本文主要是介绍跨越微服务边界:Spring Cloud Sleuth 如何助力实现无缝分布式追踪,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spring Cloud Sleuth 是一款基于 Spring Cloud 架构的微服务追踪工具,旨在解决微服务架构中分布式追踪的问题。在微服务架构中,由于服务之间高度解耦且相互调用频繁,单一请求可能涉及多个服务间的协作,当需要对某个请求的完整处理流程进行监控、性能分析或故障排查时,就需要能够追溯请求在各个服务中的流转路径和耗时。
今天就来介绍一下微服务的链路追踪问题。首先来看下 Spring Cloud 的组件:

一、为什么需要链路追踪
可以想象这样一个场景,你负责一个庞大的微服务系统,每个服务都有复杂的上下游调用关系,而且并发量还不小,每秒上万的 QPS。
在这个微服务系统中,用户访问系统后,这个用户请求会先抵达微服务网关组件,然后网关再把请求分发给各个微服务。所以你会发现,用户请求从发起到结束要经历很多个微服务的处理,这里面还涉及到消息组件的集成。
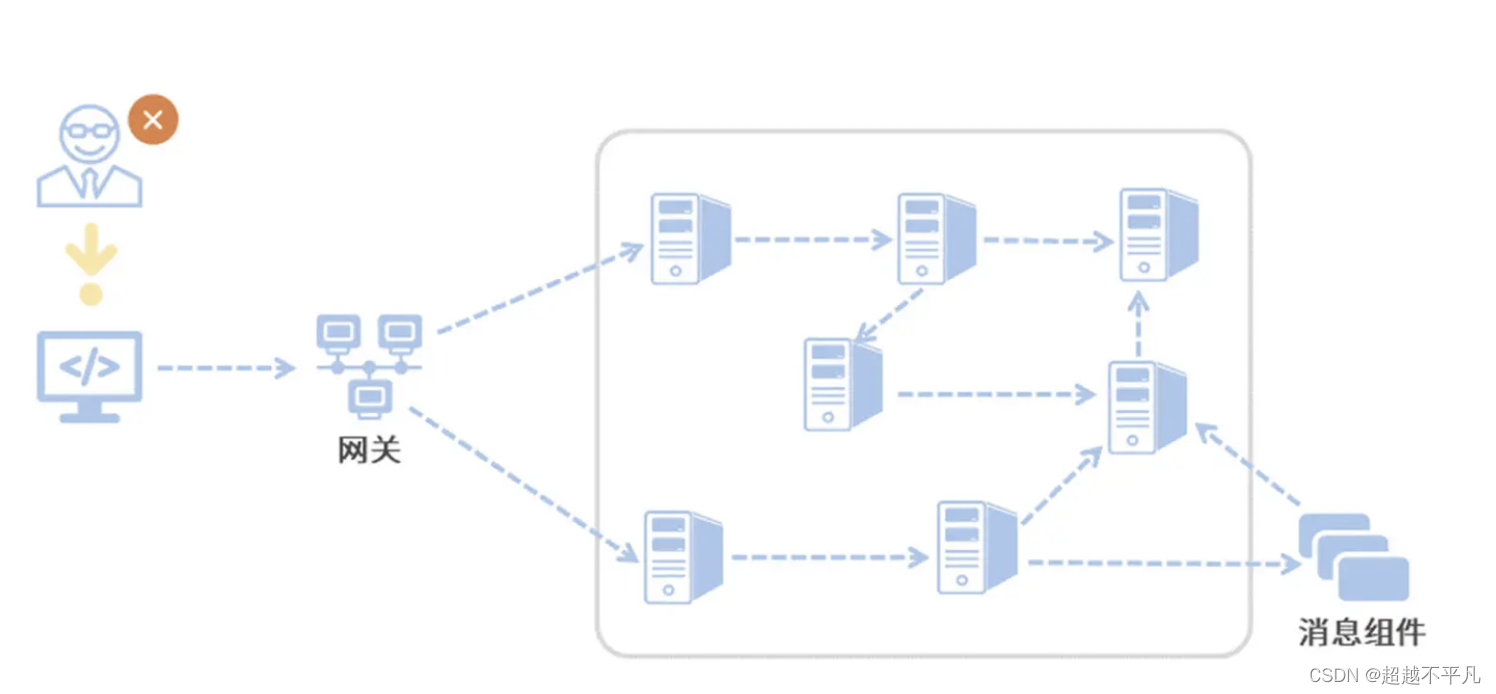
现在问题来了,突然有一天,来了一个客诉,说他在页面端看到了一个报错,每次查询都会报一个 500 错误。如果问题被交到了你手上,你该怎么排查呢?
