本文主要是介绍python自动爬取数据,制作简报,推送到个人微信,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求场景
每天早上需要从后台查询统计前一日的销售情况,并将结果发送至微信群。由于样式固定,基本都是重复操作,于是用python编写了一个脚本,定时查询、统计并推送。基本流程如下:
-
定时刷新后台保持登录状态
-
每天早8点查询后台数据
-
统计分析并推送至微信
下面是相关脚本,稍微修改即可直接使用。
二、登录保持和数据采集脚本
import requests
import threading
import time
from datetime import datetimedef visit_url(url, method, data, cookie):headers = {'Cookie': cookie,'Content-Type': 'application/x-www-form-urlencoded;charset=UTF-8'}if method == "GET":response = requests.get(url, headers=headers)elif method == "POST":response = requests.post(url, headers=headers, data=data)return response.textdef keep_login(url, cookie, interval):while True:print(f"{datetime.now()} : 访问 {url} 以保持登录状态")visit_url(url, "GET", None, cookie)time.sleep(interval)def visit_url_periodically(url, method, data, cookie, target_time):while True:current_time = datetime.now().strftime("%H:%M")current_time_obj = datetime.strptime(current_time, "%H:%M")target_time_obj = datetime.strptime(target_time, "%H:%M")time_diff = (current_time_obj - target_time_obj).secondsif time_diff < 60:print(f"{datetime.now()} : 访问 {url} 并将结果写入 output.txt")response_text = visit_url(url, method, data, cookie)with open("output.txt", "w") as file:file.write(response_text)time.sleep(60) # 每隔一分钟检查一次是否到达目标时间def main():# 设置网址和cookie,根据实际情况修改url1 = "http://xxx/main"url2 = "http://xxx/finance/getSellList"cookie = "JSESSIONID=CC99B8FB01ED15EAFA5DA612CC217CDB"# 设置循环间隔时间(秒)interval = 300 # 5分钟# 创建并启动保持登录的线程login_thread = threading.Thread(target=keep_login, args=(url1, cookie, interval))login_thread.start()# 准备访问url2的参数,数据查询参数,可通过浏览器F12查看修改url2_data = {'timeStart': '2023-11-27','timeEnd': '2023-11-27','id': '233','mode': '1','start': '0','length': '15'}# 创建并启动定时访问url2的线程visit_thread = threading.Thread(target=visit_url_periodically, args=(url2, "POST", url2_data, cookie, "08:00"))visit_thread.start()if __name__ == "__main__":main()
keep_login函数为登录状态保持脚本,visit_url_periodically函数为数据采集脚本。修改main函数中的url1、url2、cookie、url2_data后可直接使用。
采集的数据为json格式,示例如下:
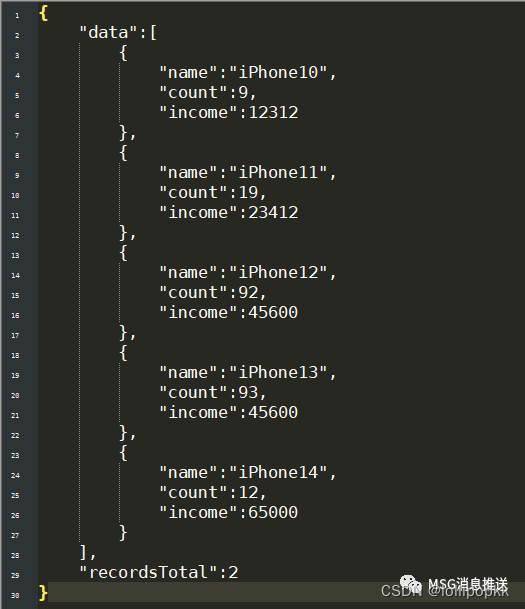
三、数据统计分析脚本
import json
import requests# 从output.txt读取json文件
with open('output.txt', 'r') as file:data = json.load(file)# 格式化编排内容
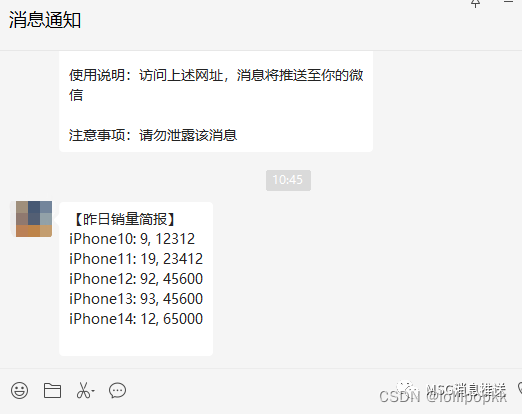
formatted_content = '【昨日销量简报】\n'
for item in data['data']:formatted_content += f"{item['name']}: {item['count']}, {item['income']}\n"# 发送编排的内容
# yourtoken 获取方式见底部介绍
url = f"https://cglapp.top/api/wxpush/txt?token={yourtoken}&msg={formatted_content}"
response = requests.get(url, verify=False) # 忽略证书问题print(response.text)
Windows设置定时任务,定时执行上述脚本,即可推送简报至微信。
四、配置定时运行
-
打开“控制面板”。
-
在控制面板中,选择“管理工具”。
-
在“管理工具”中,找到并打开“任务计划程序”。
-
在任务计划程序窗口中,选择“创建基本任务”或“创建任务”(具体名称可能略有不同)。
-
在弹出的窗口中,输入任务的名称和描述,然后点击“下一步”。
-
选择触发器,选择“每天”,并设置执行时间为早上8:05。然后点击“下一步”。
-
选择“启动程序”作为操作,然后在“程序/脚本”处输入Python解释器的路径(通常是类似于C:\Python\python.exe的路径),并在“参数”处输入要运行的Python脚本的路径。然后点击“下一步”。
-
在最后的确认页面上,检查任务设置是否正确,然后点击“完成”。
-
每天早上8:05执行Python脚本的定时任务设置完成。
五、个人微信配置方式
【教程】文本消息推送服务接入说明
这篇关于python自动爬取数据,制作简报,推送到个人微信的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


