本文主要是介绍Linux——文件缓冲区与模拟实现stdio.h,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
我们学习了系统层面上的文件操作,也明白了重定向的基本原理,在重定向中,我们使用fflush(stdout)刷新了缓冲区,当时我们仅仅知道重定向需要刷新缓冲区,但是不知道其所以然,今天我们来见识一下。
一、缓冲区
缓冲区的本质就是内存的一部分,C标准库提供了他的缓冲区,操作系统也有自己的缓冲区,我们绝大部分使用的缓冲区是C/C++的缓冲区。
大家看如下代码,理解一下缓冲区的作用
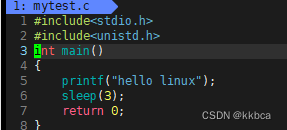

明明代码中hello linux在前面,休眠在后面,按道理应该是先打印内容,再进行休眠才对,这里等到睡眠结束才打印出来结果。这就是缓冲区在从中起作用。
举个例子
我在重庆,我的朋友在四川,当我想要给他一箱娃哈哈AD钙奶的时候, 如果我开车屁颠屁颠的送过去,确保再他手上之后再返回,效率就会十分低下,如果我将AD钙奶给菜鸟驿站,让菜鸟驿站帮我送过去,虽然时间没有变快,但是效率肯定变高了(驿站会存很多快递一起往四川寄过去)
其中,菜鸟驿站就是缓冲区,缓冲区的作用就是提高使用者的效率,同时因为有缓冲区的存在,我们积累了一部分再统一发送,这也变相的提高了发送的效率。
二、缓冲区的刷新方式
缓冲区能够暂存数据,那么他肯定有相应的刷新策略
一般策略
1.无缓冲(立即刷新)
2.行缓冲(行刷新)
3.全缓冲(缓冲区满了,再刷新)
特殊情况
1.用户输入fflush(),强制刷新。
2.进程退出的时候,也要进行刷新缓冲区。
对于一般显示器文件,采用行缓冲的策略
对于磁盘上的文件,采用全缓冲的策略
三、缓冲区的样例
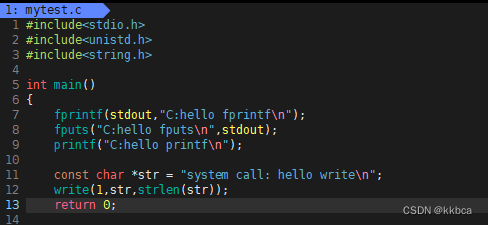
执行,打印出结果,我们选择重定向到文件中,发现打印顺序不一样。