作为开发人员我们知道 500 错误是 Internal Server Error,这个异常可能发生在任何阶段,就算在同一时刻也可能有多条不同服务的 Error 日志。在一个没有链路追踪的微服务系统里,线上 Bug 排查无异于大海捞针,因为你根本无法梳理出一次请求的前后调用链。
因为缺少用户请求唯一标识之类的唯一主键,你就很难缩小排查范围,只能耗费大量的时间用肉眼走查每一条日志。你需要找到用户所有请求记录的起始 log,从前往后挨个摸排,从蛛丝马迹中梳理服务调用之间的关系并定位最终的问题,可见这种方式十分低效。
如果你想提高线上异常排查的效率,那么首先要做的一件事就是:将一次调用请求中所有访问到的微服务日志前后串联起来。只要你找到了本次调用的任何一条日志,你就可以将前后的关联日志信息全部找到。这就是“调用链追踪”技术要完成的工作了。
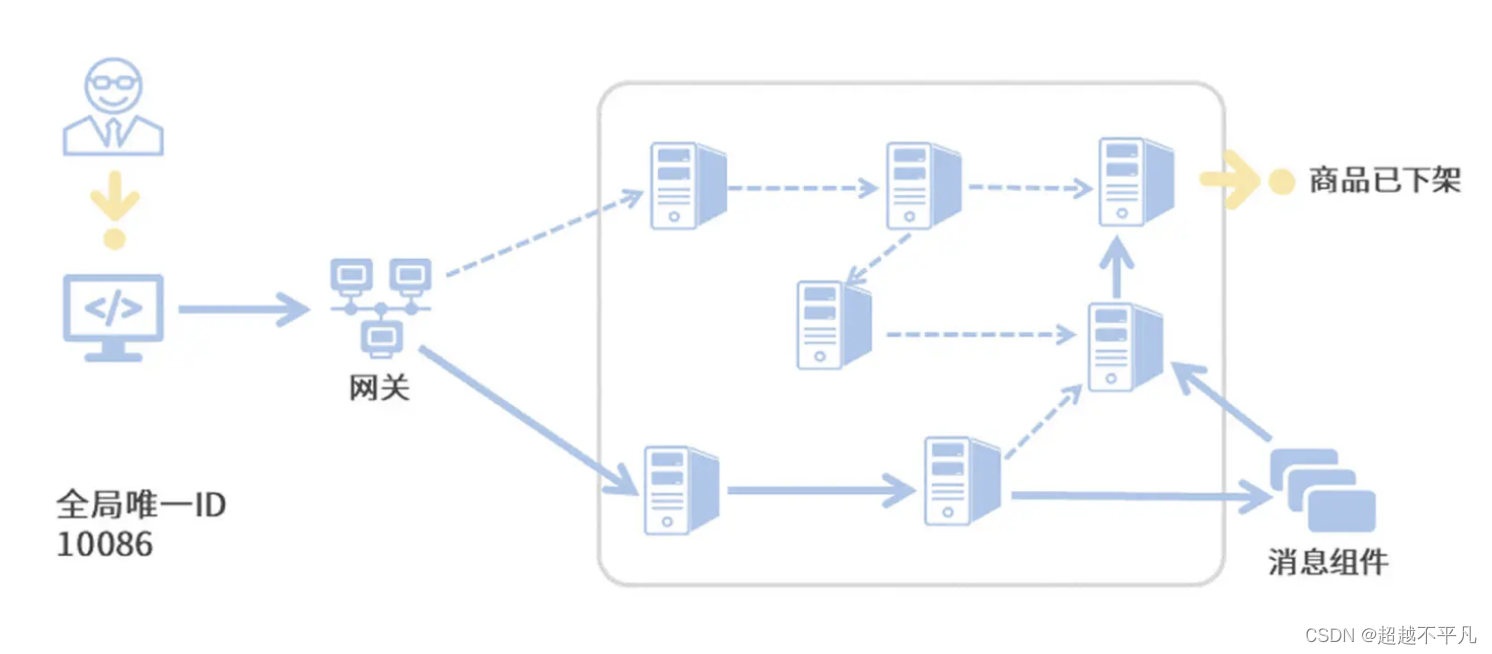
那调用链追踪是如何实现日志信息串联的呢?简单来说,链路追踪技术会为每次服务调用生成一个全局唯一的 ID(后面我们叫它 Trace ID),从本次服务调用的起点到终点,这个过程中的所有日志信息都会被打上 Trace ID 的烙印。这样一来,根据日志中的 Trace ID,我们就能很清晰地梳理出一次服务请求前后都经过了哪些微服务节点。
就像下面这张图一样,我们将调用链追踪应用到线上 Bug 排查的场景之后,一整条调用链(实线箭头)已是跃然纸上。我们只要找出当前用户请求的任意一条日志,就能根据这条日志中的 Trace ID 将整个调用链拎出来,到底是哪个服务调用环节的异常导致了用户下单失败,我们也就一目了然了。
接下来,我就带你了解一下 Spring Cloud 的链路追踪组件 Sleuth 是如何实现链路追踪的,也就是分析它的底层逻辑。
二、项目集成 Sleuth
添加依赖
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-sleuth</artifactId><!-- 根据您使用的 Spring Cloud 版本选择合适的版本 --><version>YOUR_SPRING_CLOUD_VERSION</version>
</dependency><!-- 如果您打算将追踪数据发送到 Zipkin,请添加对应依赖 -->
<dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-zipkin</artifactId><!-- 同样根据 Spring Cloud 版本选择相应 Zipkin 版本 --><version>YOUR_ZIPKIN_VERSION</version>
