本文主要是介绍谣言检测数据集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
下面的数据集链接,大家如果打不开的话,建议打开VPN,上外网下载哦!
1 PHEME-R
这是一个在PHEME FP7项目的新闻学用例中收集和注释的数据集。这些谣言与9个不同的突发新闻相关。它是为分析社交媒体谣言而创建的,包含由谣言推文发起的推特对话;对话包括对这些谣言推文的回应推文。这些推文已经被注解为支持度、确定性和证据性。
该数据集包含330个对话线程(297个英语,33个德语),每个线程都有一个文件夹。
年份:2016
下载链接: PHEME rumour scheme dataset: journalism use case
2 PHEME dataset
这个数据集包含了突发新闻期间发布的Twitter谣言和非谣言的集合。
该数据的结构如下。每个事件都有一个目录,有两个子文件夹,谣言和非谣言。这两个文件夹有以推特ID命名的文件夹。推文本身可以在相关推文的'源推文'目录中找到,而'反应'目录中有回应该源推文的一组推文。同时,每个文件夹都包含'annotation.json',它包含关于谣言的真实性的信息,以及'structure.json',它包含关于对话结构的信息。
该数据集是PHEME谣言和非谣言数据集的延伸(https://figshare.com/articles/PHEME_dataset_of_rumours_and_non-rumours/4010619),它包含了与9个事件相关的谣言,每个谣言都被标注了其真实性值,即真、假或未验证。
时间: 2018年
这个数据集被用在论文“All-in-one: Multi-task Learning for Rumour Verification"。更多细节,请参考该论文。
3 Ma-Twitter
Twitter.txt:这个语料库总共包含992个有标签的事件。每一行都包含一个事件和相关推文的ID:event_id, label, tweet_ids。对于标签,如果该事件是一个谣言,其值为1,否则为0。请注意,由于Twitter数据的使用条款,我们不能公布推文的具体内容。用户可以通过Twitter的API自己下载这些内容。
Twitter_event_claims.txt:这个文件提供了每个事件的主要声明内容。每一行都包含一个事件,其声明由event_id和声明内容组成。在这个文件中,只包括我们自己从Snopes.com上收集的事件的声明,而标为 "未知 "的声明则是从两篇论文中构建的其他数据集(为了平衡我们的类别分布)借来的。
4 Ma-Weibo
微博数据(weibo.txt)。这个语料库总共包含4664个有标签的事件。每一行都包含一个事件和相关帖子的ID,格式为:event_id, label, post_ids。对于标签,如果该事件是一个谣言,其值为1,否则为0。我们还以json格式发布所有帖子的内容,这些内容被保存在./Weibo目录下,每个文件被命名为event_id.json,对应于单个事件。
下载链接:https://www.dropbox.com/s/46r50ctrfa0ur1o/rumdect.zip?dl=0
需要注意的是,我们并没有为每个微博事件明确地产生声明,因为我们直接从新浪社区管理中心收集事件的传播线程,每个事件的源帖(第一篇)可以被视为主要的声明。
5 Twitter 15 和 Twitter 16
两个公开可用的推特数据集。
下载链接:https://www.dropbox.com/s/7ewzdrbelpmrnxu/rumdetect2017.zip?dl=0
介绍:在本文中,我们试图根据微博帖子的传播结构来解决从微博帖子中识别谣言 (即虚假信息) 的问题。我们首先使用传播树对微博帖子的传播进行建模,这些传播树为原始消息的传播和发展提供了有价值的线索。

