本文主要是介绍LLM 构建Data Muti-Agents 赋能数据分析平台的实践之①:数据采集,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、 概述
在推进产业数字化的过程中,数据作为最重要的资源是优化产业管控过程和提升产业数字化水平的基础一环,如何实现数据采集工作的便利化、高效化、智能化是降低数据分析体系运转成本以及推动数据价值挖掘体系的基础手段。随着数字化在产业端的推进,仅仅依靠各产业各企业内部的业务系统数据是不够的,一方面当前大量的数据集中在互联网,实时的、历史的、以及有价值的数据往往集中在专业行业网站、门户网站;另一方面行业最新的动态、知识更新往往沉淀在互联网平台上。如何将互联网、非结构化文本、图片等数据结构化,作为数据资源体系的重要补充运用到产业数字化中,是进一步挖掘数据价值、补充领域内外知识的重大问题。
以往获取互联网上的数据采取的主要手段就是爬虫,然而这种手段需要较高的代码能力、结构化互联网数据依然需要较大的工作量,而且对于文本知识的结构化通过正则式抽取的方式难以有效统一规则。例如笔者负责构建的农产品市场监测预警系统设计中,为了解决农产品市场数据的抽取、清洗、结构化,采用了正则式抽取文本的方式,然而当文本编写的样式、规则、数据嵌入的方式变化时,还得重新更新正则式库,维护成本奇高。
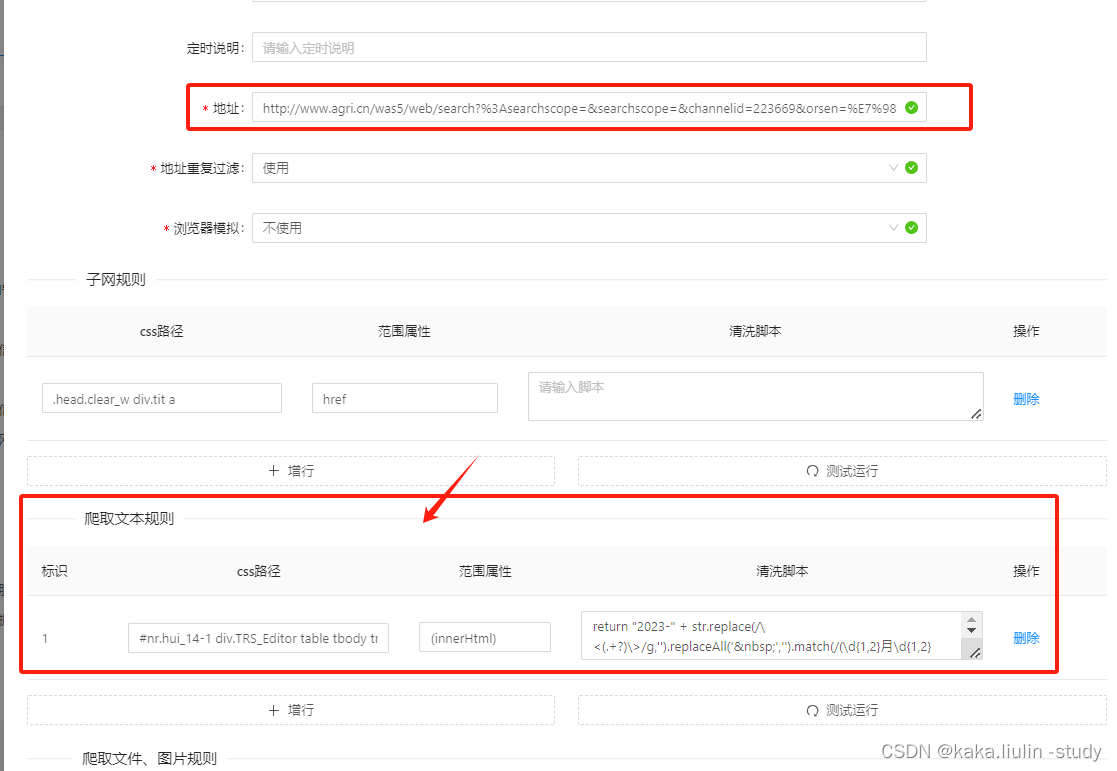
图1 通过文本爬取、正则式清洗获取行业网站-瘦肉型白条猪肉出厂价格价格
在前述文章中【LLM赋能产业数智化业务系统升级的思考】我们讨论了将LLM引入数据平台的设想、可行性及应用场景,通过我们的测试输入待抽取数据的网站—>LLM—>清洗入库是可行性的。本文对该设想做一些实践验证,以推动LLM在产业数字化中的落地。
二、整体设计
1、数据的来源将有如下渠道:文本数据块、网页表格块、网页文本块、图片块等。
2、使用langchain或者llamaindex等框架的检索工具,根据prompt的要求检索相关的信息组成知识块。
3、检索的知识块+用户数据格式要求+数据导出方式一起组合成新的提示词{task prompt}输入到大模型中,完成数据的提取及导入。

