本文主要是介绍R语言,实现MACD指标计算:股票技术分析的利器系列(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
R语言,实现MACD指标计算:股票技术分析的利器系列(1)
- MACD指标
- 代码
- 完整代码
- 介绍代码
- EMA函数
- calculate_DEA 函数
- calculate_MACD 函数
- 运行结果
MACD指标
先看看官方介绍:
MACD (平滑异同平均线)
指标说明
DIF线:收盘价短期、长期指数平滑移动平均线间的差;
DEA线:DIF线的M日指数平滑移动平均线;
MACD线:DIF线与DEA线的差,彩色柱状线;
参数:SHORT(短期)、LONG(长期)、M 天数,一般为12、26、9。
用法
1.DIF、DEA均为正,DIF向上突破DEA,买入信号;
2.DIF、DEA均为负,DIF向下跌破DEA,卖出信号;
3.DEA线与K线发生背离,行情反转信号;
4.分析MACD柱状线,由红变绿(正变负),卖出信号;由绿变红,买入信号。
算法解释:
DIF:EMA(CLOSE,SHORT)-EMA(CLOSE,LONG);
DEA:EMA(DIF,MID);
MACD:(DIF-DEA)*2,COLORSTICK;
优势:
| 优势 | 描述 |
|---|---|
| 趋势跟踪能力强 | MACD能够帮助识别市场的趋势方向,尤其是短期和长期趋势的转折点。通过观察DIF和DEA线的交叉,可以提供买入和卖出的时机。 |
| 清晰的信号 | MACD的交叉点和柱状线的变化提供了清晰的交易信号,使得投资者能够更容易地进行决策。 |
| 背离信号 | 当DEA线与价格走势产生背离时,往往暗示着市场趋势即将发生变化,这为投资者提供了及时的行动信号。 |
| 柱状线变化反映市场动能 | MACD柱状线的颜色变化反映了市场的动能变化,红色代表正能量增强,绿色代表负能量增强,这有助于投资者了解市场情绪和力量的变化。 |
劣势:
| 劣势 | 描述 |
|---|---|
| 滞后性 | MACD是一种滞后指标,它基于移动平均线的计算,因此在市场趋势发生变化之后才会发出信号,有时可能会错过市场的最佳买入或卖出时机。 |
| 假信号 | 由于MACD的计算方式,有时会出现假信号,即在市场波动较大或横盘震荡时,可能会产生交叉但并未发生实际的趋势转折。 |
| 单一性 | MACD虽然能够提供趋势判断和交易信号,但它并不能完全覆盖市场的全部信息,投资者在使用时仍需要结合其他指标和技术分析方法进行综合判断。 |
代码
完整代码
请将下面代码的 C:/Users/daoli/Desktop/stock_demo/MACD 替换你们自己的工作路径
# 设置工作目录为MACD文件夹
setwd("C:/Users/daoli/Desktop/stock_demo/MACD")
# 打印当前工作目录
print(getwd())# 导入stock_data.R中的函数和数据
source('stock_data.R')# 定义函数计算指数移动平均线(Exponential Moving Average,EMA)
# 参数:
# x: 输入数据
# n: 平滑因子
# 返回值:
# 指数移动平均线
EMA <- function(x, n) {ema <- numeric(length(x))ema[1] <- x[1]alpha <- 2 / (n + 1)for (i in 2:length(x)) {ema[i] <- alpha * x[i] + (1 - alpha) * ema[i - 1]}return(ema)
}# 计算DIF指标
# 参数:
# close: 收盘价数据
# short: 短期平滑因子
# long: 长期平滑因子
# 返回值:
# DIF指标
calculate_DIF <- function(close, short, long) {dif <- EMA(close, short) - EMA(close, long)return(dif)
}# 计算DEA指标
# 参数:
# dif: DIF指标数据
# mid: 中期平滑因子
# 返回值:
# DEA指标
calculate_DEA <- function(dif, mid) {dea <- EMA(dif, mid)return(dea)
}# 计算MACD指标
# 参数:
# dif: DIF指标数据
# dea: DEA指标数据
# 返回值:
# MACD指标
calculate_MACD <- function(dif, dea) {macd <- (dif - dea) * 2return(macd)
}# 参数设置
SHORT <- 12
LONG <- 26
MID <- 9# 计算指标