我们在最后面添加上fork,按道理打印应该跟之前一样

这里打印到显示器是正常现象,重定向到文件中竟然超级加倍了
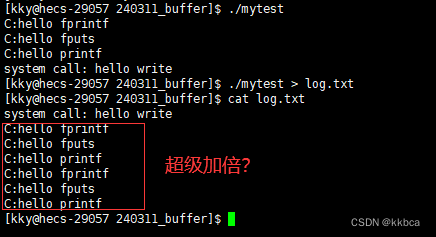
明明fork在最后,fork之后没有代码需要执行的,为什么C提供的打印会打印双份,而系统调用依然是只有一个。
我们一步步分析
1.显示器文件的刷新策略是行刷新,我们在显示器上打印都是带了‘\n’,fork之前,数据已经全部被刷新,包括系统调用接口。
2.重定向到log.txt,本质是向磁盘进行写入,刷新方式由行刷新变成了全缓冲。
3.全缓冲意味着缓冲区变大,写入的数据不足以将缓冲区填满,fork执行后,数据依然在缓冲区中,没有刷新出去。
4.这里谈到的缓冲区,是C语言提供的缓冲区,跟操作系统没关系(因为系统调用打印并没有加倍,C加倍了,一定跟C脱不了关系)
5.C/C++提供的缓冲区,里面一定保存了用户的数据,这属于当前进程自己的数据,如果缓冲区刷新,将数据交给了操作系统,就由操作系统来帮我们处理了,不属于当前进程了。
6.当进程退出时,一般都要强制刷新缓冲区。
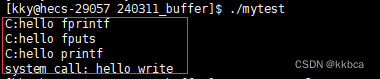
根据上述内容,我们小总结一下
fork之后,数据仍在C语言的缓冲区中,属于当前进程自己的数据,那么fork之后,父子进程代码和数据共享,同时父子进程陆续退出,退出时会刷新缓冲区(将数据给操作系统——也算写入),就会发生写时拷贝,父给操作系统一份,子也会给操作系统一份,因此会打印两份内容!!!
而write系统调用,没有使用C语言的缓冲区,直接写入到操作系统中,并不属于该进程,因此不会写时拷贝。
那么你兜兜转转说了这么多,还没说什么叫刷新?为什么重定向到文件中,write先行打印?
从C语言缓冲区写入到操作系统内部称为刷新,而write函数,根本没有经过C语言缓冲区,直接在操作系统内部,因此重定向时 write 先打印!!!
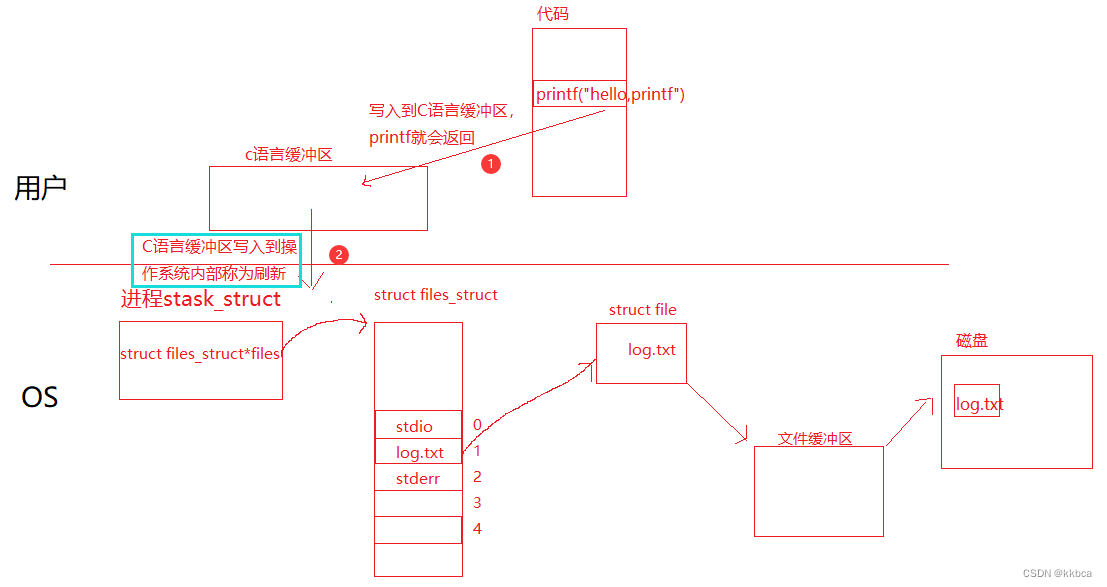
C语言搞缓冲区出来就是为了提高效率,C语言追求的就是效率,姿势可以不帅,但速度一定要快,写入到C语言缓冲区速度要比写入到操作系统快多了,写入完成直接返回运行后续代码了,直到写满了缓冲区或者进程退出时,一起将缓冲区的内容再写到操作系统中。
而后续操作系统中给每一个文件也设置了文件缓冲区,操作系统再根据他自己的刷新策略进行刷新,写入到磁盘中,和用户已经没关系了。
四、C语言缓冲区在哪
说了这么多,我也知道缓冲区确实存在,那他到底在哪里呢?
答案是在FILE结构体里,我们输入输出都要有一个FILE,像printf函数,虽然传参不需要FILE,但他内部一定封装了

比如,当我们进行scanf输入的时候,我们输入的字符都会被暂存到stdin的缓冲区中,再根据输入的%d或者其他格式,帮我们转化。
五、简易的stdio.h
我们写简单一点,目的是帮助我们更好理解缓冲区和重定向,只需要四个函数,fopen,fclose,fprintf,fflush。
1.mystdio.h
那么mystdio.h头文件如下,MyFile结构体中,有fileno,flag,buffer,end。

2.mystdio.c
my_fopen函数,首先先判断方式为“r”、“w”、“a”,还是其他,如果flag中有O_CREAT,则open打开文件需要添加权限掩码。malloc开辟MyFile空间,同时初始化一下。

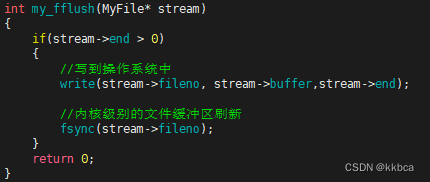
my_fflush函数刷新,使用write写到操作系统中
my_fwrite函数,先使用memcpy从s里面把数据拷贝到buffer(不用strcpy是不拷贝"\0"),判断刷新方式与end大小,看看是否需要刷新,循环遍历‘\n’,防止出现str = "abcd\nefg"的情况。发现 '\n' 就先处理end大小,再退出循环开始刷新,后面再将str中\n后面的数据拷贝回buffer的起始位置,再处理end。

