本文主要是介绍数据说话:GIS搭载鲲鹏和英特尔至强CPU,效果有啥不一样?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目前,超图GIS基础软件产品已经与越来越多的国产CPU和国产操作系统完成适配测试和认证,如:龙芯、飞腾、华为鲲鹏等CPU,中标麒麟、银河麒麟等操作系统,本文将通过两个基础案例,对比测试分别搭载鲲鹏CPU和英特尔至强CPU的两款服务器的性能表现,以了解不同CPU在基础绘图计算以及SuperMap GIS基础功能方面的性能特点。
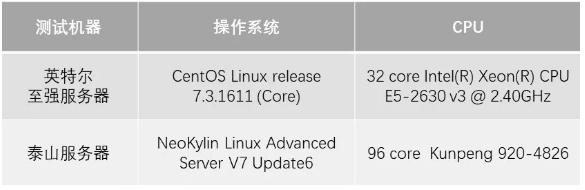
硬件及系统情况
参与测试的两款服务器的CPU和操作系统信息如下:
案例1:图元绘制
为了避免SuperMap GIS产品本身的特点影响大家对服务器性能的评判,也为了进一步分析出SuperMap产品的性能优化方向,特此研发了一个简单的模拟GIS地图出图过程中基础图元绘制的测试程序。该程序随机生成1000条由256个节点构成的线对象,并完成渲染,记录这一过程的耗时。同时,我们还增加了多线程情况下的对比测试,以考查各服务器的并发性能表现,结果如下:

从统计结果来看,在单线程下,英特尔至强服务器有一点优势,完成任务耗最少,但多线程并发方面,英特尔至强服务器的耗时随着并发线程数的增加而增多;然而,泰山服务器的多线程并发绘制耗时比较稳定,当并发线程数达到90以上时,耗时才会有明显增多。
可见,在多线程并发绘制的效率方面,泰山服务器优于英特尔至强服务器。
案例2:栅格瓦片生成
在SuperMap GIS众多的功能中,栅格瓦片生成是一个强IO、计算密集型操作,它将进行亿万次的地理数据坐标转换与图元绘制,因此,能较充分地呈现不同服务器的运行性能特点。测试采用SuperMap iObjects Java产品,对某省电子地图执行多进程生成栅格瓦片,瓦片比例尺级别为1至19级,瓦片存储类型为紧凑缓存,切图任务数为20,生成的瓦片总大小为11GB。对比在不同服务器下,分别使用16进程、30进程、60进程完成切图任务的耗时情况,结果如下:

从统计结果来看,在进程数较少时,英特尔至强服务器完成任务的耗时少于泰山服务器;随着进程数的增加,英特尔至强服务器完成任务的耗时并没有出现线性减少的趋势,而泰山服务器完成任务耗时明显呈线性减少,当进程数增大到30时,泰山服务器完成任务的耗时明显少于英特尔至强服务器;当进程数增大到60时,泰山服务器与英特尔至强服务器的耗时差距更为突出。
此外,英特尔至强服务器之所以在多进程完成任务方面性能不理想,与其x86架构的CPU的核数少于ARM架构的CPU的核数有关。目前,主流的x86架构的CPU的核数没能超过ARM架构的CPU的核数;而CPU核数确实能够带来性能的大幅提升,加上GIS功能对于多线程并发支持的能力越来越强,因此,泰山服务器的优势得以充分发挥。
总结
综合来看,对于包含了基础图元绘制和坐标计算的栅格瓦片生成,随着进程数的增加,ARM架构服务器完成任务的耗时线性减少,并最终少于x86架构服务器,这与多线程并发图元绘制的耗时分布趋势相吻合。可见,在实际应用中,ARM架构的服务器可以利用它的多核多线程优势,以较短的时间完成GIS任务,比英特尔至强服务器有更好的性能表现。
本次测试从基础GIS能力方面客观地展现了SuperMap GIS功能适配“国产操作系统+国产CPU”环境的良好性能表现,后续,SuperMap还将继续呈现其他GIS功能的适配性能情况,并将继续攻坚,让更多的GIS功能更高性能地运行在“国产操作系统+国产CPU”上。
这篇关于数据说话:GIS搭载鲲鹏和英特尔至强CPU,效果有啥不一样?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




