本文主要是介绍灰度发布难以追踪?你可能用错了工具,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
灰度发布进行可观测性的主要方式是通过收集和分析用户在使用新版本产品或服务时的数据,以此来评估新版本的性能、稳定性和用户满意度。这个过程通常包括以下几个步骤:
- 定义观测指标:首先,需要定义一套合适的观测指标(Metrics),这些指标应该能够全面反映新版本的性能、稳定性和用户满意度。常见的观测指标可能包括错误率、响应时间、用户活跃度、用户反馈等。
- 收集数据:在灰度发布期间,需要收集目标用户群在使用新版本产品或服务时产生的数据。这些数据可以通过各种方式收集,例如通过日志记录、用户反馈系统、第三方监控工具等。
- 分析数据:收集到数据后,需要对其进行分析,以评估新版本的性能和用户满意度。这个过程可能涉及到数据清洗、数据可视化、统计分析等多个步骤。
- 决策调整:基于数据分析的结果,产品团队可以决定是否需要对新版本进行调整或优化。如果需要调整,可以通过修改代码、调整配置等方式进行。
- 持续监控:灰度发布期间,需要持续监控新版本的性能和用户满意度,以确保其稳定运行。如果发现任何问题或风险,需要及时进行处理。
在这个过程中,灰度发布和可观测性相辅相成。灰度发布使得产品团队可以将新版本的产品或服务逐步推向目标用户群,而可观测性则帮助团队实时了解新版本的性能和用户满意度,从而做出正确的决策和调整。通过这种方式,产品团队可以更好地控制发布风险,提高产品质量和用户满意度。
通常情况下,一般采用添加 header 方式来设置灰度标识,不同的接口标记为不同的 header,但实际上,header 本身不具备透传。在较为复杂的业务当中,由于请求链条过长,涉及组件较多,过程则表现为难以追溯,耗时耗力,效果堪忧。为了解决这一问题,一般 APM 厂商都会提供类似 Baggage功能,让特定的 tag 无限的传递下去,从而实现全链路追踪。
场景
现在有一个 java 语言编写的服务接口需要做升级优化,为了确保原来的接口有用,也需要保证新的接口也可以使用,故需要做一次灰度发布。
场景设置
- 让一部分用户正常访问接口(端口
8091) - 让一部分用户访问新的接口(端口
