本文主要是介绍从spark streaming与structured streaming看spark core与spark sql的区别,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
导读
Spark中针对流式数据处理的方案有:
- Spark Streaming
- Structured Streaming
本文通过对比spark streaming与structured streaming,来深入理解spark core与spark sql的区别。
Spark Streaming
基于微批(DStream)
Spark Streaming是基于微批(Micro batch)的,而Flink基于实时流,来一条数据处理一条数据
Spark Streaming是Spark生态系统当中一个重要的框架,它建立在Spark Core之上(而Structured Streaming则基于spark sql),只不过是划分了微批
具体来说,Spark Streaming将流式数据按照时间间隔BatchInterval划分为很多部分,每一部分Batch(批次),针对每批次数据Batch当做RDD进行快速分析和处理
它的核心概念是DStream,它实质上是一系列时间上连续的RDD的集合(Seq[RDD]),DStream可以按照秒、分等时间间隔将数据流进行批量的划分:首先从接收到流数据之后,将其划分为多个batch,然后提交给Spark集群进行计算,最后将结果批量输出到HDFS或者数据库以及前端页面展示等等 ,如下图所示:
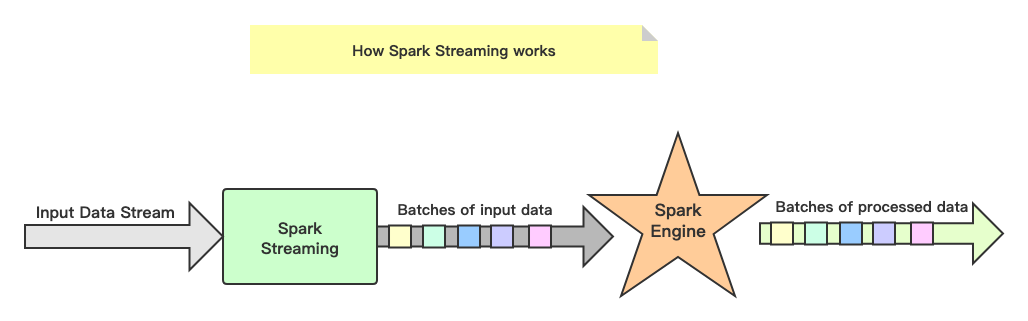
DStream中每批次数据RDD在处理时,各个RDD之间存在依赖关系,DStream之间也有依赖关系,RDD具有容错性,那么DStream也具有容错性
一个典型例子:

Spark Streaming的不足
- 使用 Processing Time 而不是 Event Time
- Spark Streaming是基于DStream模型的micro-batch模式,数据切割是基于Processing Time,这样就导致使用 Event Time 特别的困难。
- Complex, low-level api
- DStream(Spark Streaming 的数据模型)提供的API类似RDD的API,非常的low level;
- 当编写Spark Streaming程序的时候,本质上就是要去构造RDD的DAG执行图,然后通过Spark Engine运行。这样导致一个问题是,DAG 可能会因为开发者的水平参差不齐而导致执行效率上的天壤之别
- reason about end-to-end application
- DStream 只能保证自己的一致性语义是 exactly-once 的,而 input 接入 Spark Streaming 和 Spark Straming 输出到外部存储的语义往往需要用户自己来保证;
- 延迟较大
