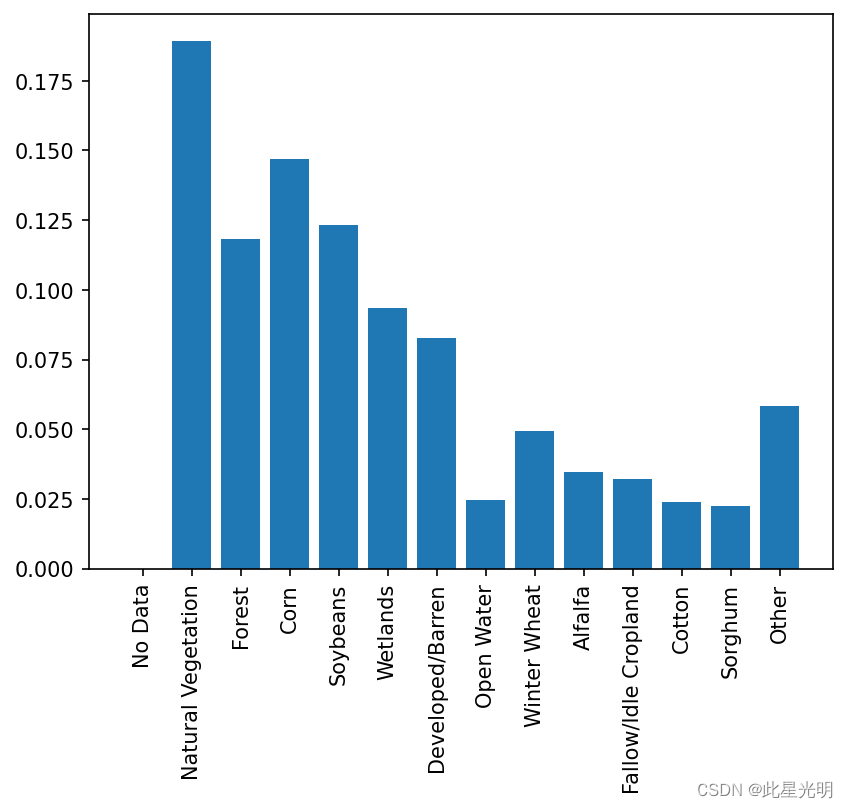
数据分割
3 854 个瓦片被随机分成训练数据(80%)和验证数据(20%),相应的 ID 记录在 cvs 文件 train_data.txt 和 validation_data.txt 中。
数据集创建
查询和场景选择
首先,根据美国农业部 CDL 的样本定义了一组 5,000 个瓦片,以确保在整个美国有代表性。然后,对每个片段查询 2022 年 3 月至 9 月期间相应的 HLS S30 场景,并检索云量较少的场景。然后,在低云层场景中选择三个场景,以确保在季节早期、中期和末期各有一个场景。然后,使用双线性插值法将最终的三个场景重新投影到 CDL 的投影网格(EPSG:5070)上。
最后一步,将每个瓦片的三个场景剪切到瓦片的边界框内,并将 18 个光谱带堆叠在一起。此外,使用 HLS 数据集的 Fmask 层对每个瓦片进行质量控制。任何含有云层、云影、邻近云层或缺失值的芯片都会被丢弃。这样就得到了 3854 个瓦片。
数据集下载
您可以从该资源库下载 .tgz 格式的数据(需要安装Git Large File Sotrage)。相同版本的数据作为 AWS S3 上的对象托管在 Source Cooperative 上。
数据引用
@misc{hls-multi-temporal-crop-classification,author = {Cecil, Michael and Kordi, Fatemehand Li, Hanxi (Steve) and Khallaghi, Sam and Alemohammad, Hamed},doi = {10.57967/hf/0955},month = aug,title = {{HLS Multi Temporal Crop Classification}},url = {https://huggingface.co/ibm-nasa-geospatial/multi-temporal-crop-classification},year = {2023} }
网址推荐
推荐两个网址一个是机器学习的另外一个是0代码地图应用创建
Mapmost login
前言 – 人工智能教程
这篇关于NASA和IBM联合开发的 2022 年多时相土地分类数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