三、数据采集实践
1.使用langchain及llama.cpp加载大模型,其他的加载方式请参考blog:LLM RAG 多种方式装载LLM的实践
import os
from langchain.vectorstores import Chroma
from langchain.prompts import PromptTemplate
from langchain.llms import LlamaCpp
from langchain.prompts import PromptTemplate
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
template = """Question: {question}Answer: Let's work this out in a step by step way to be sure we have the right answer."""prompt = PromptTemplate(template=template, input_variables=["question"])
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])n_gpu_layers =0 # Change this value based on your model and your GPU VRAM pool.
n_batch = 5120 # Should be between 1 and n_ctx, consider the amount of VRAM in your GPU.
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])
# Make sure the model path is correct for your system!
llm = LlamaCpp(model_path="./fivetwin/openchat-3.5-0106-GGUF/openchat-3.5-0106.Q4_K_M.gguf",n_gpu_layers=n_gpu_layers,n_batch=n_batch,max_tokens=200000,n_ctx=8912,callback_manager=callback_manager,verbose=True, # Verbose is required to pass to the callback managercontext_window=4096,
)
2、数据获取
(1)网页表格数据结构化获取
我们需要将该网站的生猪报价信息整理成json格式。
建立网页文本的知识块:使用langchain AsyncHtmlLoader获取网页的内容,并向量化。
import pprint
from langchain.document_loaders import AsyncHtmlLoader
from langchain.document_transformers import Html2TextTransformer
from langchain.text_splitter import RecursiveCharacterTextSplitter
urls = ["https://zhuanlan.zhihu.com/p/671371646"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
#print(docs)
# Transform
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs_transformed)
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings)
构建数据抽取解析问答链
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input",return_messages=False)
from langchain.chains import ConversationalRetrievalChain
bot = ConversationalRetrievalChain.from_llm(llm, retriever=vectordb.as_retriever(),memory=memory,verbose=True,return_source_documents=False)
构建数据输出要求及格式:
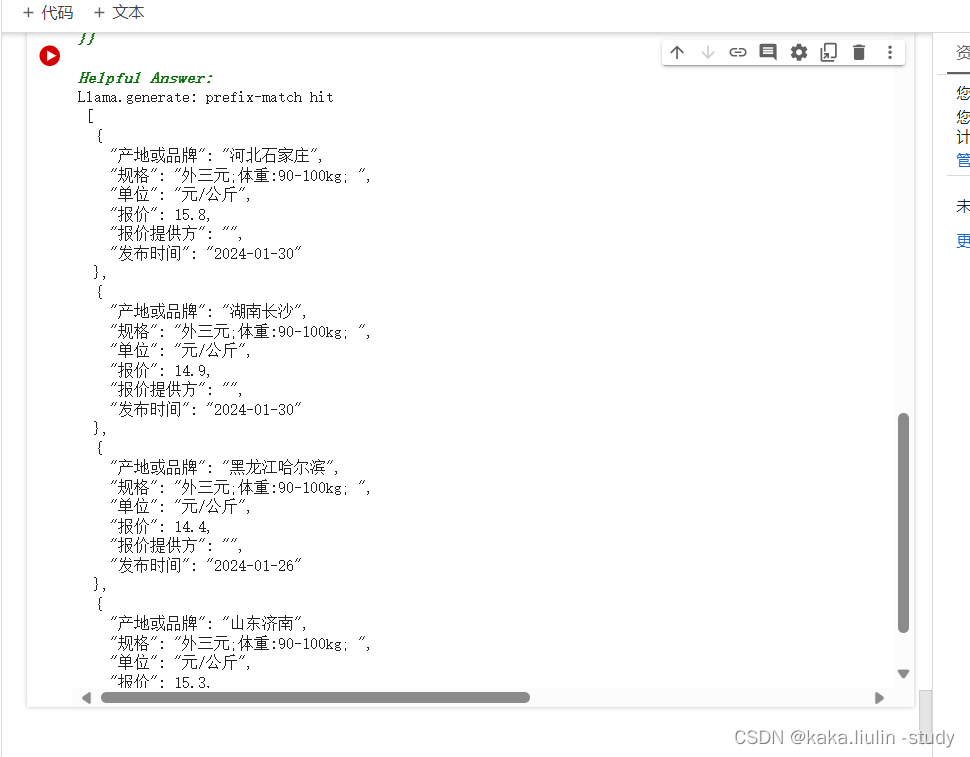
query = """请根据上下文,查询整理各省市生猪市场价格信息,请使用如下的JSON格式返回数据
{{{{"产地或品牌":"x","规格": "a","单位":"元/公斤","报价": "50","报价提供方":"b","发布时间":"b"}},{{"产地或品牌":"x","规格": "a","单位":"元/公斤","报价": "50","报价提供方":"b","发布时间":"b"}},}}
例如:
{"产地或品牌": "河北石家庄","规格": "外三元;体重:90-100kg; ","单位": "元/公斤","报价": 15.8,"报价提供方": "河北石家庄市","发布时间": "2024-01-30"}},
将数据整理成csv格式,并输出一个叫“生猪市场价格情况表.csv”的文件,可以使用python模块的pandas工具
"""
result = bot.invoke({"question": query})
result["answer"]
结果分析:
1)由下图可以看出LLM-RAG-bot将检索到的知识块与数据格式要求一起组合成promt输入到LLM中