- 对于目前版本的Spark Streaming而言,其最小的Batch Size的选取在0.5~5秒钟之间,所以Spark Streaming能够满足流式准实时计算场景,对实时性要求非常高的如高频实时交易场景则不太适合。
- 批流代码不统一
- Streaming尽管是对RDD的封装,但是要将DStream代码完全转换成RDD还是有一点工作量的,更何况现在Spark的批处理都用DataSet/DataFrameAPI
Structured Streaming
Structured Streaming是一个基于Spark SQL引擎的可扩展、容错的流处理引擎
Spark SQL 执行引擎做了非常多的优化工作,比如执行计划优化、codegen、内存管理等。这也是Structured Streaming取得高性能和高吞吐的一个原因
Structured Streaming有两种执行模型:默认使用微批处理执行模型,还有一种低延迟的
默认的micro-batch processing
Structured Streaming默认使用微批处理执行模型。 这意味着Spark流式计算引擎会定期检查流数据源,并对自上一批次结束后到达的新数据执行批量查询。
最核心的思想就是将实时到达的数据看作是一个不断追加的unbound table无界表,到达流的每个数据项就像是表中的一个新行被附加到无边界的表中,用静态结构化数据的批处理查询方式进行流计算(而spark streaming则是微批)。使用类似对于静态表的批处理方式来表达流计算,然后 Spark 以在无限表上的增量计算来运行。
Structured Streaming 周期性或者连续不断的生成微小dataset,然后交由Spark SQL的增量引擎执行,跟Spark Sql的原有引擎相比,增加了增量处理的功能,增量就是为了状态和流表功能实现。由于也是微批处理,底层执行也是依赖Spark SQL的。
在这个体系结构中,Driver驱动程序通过将记录偏移量保存到预写日志中来对数据处理进度设置检查点,然后可以使用它来重新启动查询。 需要注意的是,为了获得确定性的重新执行(deterministic re-executions)和端到端语义,在处理下一个微批数据之前,要将该微批数据中的偏移范围保存到日志中。 所以,当前到达的数据需要等待当前的微批处理作业完成,且其中数据的偏移量范围被计入日志后,才能在下一个微批作业中得到处理。 在细粒度上,时间线看起来像这样。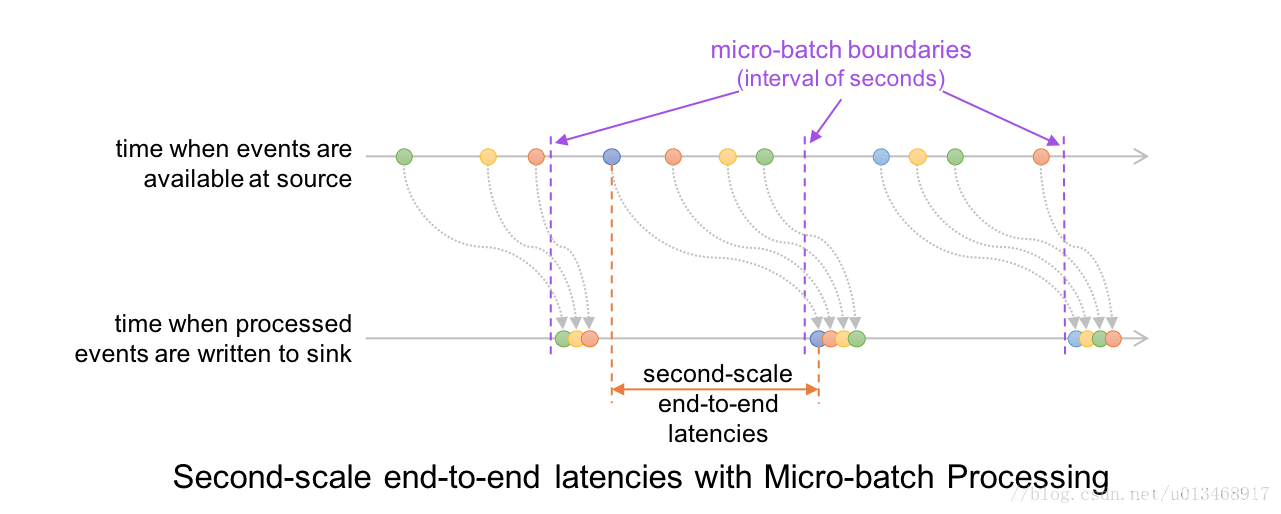
这会导致数据到达和得到处理并输出结果之间的延时超过100ms。
一个典型的计数例子:
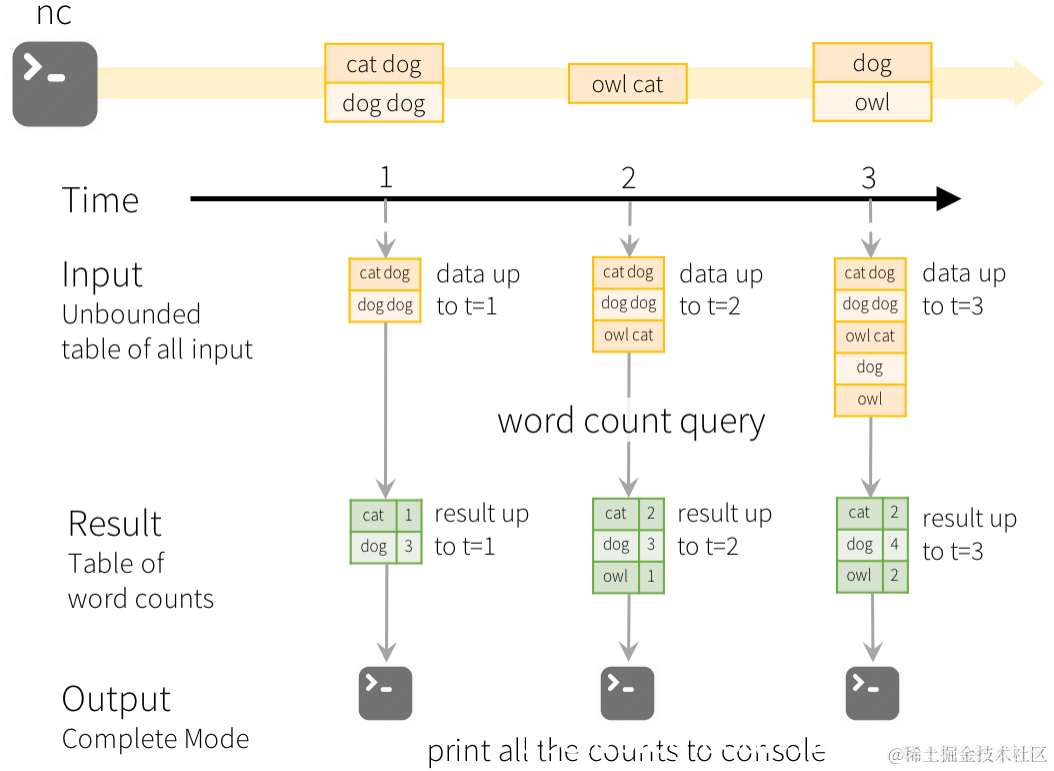
微批的数据延时对于大多数实际的流式工作负载(如ETL和监控)已经足够了。然而,一些场景确实需要更低的延时,所以设计并构建了连续处理模式。
Continuous Processing Mode