my_fclose函数简单,退出前先刷新一下就可以了,再调用close。

3.main.c
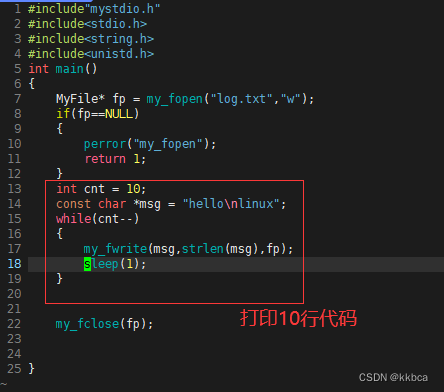
结果如下,每次遇到 '\n' 都会进行缓冲区的刷新。 因此总是在hello后面进程刷新
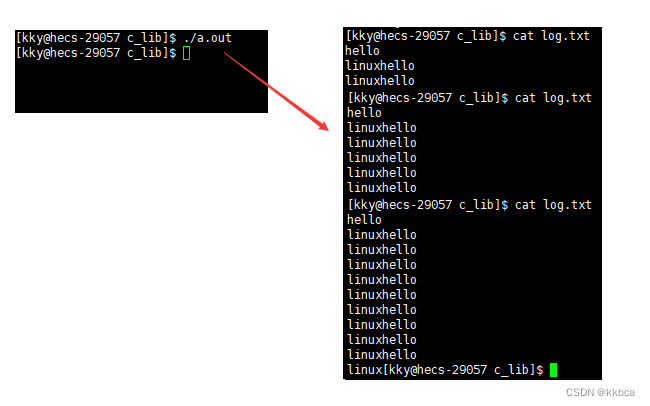
通过模拟的方式能帮我们更好理解缓冲区的概念。
最后附上总代码
mystdio.h
#pragma once#define SIZE 4096
#define FLUSH_NONE 1
#define FLUSH_LINE 2
#define FLUSH_ALL 4
typedef struct _MyFile
{int fileno; //文件描述符int flag; //刷新方式char buffer[SIZE]; //缓冲区int end; //缓冲区大小
}MyFile;MyFile *my_fopen(const char* path,const char* mode);int my_fwrite(const char* s, int num,MyFile *stream);int my_fflush(MyFile* stream);int my_fclose(MyFile* stream);
mystdio.c
#include "mystdio.h"
#include<string.h>
#include<sys/types.h>
#include<sys/stat.h>
#include<fcntl.h>
#include<unistd.h>
#include<errno.h>
#include<stdlib.h>
MyFile *my_fopen(const char* path,const char* mode)
{ int fd = 0; int flag = 0; if(strcmp(mode,"r")== 0) { flag |= O_RDONLY; } else if(strcmp(mode,"w")==0) { flag |= O_WRONLY|O_CREAT|O_WRONLY; } else if(strcmp(mode,"a")==0) { flag |= O_WRONLY|O_CREAT|O_APPEND; } else{ //其他模式 } if(flag & O_CREAT) { fd = open(path,flag,0666); } else { fd = open(path,flag); } if(fd < 0) { errno = 2; return NULL; } MyFile* fp = (MyFile*)malloc(sizeof(MyFile)); if(!fp) { errno = 3; return NULL; } fp->flag = FLUSH_LINE; fp->end = 0; fp->fileno = fd; return fp;
}
int my_fwrite(const char* s,int num,MyFile *stream)
{memcpy(stream->buffer+stream->end,s,num);stream->end += num;//判断是否需要刷新if((stream->flag & FLUSH_LINE)&&stream->end>0){int i = 0;int len = 0;//记录\n后还有几个字符for(;i<stream->end;i++){if(stream->buffer[i]=='\n'){len = stream->end - i - 1;stream->end = i+1;break;}}my_fflush(stream);memcpy(stream->buffer,stream->buffer+i+1,len);stream->end = len;}return num;
}
int my_fflush(MyFile* stream)
{if(stream->end > 0){//写到操作系统中write(stream->fileno, stream->buffer,stream->end);//内核级别的文件缓冲区刷新 fsync(stream->fileno); }return 0;
}
int my_fclose(MyFile* stream)
{my_fflush(stream);return close(stream->fileno);
}main.c
#include"mystdio.h"
#include<stdio.h>
#include<string.h>
#include<unistd.h>
int main()
{ MyFile* fp = my_fopen("log.txt","w"); if(fp==NULL) { perror("my_fopen"); return 1; } int cnt = 10; const char *msg = "hello\nlinux"; while(cnt--) { my_fwrite(msg,strlen(msg),fp); sleep(1); } my_fclose(fp); return 0;
}谢谢大家观看!!!!
这篇关于Linux——文件缓冲区与模拟实现stdio.h的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