2)结果LLM-RAG-bot系统的解析成功将数据抽取成用户所需的格式。
(2)网页文本数据的抽取
大量的数据以文本形式存储在互联网上,如何将其中的有用的信息抽取成结构化的将对于数据资源的补充具有重大意义。接下来将设计一个基于LLM的系统用于文本知识结构化信息抽取,首先我们将互联网上的文本通过爬虫或者其他形式整理成csv,再通过RAG和提示词工程提取其中的结构化信息。

from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="./data.csv")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1500, chunk_overlap=150)
split_docs = text_splitter.split_documents(docs)
vectordb = Chroma.from_documents(documents=split_docs,embedding=embeddings)
memory = ConversationBufferMemory(memory_key="chat_history", input_key="human_input",return_messages=False)
bot_data = ConversationalRetrievalChain.from_llm(llm, retriever=vectordb.as_retriever(),memory=memory,verbose=True,return_source_documents=False)
构建提示词工程:
query="""请根据上下文,查询整理文档中农产品价格信息,请使用JSON格式返回数据
{{{{"date":"x","type": "a","unit":"元/公斤","price": "50",.....}},{{"date":"x","type": "a","unit":"元/公斤","price": "50",.....}},}}
例如:
{"date":"7月21日","type": "牛肉","unit":"元/公斤","price": "50",}},
运行RAG系统:
result = bot.invoke({"query": query})
result["answer"]
结果探讨:
1)系统将提示词和检索到的问答合并输入大模型:

2)输出我们说规定的数据格式:成功将文本中关于农产品的结构化信息提取出来。

四、小结
通过本次测试,我们成功将大模型及AI Agents的应用场景扩展到数据分析体系中的基础环节——数据采集,可以广泛的应用到互联网网页表格数据抽取、文本数据整理等。
这篇关于LLM 构建Data Muti-Agents 赋能数据分析平台的实践之①:数据采集的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



