本文主要是介绍『大模型笔记』LLM框架(LangChain、LlamaIndex、Haystack、Hugging Face)哪一个是满足您特定需求的最佳选择?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
| LLM框架(LangChain、LlamaIndex、Haystack、Hugging Face)哪一个是满足您特定需求的最佳选择? |
文章目录
- 1. LangChain
- 1.1. 优势
- 1.2. 劣势
- 1.1. 理想用例
- 2. LlamaIndex
- 2.1. 优势
- 2.2. 劣势
- 2.3. 理想用例
- 3. Haystack
- 3.1. 优势
- 3.2. 劣势
- 3.3. 理想用例
- 4. Hugging Face
- 4.1. 优势
- 4.2. 劣势
- 4.3. 理想用例
- 5. 总结
- 以下是四种框架(LangChain, LlamaIndex, Haystack, Hugging Face)的详细解释,包括它们的优势、劣势和理想用例,以帮助您选择适合您的生成式AI应用的正确框架:
| 框架 | 优势 | 劣势 | 理想用例 |
|---|---|---|---|
| LangChain | - 灵活性和扩展性高 - 可扩展性强 - 开源 | - 学习曲线较陡 - 用户界面不够友好 | - 研究项目 - 高性能应用 |
| LlamaIndex | - 搜索和检索效率高 - 易用性好 - 与Hugging Face无缝集成 - 开源 | - 功能有限 - 黑箱性质 | - 信息检索 - 个性化内容生成 |
| Haystack | - 全面的NLP流水线 - 灵活性和定制性 - 开源和社区驱动 | - 设置更复杂 - 资源密集型 | - 信息提取 - 问题回答 - 情感分析 |
| Hugging Face | - 丰富的模型库 - 用户友好平台 - 协作开发 - 开源 | - 功能有限 - 成本 | - 模型训练和微调 - 模型评估和比较 - 协作研究 |
1. LangChain
- https://github.com/langchain-ai/langchain



1.1. 优势
- 灵活性和扩展性:高度可定制和模块化的架构允许构建复杂的、定制化的生成式AI应用。
- 可扩展性:高效处理大型数据集和要求苛刻的应用。
- 开源:鼓励社区参与,促进协作开发。
1.2. 劣势
- 学习曲线较陡:其灵活性要求对NLP和系统设计有更深入的了解。
- 用户界面不够友好:相比其他框架,可能需要更多的努力来设置和管理。
1.1. 理想用例
- 研究项目:使得使用尖端NLP技术进行实验和探索成为可能。
- 高性能应用:适用于对高可扩展性和定制化要求高的复杂任务,如对话生成、内容创造和聊天机器人。
2. LlamaIndex
- https://github.com/run-llama/llama_index
- LlamaIndex 是用于构建LLM应用程序的领先数据框架。 https://www.llamaindex.ai/