</dependency>在配置文件中配置 Sleuth 相关信息
# Sleuth 相关配置
spring.sleuth.enabled=true
spring.application.name=your-service-name
启动应用程序后,Sleuth 将自动为您的服务启用分布式追踪功能,并将追踪数据发送到配置的 Zipkin 服务器。
服务被调用了就能看到链路追踪了,就这么简单。
三、Sleuth 的底层逻辑
链路追踪有两个任务,一个是标记出调用请求中的所有日志,另一个是梳理出调用链中的前后关系。
首先看第一个问题,通过 TraceId 就能标记出请求链路中的所有日志,用 TraceId 来完成第一个任务。不过 TraceId 并不能表达服务间调用的前后关系。那 Sleuth 是如何解决第二个问题的呢?
Sleuth 通过在 log 中打入特殊标签来串联前后日志。集成了 Sleuth 组件后,它会向你的日志中打入 3 个特殊的标记,其中一个标记就是上边提到的 TraceId。剩下的两个标记分别是 Span ID 和 Parent Span Id,这俩用来表示调用的前后关系。
所谓 Span,它是 Sleuth 下面的一个基本工作单元,当服务请求抵达当前单元时,Sleuth 就会为这个单元分配一个独一无二的 Span ID,并标记单元的开始时间和结束时间,这样就可以记录每个单元的处理时间。
而 Parent Span ID,它指向了当前单元的父级单元,也就是上游的调用者。一个环环相扣的调用链就通过 Parent Span ID 被串了起来。
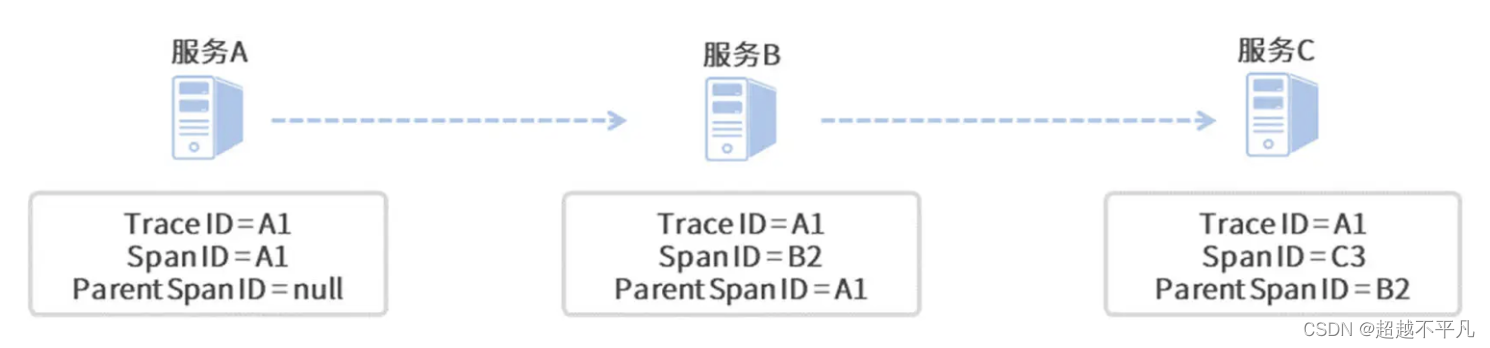
在一条调用链中,不管你调用了多少个微服务,Sleuth 为本次调用生成的全局唯一 Trace ID 都会贯穿整个链路,图中三个微服务所对应的日志 Trace ID 都是 A1。
由于服务 A 是调用链的起点,所以它并没有父级单元,因此它的 Parent Span ID 为空,而起始单元的 Span ID 和 Trace ID 则是相同的,值都为 A1。
对于服务 B 来说,它的父级调用单元是服务 A,因此它的 Parent Span ID 指向了服务 A 的 Span ID,即 A1;同理,服务 C 的 Parent Span ID 指向了服务 B 的 Span ID,即 B2。