8092) - 并设置相应的 header(
test-flag),以便业务追踪
准备工作
- 免费注册观测云帐号,注册后会有免费的使用额度。
- 安装 DataKit,安装成功后,大概一两分钟在观测云就可以看到主机相关信息。
- DDTrace Agent 下载地址
- 准备灰度发布的应用,实践 Demo
- 开启 DDTrace 采集器
DDTrace 采集器用于采集链路信息,进入到 DataKit 安装目录下,执行 conf.d/ddtrace/ ,复制 ddtrace.conf.sample 并重命名为 ddtrace.conf ,在 ddtrace.conf 配置新增 customer_tags=["test_flag"] ,将对应的 Baggage 转化为 tag 。
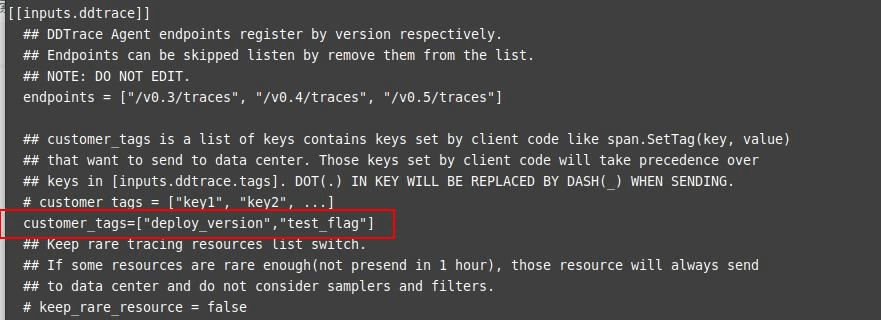
应用
调整应用的启动命令,假设端口 8091 为旧的接口应用。
java \
-javaagent:/home/liurui/agent/dd-java-agent-1.30.1-guance.jar \
-Ddd.service.name=server \
-Ddd.trace.header.baggage=test-flag:test_flag \
-Dserver.port=8091 \
-jar springboot-server.jar
端口 8092 为优化后的接口应用。
java \
-javaagent:/home/liurui/agent/dd-java-agent-1.30.1-guance.jar \
-Ddd.service.name=server \
-Ddd.trace.header.baggage=test-flag:test_flag \
-Dserver.port=8092 \
-jar springboot-server.jar --client=true
启动参数上基本上没啥区别。8092 添加了 --client=true ,会对请求造成异常,假设这个是新的代码调整。
Nginx 配置
