本文主要是介绍Python 中实现 CDF 累积分布图的两种方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是累积分布
累积分布函数,又叫分布函数,是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。一般以大写“CDF”(Cumulative Distribution Function)标记。
《百度百科》
累积分布函数,又叫分布函数,是概率密度函数的积分,能完整描述一个实随机变量X的概率分布。一般以大写“CDF”(CumulativeDistributionFunction)标记。累积分布图(distribution diagram)是在一组依大小顺序排列的测量值中,当按一定的组即分组时出现测量值小于某个数值的频数或额率对组限的分布图。
简单理解:就是所有 x 左边的值都会落在对应 y 值的概率里。
第一种方法
使用 seaborn 的 ecdfplot 方法, 代码如下:
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np# 假设你有一些数据
data1 = np.random.normal(size=1000) # 生成1000个正态分布的随机数
data2 = np.random.normal(size=1000) # 生成1000个正态分布的随机数
df = pd.DataFrame({'data1': data1, 'data2': data2})
# 使用sns.distplot()来计算并绘制CDF
sns.ecdfplot(data=df, legend=True)
plt.grid()
# 显示图形
plt.show() 得到的 CDF 图形:
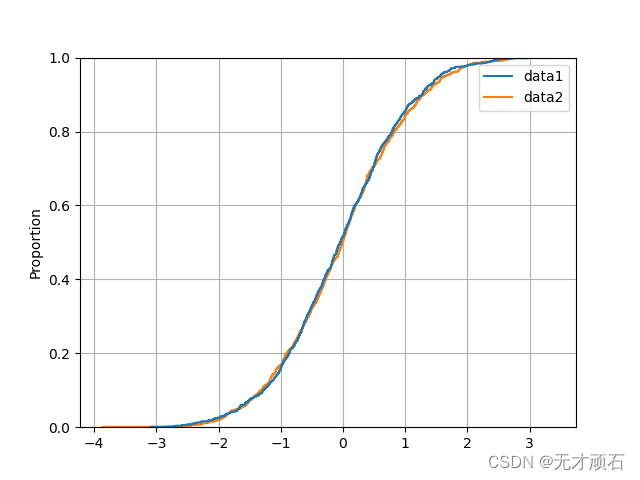
第二种方法
使用 scipy 的 mquantiles 计算
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from scipy.stats.mstats import mquantiles
from matplotlib.ticker import PercentFormatterdef cdf_by_data(df, mark, title):fig, ax = plt.subplots()y = np.arange(0, 1, 0.01)x = mquantiles(df, y)ax.plot(x, y)ax.set_title(title + " - CDF")ax.axvline(x=mark, color='r', linestyle='--', label=str(mark))ax.yaxis.set_major_formatter(PercentFormatter(1))ax.set_xlabel(title)ax.set_ylabel('probability')index = np.abs(x - mark).argmin()plt.plot(mark, y[index], 'o', color='g')ax.text(mark + 1, y[index], "({}, {}%)".format(mark, round(y[index] * 100)), color='r')plt.grid(True)# 假设你有一些数据
data1 = np.random.normal(size=1000) # 生成1000个正态分布的随机数
data2 = np.random.normal(size=1000) # 生成1000个正态分布的随机数
df = pd.DataFrame({'data1': data1, 'data2': data2})
cdf_by_data(df=df, mark=0, title='cdf of data')
plt.grid()
# 显示图形
plt.show() 得到的图形如下:
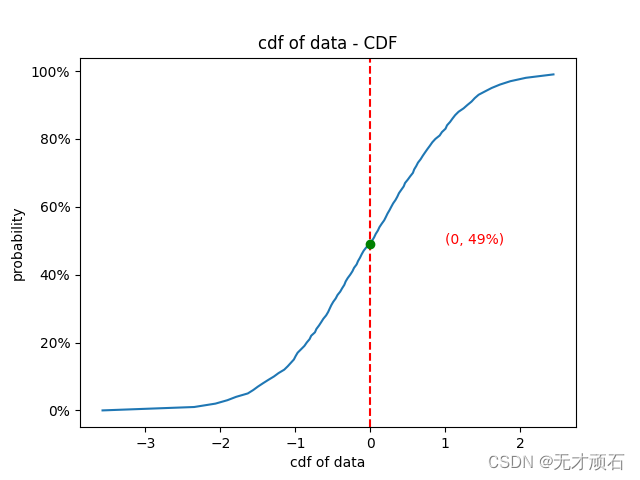
这篇关于Python 中实现 CDF 累积分布图的两种方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