在连续处理模式中,Spark不再是启动周期性任务,而是启动一系列连续读取,处理和写入数据的长时间运行的任务。 在高层次上,设置和记录级时间线看起来像这些(与上述微量批处理执行图相对照)。

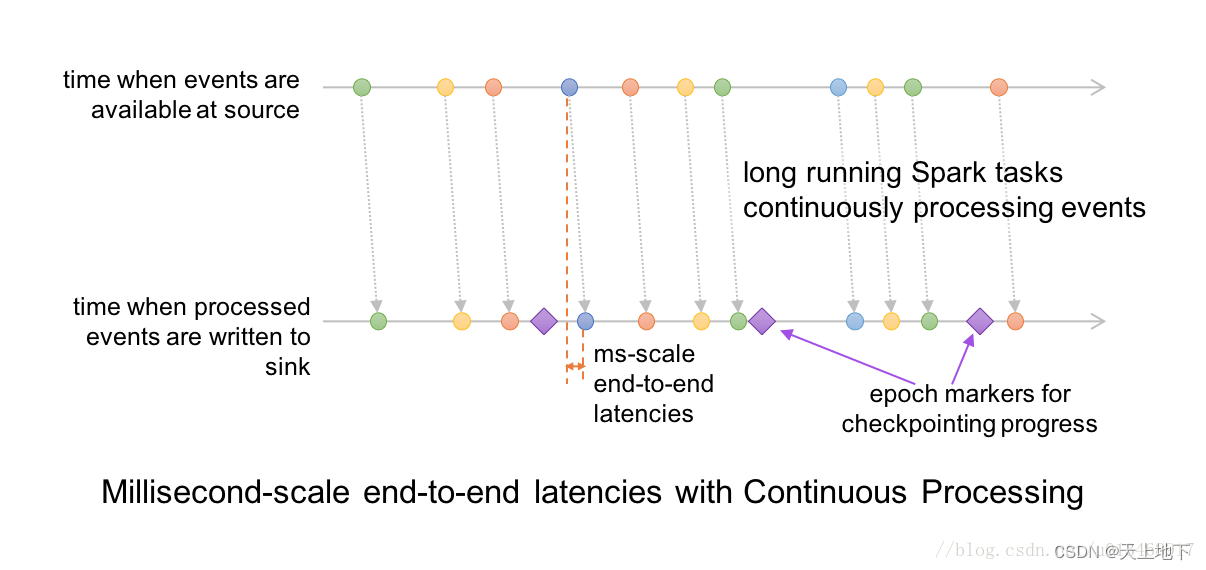
由于事件在到达时会被立即处理和写入结果,所以端到端延迟只有几毫秒。
此外,利用著名的Chandy-Lamport算法对查询进度设置检查点。 特殊标记的记录被注入到每个任务的输入数据流中; 我们将它们称为“时间代标记(epoch marker)”,并将它们之间的差距称为“时间代(epoch)”。当任务遇到标记时,任务异步报告处理后的最后偏移量给driver。 一旦driver程序接收到写入接收器的所有任务的偏移量,它就会将它们写入前述的预写日志。 由于检查点的设置是完全异步的,任务可以不间断地持续并提供一致的毫秒级延迟。
对比
在Spark2.3.0中,流数据的连续处理模式还是一种实验性功能,在此模式下支持Structured Streaming所支持的所有流数据源以及DataFrame / Dataset / SQL操作的子集。它支持低延迟(~1 ms)端到端,并保证at-least-once。与默认的微批处理引擎相比,默认的micro-batch processing可以保证exactly-once语义,但最多只能实现约100ms的延迟。
由于spark Streaming是基于spark core,而Structured Streaming是基于spark sql,所以我们自然而然想看下spark core与spark sql的区别,以及为什么会这么设计。
Spark Core

Spark Core实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
其中关键是RDD,还记得上面说spark streaming是基于DStream,而Dsteam是一系列时间上连续的RDD集合?RDD的转换和聚合算子都是高阶函数。高阶函数指的是形参包含函数的函数,或是返回结果包含函数的函数。对于这些高阶算子,开发者需要以Lambda函数的形式自行提供具体的计算逻辑。以map为例,我们需要明确对哪些字段做映射,以什么规则映射。再以filter为例,我们需要指明以什么条件在哪些字段上过滤。
比如:
// 创建一个 RDD
val rdd = sc.parallelize(List(1, 2, 3, 4, 5))// 对 RDD 进行转换
val result = rdd.map(x => x * x).collect()
但这样一来,Spark只知道开发者要做map、filter,但并不知道开发者打算怎么做map和filter。也就是说,在RDD的开发模式下,Spark Core只知道“做什么”,而不知道“怎么做”。这会让Spark Core两眼一抹黑,除了把Lambda函数用闭包的形式打发到Executors以外,实在是没有什么额外的优化空间。
对于Spark Core来说,优化空间受限最主要的影响,莫过于让应用的执行性能变得低下,不同人开发的同一功能,性能可能天差地别。