采用 nginx 来实现业务分流操作,比如 user_agent 为 curl 的,让请求新的接口,其他的走原来的通道。同时追加 header,方便进行追踪。如 user_agent 为 curl 的相关请求,将自定义 header 值设置为 20240306 ,其他默认值为 normal 。
map $http_user_agent $custom_header { ~*curl "20240306";default "normal";
}
将 user_agent 为 curl 的请求分流到 backend2 ,默认分流到 backend1 。
set $upstream_name 'backend1';
if ($http_user_agent ~* "curl") { set $upstream_name 'backend2';
}proxy_pass http://$upstream_name;
根据不同的 upstream_name 设置不同的 header 值。
proxy_set_header Test-Flag $custom_header; # 根据 upstream 地址设置不同的值
两个 upstream 。
upstream backend1 { server localhost:8091; } upstream backend2 { server localhost:8092; }
通过 nginx -s reload 重启 nginx 。至此,nginx 配置基本上完成。
root:/etc/nginx/conf.d# nginx -s reload
info: DATADOG TRACER CONFIGURATION - {"agent_url":"http://localhost:9529","analytics_enabled":false,"analytics_sample_rate":null,"date":"2024-03-06T15:30:24+0800","enabled":true,"env":"prod","lang":"cpp","lang_version":"201402","operation_name_override":"nginx.handle","report_hostname":false,"sampling_rules":"[]","service":"nginx","version":"v1.3.7"}