论文链接:Detect Rumors in Microblog Posts Using Propagation Structure via Kernel Learning
6 BuzzFeedNews
下载链接:https://github.com/BuzzFeedNews/2016-10-facebook-fact-check
你可以在这里找到所有帖子、事实核查评分和 Facebook 参与度数据的电子表格。收集和评价页面的方法可以在主文章的开头和结尾。
Facebook 的参与数据是从2016年10月11日的 Facebook API 中获得的。
论文:"Hyperpartisan Facebook Pages Are Publishing False And Misleading Information At An Alarming Rate,"
数据集格式:
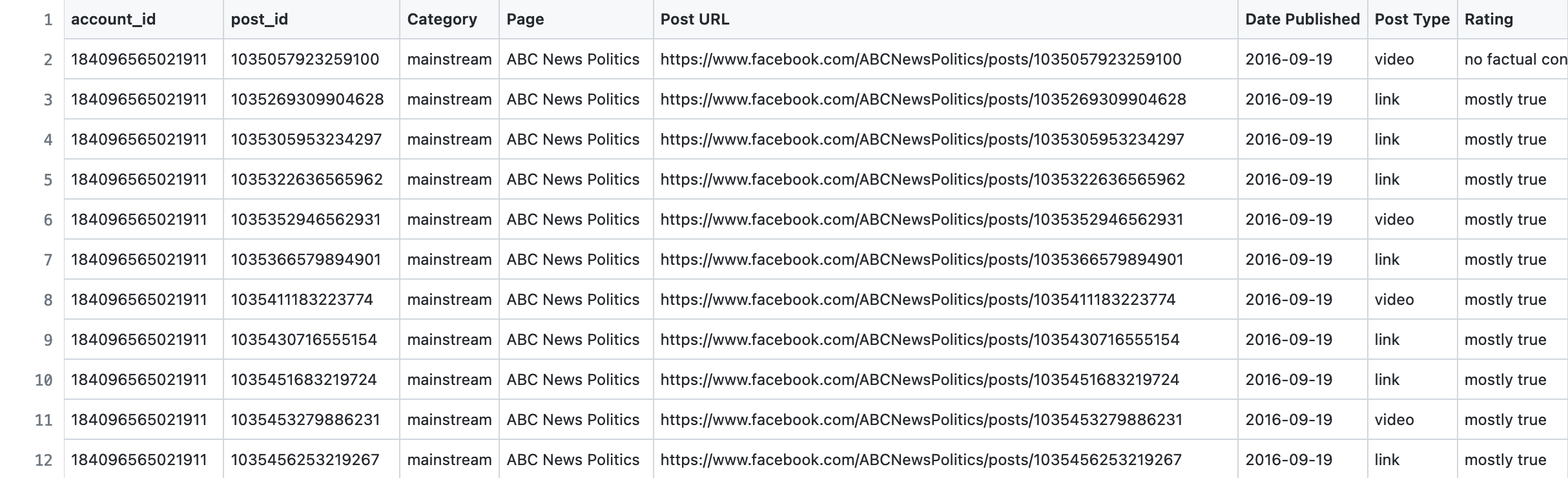
7 SemEval19-2019年 - text/user info/time stamp/ propagation info
论文链接:SemEval-2019 Task 7: RumourEval, Determining Rumour Veracity and Support for Rumours - ACL Anthology
提供了一个可疑帖子和随后在社交媒体中进行对话的数据集,并注释了立场和准确性。社交媒体的谣言源于各种突发新闻,数据集被扩展到包括Reddit以及新的Twitter帖子。
下载链接:RumourEval 2019 data
Task A (SDQC)
与预测谣言真实性的目标有关,第一个子任务将处理跟踪其他来源如何适应谣言故事准确性的补充目标。分析周围话语的关键步骤是确定社交媒体中的其他用户如何看待谣言。我们建议通过查看对提出谣言声明的帖子 (即原始谣言 (来源) 帖子) 的答复来解决这一分析。我们将为参与者提供由回复原始谣言帖子的帖子组成的树状对话,每个帖子都针对谣言提供自己的支持。我们以支持,拒绝,查询或评论 (SDQC) 声明的方式来构建此框架。因此,我们引入了一个子任务,其目标是标记给定语句 (谣言帖子) 和回复帖子 (后者可以是直接或嵌套回复) 之间的交互类型。树状结构线程中的每个推文都必须分为以下四个类别之一:
支持: 回应的作者支持他们回应的谣言的真实性;
否认: 回应的作者否认他们回应的谣言的真实性;
查询: 答复的作者要求提供与他们所回应的谣言的真实性有关的其他证据;
评论: 回应的作者发表了自己的评论,但没有对评估他们所回应的谣言的真实性做出明确的贡献。
任务 B (验证)
第二个子任务的目标是预测给定谣言的准确性。该谣言以事后报告或质疑的形式提出,但在发布时被认为没有根据。鉴于这样的主张以及提供的一组其他资源,系统应返回一个标签,该标签将谣言的预期真实性描述为真或假。这项任务的基本事实是由团队的记者和专家成员手动确定的,他们确定官方声明或其他可信赖的证据来源,以解决给定谣言的真实性。将提供其他上下文作为准确性预测系统的输入; 此上下文将包括在谣言报道之前立即检索到的相关来源的快照,包括相关Wikipedia文章的快照,Wikipedia转储,从NewsDiffs检索到的数字新闻媒体的新闻文章,以及同一事件的先前推文。至关重要的是,不得使用包含谣言解决后信息的外部资源。为了控制这一点,我们将指定参与者可能使用的外部信息的精确版本。这对于确保我们将时间敏感性引入准确性预测任务很重要。我们采取一种简单的方法来完成这项任务,只对谣言使用正确/错误的标签。然而,实际上,许多说法很难核实; 例如,有许多关于弗拉基米尔·普京 (Vladimir Putin) 在2015年的活动的谣言,许多谣言完全没有根据。因此,我们还期望系统对每个谣言返回0-1范围内的置信度值; 如果谣言不可验证,则应返回0的置信度。
这篇关于谣言检测数据集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