Spark SQL
DataFrame
针对优化空间受限这个核心问题,Spark在2013年在1.3版本中发布了DataFrame。
DataFrame就是携带数据模式(Data Schema)的结构化分布式数据集,而RDD是不带Schema的分布式数据集。另外,RDD算子多是高阶函数,这些算子允许开发者灵活地实现业务逻辑,表达能力极强。而DataFrame的表达能力却很弱。一来,它定义了一套DSL(Domain Specific Language)算子,如select、filter、agg、groupBy等等。由于DSL语言是为解决某一类任务而专门设计的计算机语言,非图灵完备,因此,语言表达能力非常有限。二来,DataFrame中的绝大多数算子都是标量函数(Scalar Functions),它们的形参往往是结构化的数据列(Columns),表达能力也很弱。
例如:
// 创建一个 DataFrame
val df = spark.read.json("path/to/data.json")// 使用 SQL 查询 DataFrame
val result = df.select("name", "age").where("age > 18").collect()
DataFrame API为Spark引擎的内核优化打开了全新的空间。
首先,DataFrame中Schema所携带的类型信息,让Spark可以根据明确的字段类型设计定制化的数据结构,从而大幅提升数据的存储和访问效率。
其次,DataFrame中标量算子确定的计算逻辑,让Spark可以基于启发式的规则和策略,甚至是动态的运行时信息去优化DataFrame的计算过程。
另外,为了支持DataFrame开发模式,Spark从1.3版本开始推出Spark SQL。Spark SQL的核心组件有二,其一是Catalyst优化器,其二是Tungsten。
Catalyst:执行过程优化
Catalyst是Apache Spark的核心优化器,负责将用户查询计划转换为高效的执行计划。它是一个基于规则的优化器,使用一组规则来分析和转换查询计划,以提高性能。Catalyst的主要功能包括:
- 语法解析:将SQL或其他查询语言解析为抽象语法树(AST)。
- 逻辑优化:在AST级别进行优化,例如常量折叠、谓词下推和连接重写。
- 物理优化:将逻辑计划转换为物理计划,选择最佳的执行策略,例如选择算法、连接顺序和分区策略。
- 代码生成:将物理计划转换为高效的字节码,用于在分布式集群上执行查询。
而这一系列的优化,首先就需要结合DataFrame的Schema信息,确认计划中的表名、字段名、字段类型与实际数据是否一致。这个过程也叫做把“Unresolved Logical Plan”转换成“Analyzed Logical Plan”。也就是说,Catalyst的优化空间来源DataFrame的开发模式。
具体过程可以看spark的Catalyst到底做了什么-CSDN博客
为什么启发式的规则一定要先转为Analyzed Logical Plan?