这里 nginx 接入了 ddtrace,非必须,如有需要,可参考文档 Nginx Tracing 。
Nginx 全文配置如下:
map $http_user_agent $custom_header { ~*curl "20240306";default "normal";
}
upstream backend1 { server localhost:8091;
}
upstream backend2 { server localhost:8092;
} server {listen 80;server_name www.springboot.com;client_max_body_size 100m;location ^~ / {set $upstream_name 'backend1'; if ($http_user_agent ~* "curl") { set $upstream_name 'backend2'; } add_header 'Access-Control-Allow-Origin' *;add_header 'Access-Control-Allow-Credentials' 'true';add_header 'Access-Control-Allow-Methods' 'GET,POST,OPTIONS';proxy_pass http://$upstream_name;proxy_set_header X-datadog-trace-id $opentracing_context_x_datadog_trace_id;proxy_set_header X-datadog-parent-id $opentracing_context_x_datadog_parent_id;proxy_set_header X-Real-IP $remote_addr;proxy_set_header Host $http_host;proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;proxy_set_header Test-Flag $custom_header; # 根据 upstream 地址设置不同的值}error_page 500 502 503 504 /50x.html;location = /50x.html {root html;}}
测试
分别通过浏览器和 curl 请求接口 http://www.springboot.com/gateway 。其中 curl 返回结果如下:
root:/etc/nginx/conf.d# curl www.springboot.com/gateway
{"msg":"client 调用失败","code":500}
浏览器请求则返回如下信息:
{"msg":"支付成功","code":200}
从观测云上通过链路追踪,可以发现所有的 span 都有 tag 为 test_flag ,其中值为 20240306 的链路为本次新发布的接口。
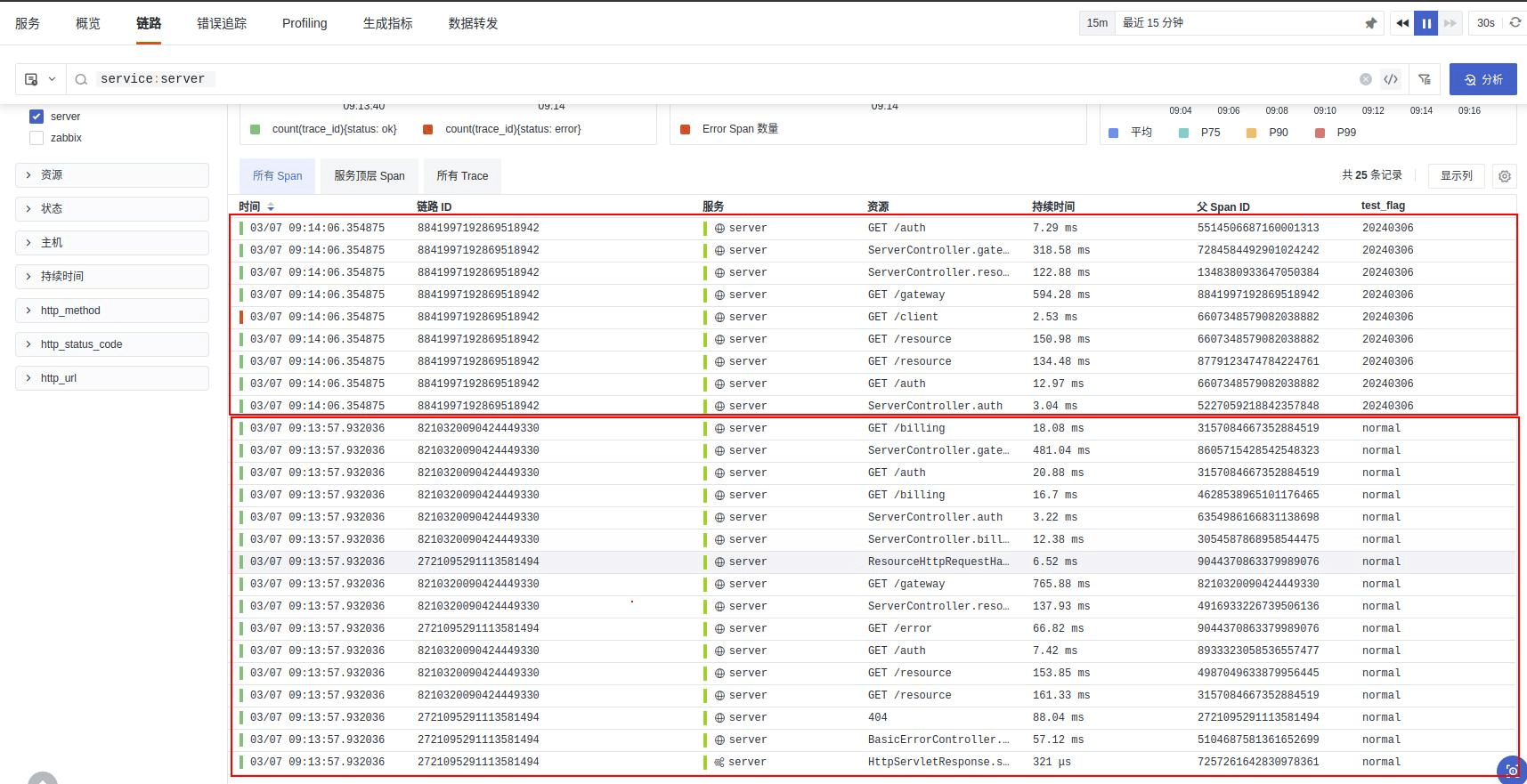
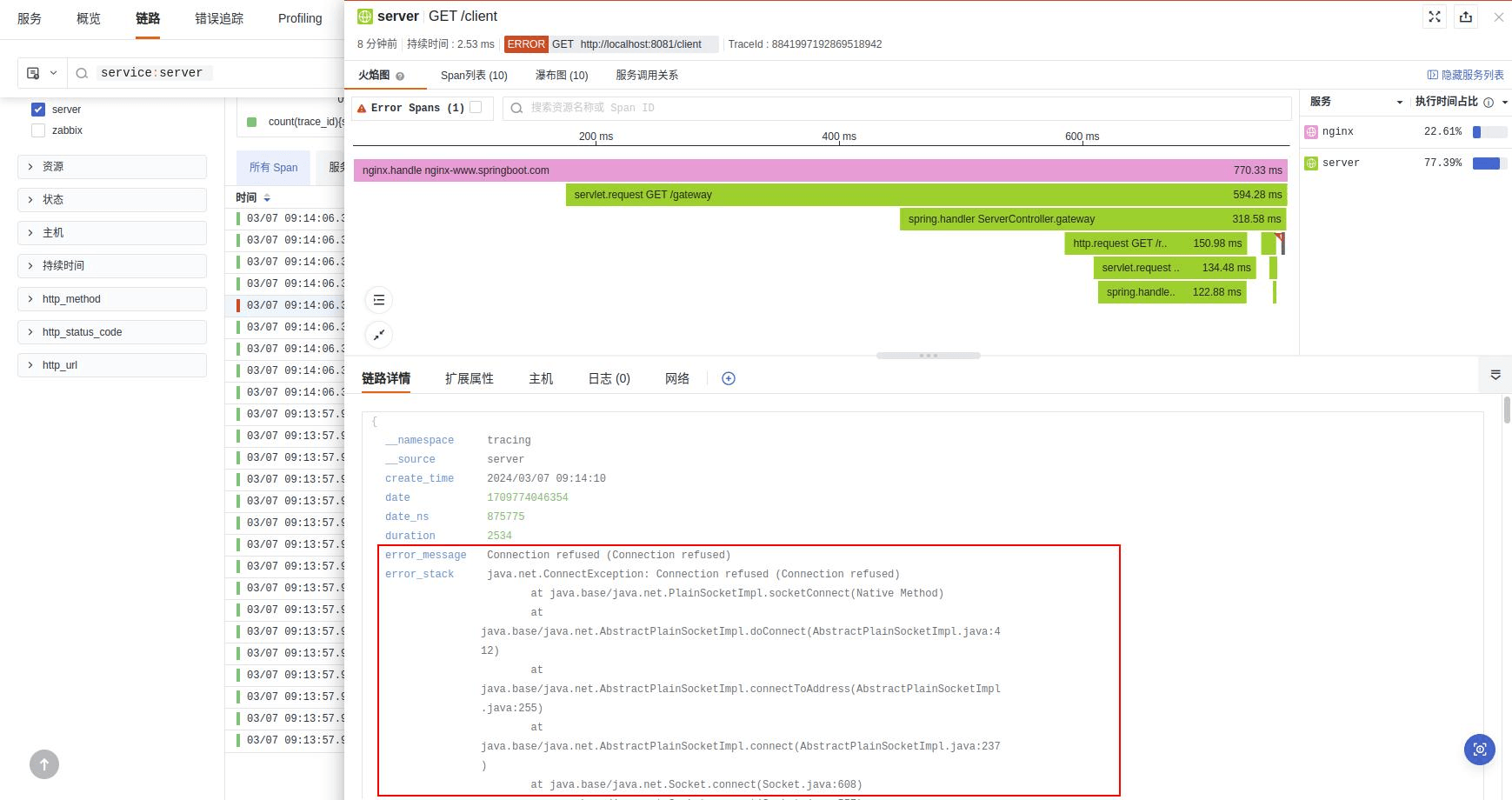
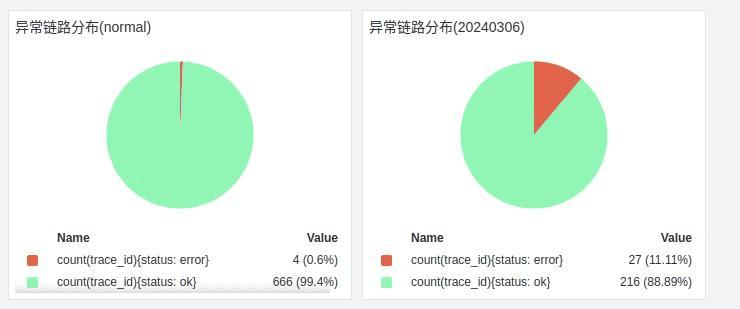
红色标记代表异常,说明当前链路处于异常状态。通过查看链路详情可以查看到堆栈信息,最终根据调整的代码进行再次发布,通过同样的方式进行再追踪、再验证。
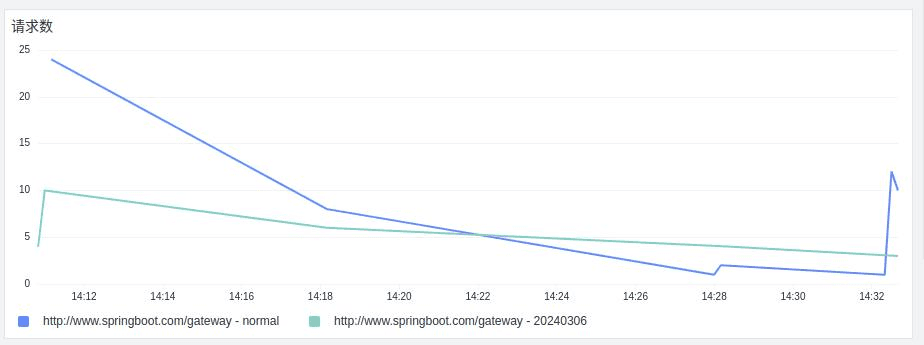
- 对比灰度前后url请求耗时情况
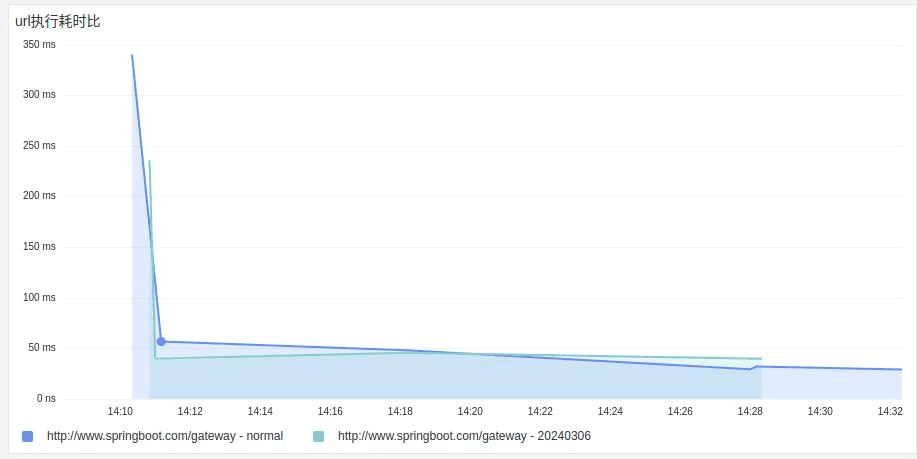
- 灰度前后的应用的请求分布
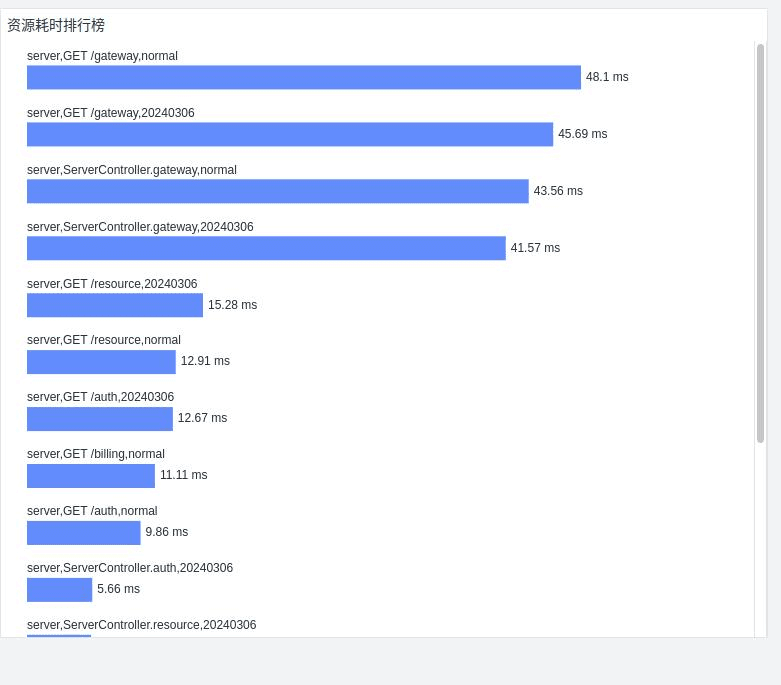
- 灰度前后资源耗时排行
- 灰度前后异常链路分布占比
后记
以上实践只是灰度发布的一部分,但笔者认为这是最核心、最重要的:确保业务的更新和正常使用。如何更有效率的确保发版成功,则需借助可观测性能力,让一切变得肉眼可见。
这篇关于灰度发布难以追踪?你可能用错了工具的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