dif <- calculate_DIF(stock_data$CLOSE, SHORT, LONG)
dea <- calculate_DEA(dif, MID)
macd <- calculate_MACD(dif, dea)# 将计算得到的指标合并到原始数据中
stock_data <- cbind(stock_data,DIF = round(dif, 2),DEA = round(dea, 2),MACD = round(macd, 2)
)# 根据日期字段倒序排列并展示数据
stock_data <-stock_data[order(stock_data$DATE, decreasing = TRUE), ]
View(stock_data)介绍代码
EMA函数
# 定义函数计算指数移动平均线(Exponential Moving Average,EMA)
# 参数:
# x: 输入数据
# n: 平滑因子
# 返回值:
# 指数移动平均线
EMA <- function(x, n) {ema <- numeric(length(x))ema[1] <- x[1]alpha <- 2 / (n + 1)for (i in 2:length(x)) {ema[i] <- alpha * x[i] + (1 - alpha) * ema[i - 1]}return(ema)
}
-
EMA <- function(x, n) {: 这一行定义了一个函数EMA,接受两个参数x和n,其中x是一个数值型向量,包含要计算EMA的数据,n是一个整数,代表指数平滑的窗口大小。 -
ema <- numeric(length(x)): 这一行创建了一个名为ema的空数值型向量,其长度与输入向量x的长度相同,用来存储计算得到的 EMA。 -
ema[1] <- x[1]: 这一行将ema向量的第一个元素设置为输入向量x的第一个元素,作为初始值。 -
alpha <- 2 / (n + 1): 这一行计算了一个常数alpha,用于指数平滑计算中的权重。alpha的计算公式为 2 / (n + 1),其中n是平滑窗口大小。 -
for (i in 2:length(x)) {: 这一行开启了一个循环,从输入向量x的第二个元素开始,直到最后一个元素。 -
ema[i] <- alpha * x[i] + (1 - alpha) * ema[i - 1]: 这一行计算了当前时刻i的 EMA,根据指数平滑的公式:新EMA值等于当前值乘以权重alpha再加上上一个EMA值乘以权重(1 - alpha)。 -
return(ema): 这一行返回计算得到的 EMA 向量。
calculate_DEA 函数
calculate_DEA <- function(dif, mid) {dea <- EMA(dif, mid)return(dea)
}
-
calculate_DIF <- function(close, short, long) {: 这一行定义了一个函数calculate_DIF,接受三个参数:close是一个数值型向量,包含股价收盘价的数据;short和long是两个整数,分别代表短期和长期的指数平滑窗口大小。 -
dif <- EMA(close, short) - EMA(close, long): 这一行计算了两个不同长度的指数移动平均线之间的差异值(DIF)。首先调用了之前定义的EMA函数来计算close向量的短期和长期EMA值,然后将短期EMA值减去长期EMA值得到差异值dif。 -
return(dif): 这一行返回计算得到的差异值dif。
calculate_MACD 函数
calculate_MACD <- function(dif, dea) {macd <- (dif - dea) * 2return(macd)
}
这段代码定义了一个函数 calculate_MACD,用于计算移动平均收敛-发散指标(Moving Average Convergence Divergence,MACD)。下面是对每一行代码的解释:
-
calculate_MACD <- function(dif, dea) {: 这一行定义了一个函数calculate_MACD,接受两个参数:dif是一个数值型向量,代表差异值;dea也是一个数值型向量,代表差异值的指数移动平均线(DEA)。 -
macd <- (dif - dea) * 2: 这一行计算了MACD值,首先从差异值dif中减去差异值的指数移动平均线dea,然后将结果乘以2。 -
return(macd): 这一行返回计算得到的MACD值。
运行结果
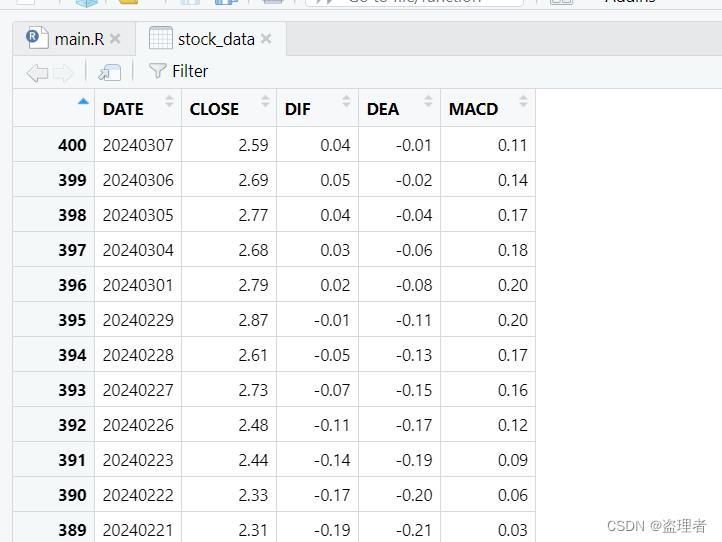
这篇关于R语言,实现MACD指标计算:股票技术分析的利器系列(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