因为启发式的规则例如列剪枝、谓词下推、常量替换等都依赖于与字段名等与实际数据是一致,如果不一致,那么进行这些优化就是无效的、甚至导致错误的结果,因此必须先转为Analyzed Logical Plan,这个过程中会结合DataFrame的Schema信息,确认计划中的表名、字段名、字段类型与实际数据是否一致
Tungsten:数据结构优化
Tungsten使用定制化的数据结构Unsafe Row来存储数据,Unsafe Row的优点是存储效率高、GC效率高。Tungsten之所以能够设计这样的数据结构,仰仗的也是DataFrame携带的Schema。
Tungsten是用二进制字节序列来存储每一条用户数据的,因此在存储效率上完胜Java Object。

要想实现上图中的二进制序列,Tungsten必须要知道数据条目的Schema才行。也就是说,它需要知道每一个字段的数据类型,才能决定在什么位置安放定长字段、安插Offset,以及存放变长字段的数据值。DataFrame刚好能满足这个前提条件。
虽然RDD也带类型,如RDD[Int]、RDD[(Int, String)],但如果RDD中携带的是开发者自定义的数据类型,如RDD[User]或是RDD[Product],Tungsten就会两眼一抹黑,完全不知道你的User和Product抽象到底是什么。RDD的通用性是一柄双刃剑,在提供开发灵活性的同时,也让引擎内核的优化变得无比困难。
总结
Spark Core实现了 Spark 的基本功能,包含RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL是Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL操作数据。(Spark SQL is Apache Spark’s module for working with structured data)
spark core包含了最核心的分布式计算、数据处理,弹性分布式数据集 (RDD) ;但是rdd很多都是高阶函数(参数、返回类型都可以是函数,例如filter也可以用函数参数),开发者使用rdd的函数自由度很高,但是缺点是无法做计划优化(rdd是数据模式,不带schema),而且不同水平的人开发出来的性能差异很大
而spark sql是用dataframe/dataset(带schema的rdd)做抽象,都是简单的标量函数如select,filter,可以用catalyst和钨丝计划进行优化
联系
Spark Core 与 Spark SQL 的关系可以比作汽车的引擎和车身。Spark Core 是引擎,提供动力和功能,而 Spark SQL 是车身,提供用户界面和特定于领域的特性。
Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL)。即Spark SQL是Spark Core封装而来的,Spark SQL在Spark Core的基础上针对结构化数据处理进行很多优化和改进,
Spark SQL 支持很多种结构化数据源,可以让你跳过复杂的读取过程,轻松从各种数据源中读取数据。当你使用SQL查询这些数据源中的数据并且只用到了一部分字段时,SparkSQL可以智能地只扫描这些用到的字段,而不是像SparkContext.hadoopFile中那样简单粗暴地扫描全部数据。
当然,最终spark sql编写后也会转换为rdd
目前所有子框架的源码实现都已从 RDD 切换到 DataFrame
这篇关于从spark streaming与structured streaming看spark core与spark sql的区别的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








