本文主要是介绍23.5.18 pandas中两个DataFrame数据的pd.merge()合并与pd.concat()拼接,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
DataFrame数据集
1.pd.merge()函数
2.pd.concat()函数
DataFrame数据集
import pandas as pd
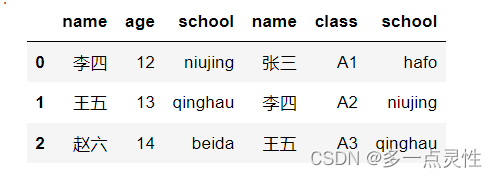
dic1 = {'name':['李四', '王五', '赵六'], 'age':[12, 13, 14],'school':['niujing','qinghau','beida']}
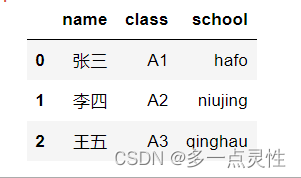
dic2 = {'name':['张三', '李四', '王五'], 'class':['A1', 'A2', 'A3'],'school':['hafo','niujing','qinghau']}
df1 = pd.DataFrame(dic1)
df2 = pd.DataFrame(dic2)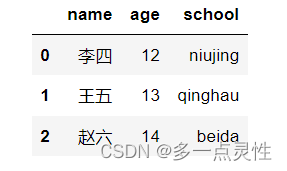
1.pd.merge()函数
pd.merge()函数用于将两个或多个数据帧(DataFrame)按照一定的条件(通常是某些列)进行合并(merge)。
pd.merge(df1,df2,on='列名',how='outer') #按照指定列将两个数据框进行合并。参数:
- how:合并方式:
how = ‘inner’(默认),类似于取交集
how = ‘outer’,类似于取并集
- on:用于连接的列名,若不指定则以两个Dataframe的列名的交集作为连接键
例:
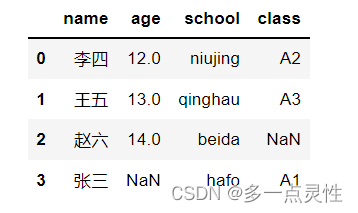
data = pd.merge(df1,df2,how='outer') #how = ‘outer’,类似于取列的并集,即把所有列名相同的列合并
print(data)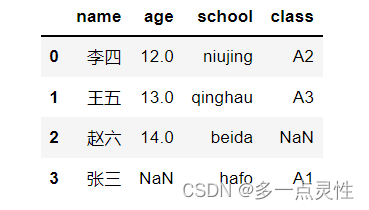
data = pd.merge(df1,df2) #默认how='inner',将每每列合并,行取交集 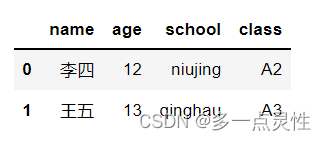
data1 = pd.merge(df1,df2,on='name',how='outer') #按照列名‘name’合并,即只将列名为‘name’的那一列合并,其他列不合并
data2 = pd.merge(df1,df2,on=['name','school'],how='outer')#按照列名‘name’和‘school’合并
print(data1)
print(data2)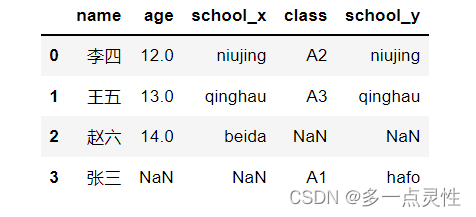
2.pd.concat()函数
pd.concat()函数用于将两个或多个 Pandas 数据帧(DataFrame)沿着某个轴(通常是行或列)进行连接。这种连接方式称为拼接(concatenation)。它可以沿着指定的轴将多个数据帧连接成一个新的数据帧。
pd.concat([df1, df2], ignore_index=True, join='outer',axis=1)参数:
- axis:1轴,按列拼接(增加列);0轴(默认)按行拼接(增加行)
- join:outer默认(拼接时取并集);inner(拼接时取交集)
- ignore_index:默认False,即不重置dataframe的索引;True重置索引,从0开始
data = pd.concat([df1, df2])
#等同于
data = pd.concat([df1, df2], ignore_index=False, join='outer',axis=0)
#将df1和df2,按照不重置索引、
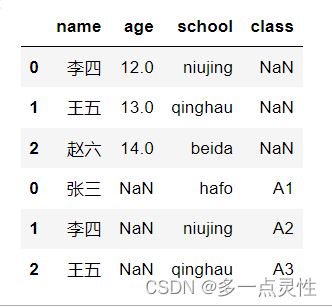
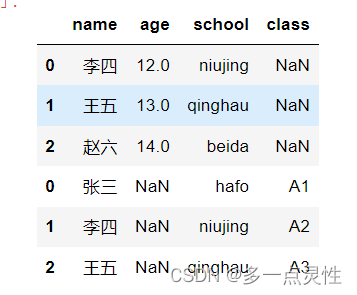
data1 = pd.concat([df1, df2], ignore_index=False, join='outer',axis=0) #按行拼接(增加行),outer表示列取并集
data2 = pd.concat([df1, df2], ignore_index=False, join='outer',axis=1) #按列拼接(增加列)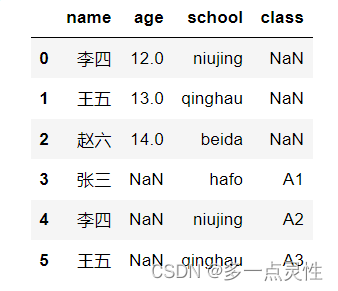
data1 = pd.concat([df1, df2], ignore_index=False, join='outer',axis=0) #按行拼接,列取并集
data = pd.concat([df1, df2], ignore_index=False, join='inner',axis=0) #按行拼接,列取交集

这篇关于23.5.18 pandas中两个DataFrame数据的pd.merge()合并与pd.concat()拼接的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




