本文主要是介绍基于PSO粒子群算法的三角形采集堆轨道优化matlab仿真,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.程序功能描述
2.测试软件版本以及运行结果展示
3.核心程序
4.本算法原理
5.完整程序
1.程序功能描述
假设一个收集轨道,上面有5个采集堆,这5个采集堆分别被看作一个4*20的矩阵(下面只有4*10),每个模块(比如:A31和A32的元素含量不同),为了达到采集物品数量和元素含量的要求(比如:需采集5吨和某元素单位质量在65与62之间),求出在每个4*20的矩阵中哪个模块被拿出可以达到要求并找出最优化的轨道?通过PSO优化算法找到最优的轨迹。
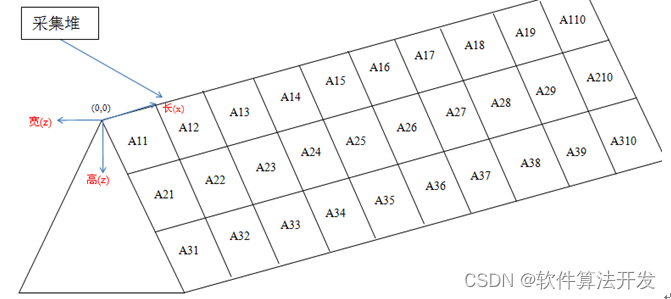
2.测试软件版本以及运行结果展示
MATLAB2022a版本运行
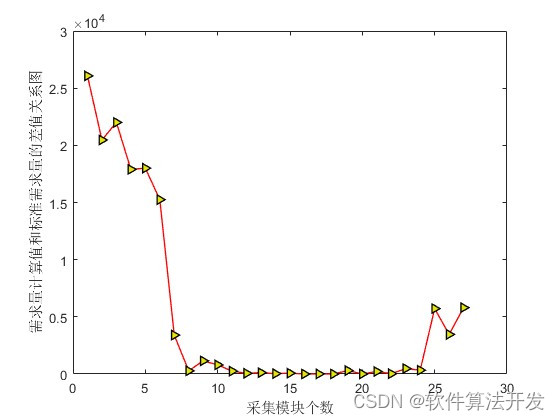

通过这个步骤将优化出符合采集规则且符合元素含量,并满足需求量的模块集合,然后进行轨迹优化。
3.核心程序
...........................................................................xnew = xnew1;%插入交叉区域for j=1:ncrosxnew1(i,n-ncros+j) = cros(j);end%判断产生需求量差是否变小masses=0;masses = sum(maxs_sets(xnew1(i,:)));if F(i)>massesx(i,:)=xnew1(i,:);end%进行变异操作c1 = round(rand*(n-1))+1; c2 = round(rand*(n-1))+1;temp = xnew1(i,c1);xnew1(i,c1) = xnew1(i,c2);xnew1(i,c2) = temp;%判断产生需求量差是否变小masses=0;masses = sum(maxs_sets(xnew1(i,:)));if F(i)>massesx(i,:)=xnew1(i,:);endendFitness_tmps1=F(1);Fitness_tmps2=1;for i=1:Num_x%如果当前值比之前值小,那么将粒子参数赋值给当前值if Fitness_tmps1>=F(i)Fitness_tmps1=F(i);Fitness_tmps2=i;endendxuhao = Fitness_tmps2;L_best(N) = min(F);%当前全局最优需求量Tour_gbest = x(xuhao,:); N = N + 1;end%判断含量是否满足要求for ii = 1:5Fac_tmps(ii) = sum(FAC_sets(Tour_gbest,ii)'.*maxs_sets(Tour_gbest))/sum(maxs_sets(Tour_gbest));end%判断每组元素的含量是否满足约束要求if (Fac_tmps(1) >= Mass1_min & Fac_tmps(1) <= Mass1_max) &...(Fac_tmps(2) >= Mass2_min & Fac_tmps(2) <= Mass2_max) &...(Fac_tmps(3) >= Mass3_min & Fac_tmps(3) <= Mass3_max) &...(Fac_tmps(4) >= Mass4_min & Fac_tmps(4) <= Mass4_max) &... (Fac_tmps(5) >= Mass5_min & Fac_tmps(5) <= Mass5_max)flag(Num_pso-3) = 1;%如果都满足了,则产生标志信息1,否则产生标志信息0elseflag(Num_pso-3) = 0; endMass_fig(Num_pso-3) = min(L_best);Mass_Index{Num_pso-3}= Tour_gbest ;
endfigure;
plot(Mass_fig,'-r>',...'LineWidth',1,...'MarkerSize',6,...'MarkerEdgeColor','k',...'MarkerFaceColor',[0.9,0.9,0.0]);
xlabel('采集模块个数');
ylabel('需求量计算值和标准需求量的差值关系图');
06_010m4.本算法原理
三角形采集堆作为一种高效的数据采集结构,被广泛应用于环境监测、战场侦察、智能交通等领域。其核心任务是在指定的区域内进行数据采集,并将采集到的数据传送到处理中心。为了提高采集效率,减少能量消耗和行走路径长度,需要对三角形采集堆的轨道进行优化。
传统的优化方法,如遗传算法、模拟退火算法等,虽然取得了一定的成果,但在处理复杂优化问题时仍存在收敛速度慢、易陷入局部最优解等问题。粒子群优化(PSO)算法是一种模拟鸟群觅食行为的群体智能优化算法,具有参数少、实现简单、收敛速度快等优点。因此,本文将PSO算法应用于三角形采集堆轨道优化问题中,以期获得更好的优化效果。
粒子群优化算法是一种模拟鸟类集群或鱼群觅食行为的启发式全局优化算法。它通过迭代搜索多个候选解(称为“粒子”),每个粒子都有一个位置和速度,根据其自身的最优历史位置以及整个种群中发现的全局最优位置来更新自身状态,以期找到目标函数的全局最优解。
在三角形采集堆轨道优化场景下,假设有一个移动机器人需要在一系列三角形区域进行资源采集,目标是规划出一条最优化的运动轨迹,使机器人在满足约束条件(如时间、能量消耗等)下尽可能覆盖所有区域或者最大化某种性能指标。
采集规则约束。
即每次只能采集最上面的,如果最上面的没有被取走,那么不能直接采集下面的。
这里,我们使用是数学公式表示如下:

分别对四层的模块进行标记,最上面的为4,如果取走了则直接赋值0,这样,而每次我们只能去标号最大的那个。如果取走了,那么被取走的赋值为0,那么在判断的时候,可以取下面的,如果全部被取走了,则为全0,如果为全零,则这列就不能取值了。即全零表示空。
即上面的约束条件是通过物品的采集,使得总量满足要求,且五个元素的单位质量满足上面的约束,最后使得采集轨迹最短。
所以,通过上面的综合分析,我们所要的数学公式为:

应用PSO解决此问题时,每个粒子表示一种可能的轨迹方案,目标函数可以设计为考虑了采集效率、路径长度、时间等因素的综合评价函数。通过不断地迭代,粒子群会逐渐收敛到最优或接近最优的轨道解决方案。
5.完整程序
VVV
这篇关于基于PSO粒子群算法的三角形采集堆轨道优化matlab仿真的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