当然了,除了 Trace 和 Span 之外,Sleuth 还有一个特殊的数据结构,叫做 Annotation,被用来记录一个具体的“事件”。
3.1 使用 Sleuth 注意事项
使用 Spring Cloud Sleuth 进行分布式追踪时,需要注意以下几点:
- 依赖版本匹配:确保所有微服务使用的 Spring Cloud Sleuth 以及其他相关组件(如 Zipkin 或 OpenTelemetry)版本一致或兼容
- 追踪上下文传播:在微服务之间通过 REST、gRPC、RabbitMQ、Kafka 等方式进行通信时,确保追踪上下文(如 Trace ID 和 Span ID)能够在服务间正确地传递。特别是对于非 HTTP 协议,可能需要额外的配置和处理器来保证上下文传播。
- 采样策略:根据实际情况设定合理的采样率,避免因为全量追踪产生过大的数据量。可以通过配置 Sleuth 的 Sampler 来决定哪些请求会被记录和上报到追踪系统。
- 日志配置:若要将追踪信息与日志关联起来,确保 Sleuth 与使用的日志框架(如 Logback 或 Log4j2)正确集成,并在日志格式中包含追踪上下文信息。
- 服务注册发现的影响:若应用了服务注册与发现组件(如 Nacos 或 Consul),确保 Sleuth 能够识别到正确的服务名,以便在追踪系统中展示有意义的服务调用链路。
- 性能考量:虽然 Sleuth 对性能的影响通常较小,但在高并发场景下仍需关注追踪开销,适当调整采样策略或优化追踪代码。
总是 Slueth 是微服务中链路追踪的利器,实际上其功能远不止于此,更多深入的功能可以根据实际项目需求探索并利用其 API 进行扩展。随着 Sleuth 对 OpenTelemetry 的支持加强,其高级特性还包含了许多符合云原生时代标准的可观测性能力。
往期经典推荐:
微服务韧性工程:利用Sentinel实施有效服务容错与限流降级-CSDN博客
一文看懂Nacos如何实现高效、动态的配置中心管理-CSDN博客
SpringBoot项目并发处理大揭秘,你知道它到底能应对多少请求洪峰?_springboot并发处理-CSDN博客
决胜高并发战场:Redis并发访问控制与实战解析-CSDN博客
Redis性能大挑战:深入剖析缓存抖动现象及有效应对的战术指南_redis 缓存抖动怎么解决-CSDN博客
这篇关于跨越微服务边界:Spring Cloud Sleuth 如何助力实现无缝分布式追踪的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