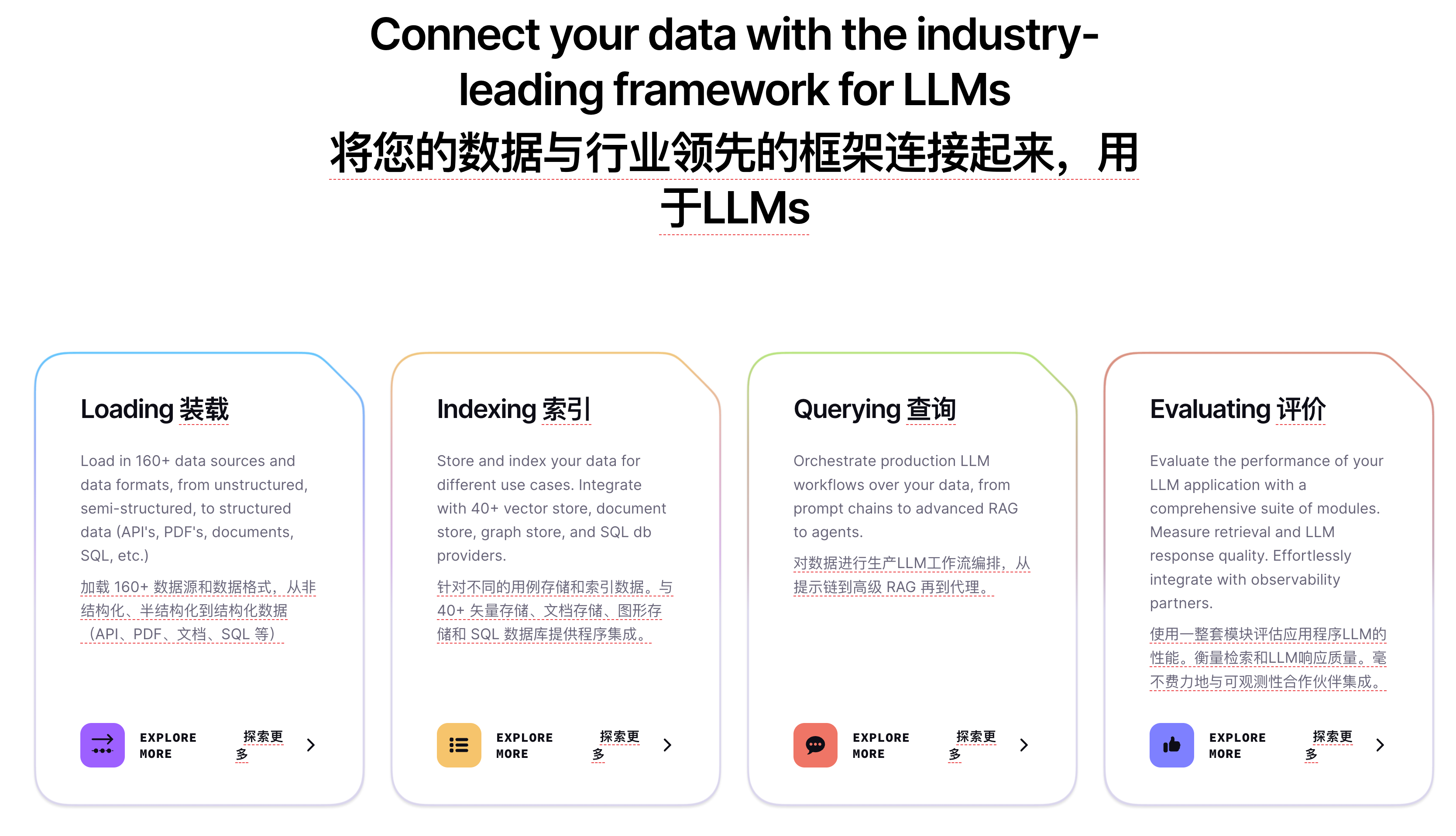
2.1. 优势
- 流畅的搜索和检索:高效搜索和检索生成式AI应用相关的数据。
- 易用性:简单的API和直观的界面,易于设置和使用。
- 与Hugging Face的无缝集成:与Hugging Face模型和数据集的无缝集成。
2.2. 劣势
- 功能有限:主要关注数据检索,不太适合复杂的NLP任务。
- 黑箱性质:内部工作可能较不透明,阻碍细微调整和定制。
2.3. 理想用例
- 信息检索:增强依赖于实际数据检索的生成式AI应用,如问题回答和摘要。
- 个性化:根据用户过去的互动和偏好生成个性化内容。
3. Haystack
- https://github.com/deepset-ai/haystack
- Haystack (https://haystack.deepset.ai/) 是一个端到端LLM框架,允许您构建由 LLMsTransformer 模型、向量搜索等提供支持的应用程序。无论您是想执行检索增强生成 (RAG)、文档搜索、问答还是答案生成,Haystack 都可以编排最先进的嵌入模型并LLMs进入管道,以构建端到端 NLP 应用程序并解决您的用例。

3.1. 优势
- 全面的NLP流水线:支持多种NLP任务,如信息提取、问题回答和情感分析。
- 灵活性和定制性:允许根据特定需求定制NLP流水线。
- 开源和社区驱动:鼓励社区贡献并促进协作。
3.2. 劣势
- 设置更复杂:相比LlamaIndex需要更多的配置和集成。
- 资源密集型:对资源受限的环境来说,可能计算代价高昂。
3.3. 理想用例
- 信息提取:从大型数据集中提取关键信息和洞见。
- 问题回答:构建能回答复杂问题的高级聊天机器人和虚拟助手。
- 情感分析:从文本数据中分析用户情绪和意见。
4. Hugging Face
- https://github.com/huggingface

4.1. 优势
- 丰富的模型库:提供访问大量预训练和社区共享模型。
- 用户友好平台:易于使用的界面,用于模型训练、微调和部署。
- 协作开发:促进NLP社区内的协作和知识分享。
4.2. 劣势
- 功能有限:主要关注模型训练和评估,可能需要额外的工具进行数据处理和流水线构建。
- 成本:某些模型和功能需要付费订阅。
4.3. 理想用例
- 模型训练和微调:快速训练和微调特定任务的模型。
- 模型评估和比较:为性能优化对比不同模型。
- 协作研究:与社区共享模型和数据集,加速研究进展。
5. 总结
- 您的生成式AI应用的最佳框架取决于其特定的需求和优先级。
考虑以下因素:
- 灵活性和扩展性:如果您需要一个 高度可定制的平台 来处理复杂任务,选择LangChain。
- 效率和易用性:对于 简化的数据检索,选择LlamaIndex;对于 用户友好的NLP流水线,选择Haystack。
- 模型可用性:如果您高度依赖预训练模型和协作开发,选择Hugging Face。
- 资源限制:如果您的计算资源有限,请考虑Haystack的资源需求。
- 记住,您也可以结合使用这些框架来利用它们各自的优势。例如,您可以使用Haystack进行复杂的NLP任务,同时使用Hugging Face进行模型训练、微调和部署。最终,最佳选择取决于您的特定需求和资源。通过实验不同的框架并比较它们的性能,可以帮助您做出明智的决定。
- 参考文献:https://medium.com/@sujathamudadla1213/which-of-the-four-generative-ai-frameworks-langchain-llamaindex-haystack-hugging-face-would-be-700eb63ba2a1
这篇关于『大模型笔记』LLM框架(LangChain、LlamaIndex、Haystack、Hugging Face)哪一个是满足您特定需求的最佳选择?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




