本文主要是介绍分析openGauss包内集合类型的实现方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
Oracle中集合类型覆盖了Postgresql数组的功能,在Oracle用户中时非常常用的。
尤其是包内定义的集合类型,在SPEC定义后即可直接使用,scope也只在包在生效,使用非常灵活。
开源PG因为有数组没有实现这部分语法,下面对openGauss的包内集合类型实现方法做一些分析。
总结
- 构造类型:plpgsql_build_tableType
- 构造变量:build_array_type_from_elemtype
- 一层嵌套var中没有nesttable
- {1,2,3,4}直接存到var中。
- 两层嵌套var中有nesttable,从nesttable构造子元素,然后插到var中。
- nesttable构造{1,2,3}、nesttable构造{1,2}、nesttable构造{1,2,3,4,5}
- 三个元素插入var中:{{1,2,3}, {1,2}, {1,2,3,4,5}}
- 三层嵌套var中有两层nesttable
- 最底层nesttable构造基础类型数组两个,例如{1,2,3,4,5}、{1,2}
- 中间层包装最底层数组{ {1,2,3,4,5}、{1,2} }
- 顶层包装中间层数组{ { {1,2,3,4,5}、{1,2} } }
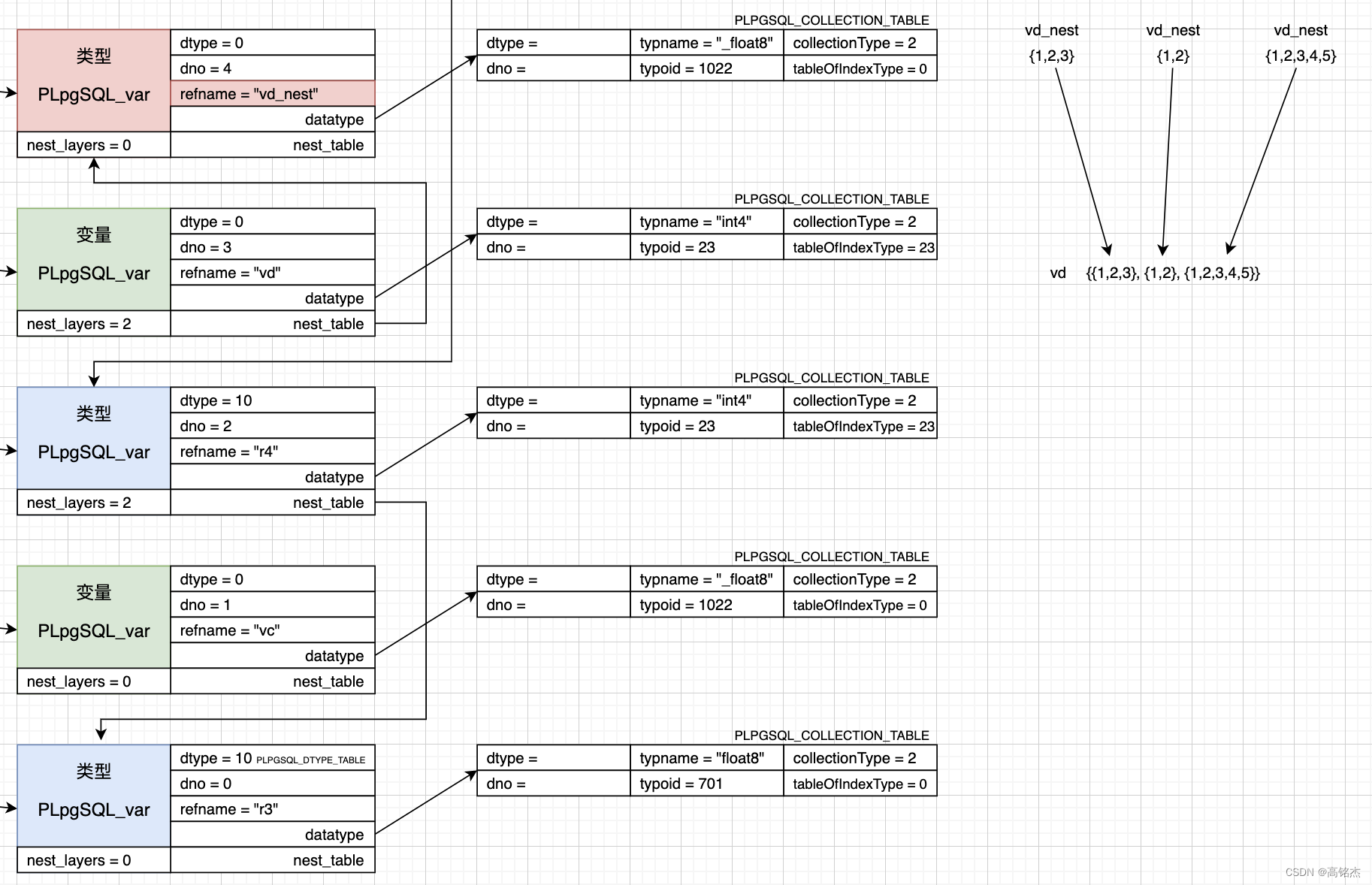
底层用的还是PG的数组。核心逻辑都在evalSubsciptsNested函数附近。
用例
drop schema if exists pkg_val_1 cascade;
drop schema if exists pkg_val_2 cascade;create schema pkg_val_1;
create schema pkg_val_2;set current_schema = pkg_val_2;
set behavior_compat_options='allow_procedure_compile_check';--test package val assign
create or replace package pck1 is
type r3 is table of float;
vc r3;
type r4 is table of r3;
vd r4;
type r5 is table of r4;
ve r5;
end pck1;
/
create or replace package body pck1 is
end pck1;
/create or replace package pck2 is
ve int;
procedure p1;
end pck2;
/
create or replace package body pck2 is
procedure p1 as
begin
pck1.vc(1) := 1;
pck1.vc(2) := 2 + pck1.vc(1);
pck1.vd(1) := pck1.vc;
pck1.vd(2) := pck1.vc;
pck1.ve(1) := pck1.vd;
raise info '% % % %', pck1.vc(1), pck1.vd(1)(1), pck1.vd(1)(1), pck1.ve(1)(1)(2);
end;
end pck2;
/
call pck2.p1();
3 pck1编译
create or replace package pck1 is
type r3 is table of float;
vc r3;
type r4 is table of r3;
vd r4;
type r5 is table of r4;
ve r5;
end pck1;
/
堆栈
CreatePackageCommandPackageSpecCreateplpgsql_package_validatorplpgsql_pkg_compiledo_pkg_compileplpgsql_yyparse
变量列表和PG的差异
| 区别 | openGauss | PostgreSQL |
|---|---|---|
| 变量数 | u_sess->plsql_cxt.curr_compile_context->plpgsql_nDatums | plpgsql_nDatums |
| 变量列表 | u_sess->plsql_cxt.curr_compile_context->plpgsql_Datums | plpgsql_Datums |
| 包变量数 | u_sess->plsql_cxt.curr_compile_context->plpgsql_pkg_nDatums | 无 |
| 包变量列表 | u_sess->plsql_cxt.curr_compile_context->plpgsql_Datums | 无 |
怎么区分编包函数编函数?
u_sess->plsql_cxt.curr_compile_context->plpgsql_curr_compileplpgsql_curr_compile非空则是编函数,使用u_sess->plsql_cxt.curr_compile_context->plpgsql_nDatumsu_sess->plsql_cxt.curr_compile_context->plpgsql_Datumsplpgsql_curr_compile空则是编包函数,使用u_sess->plsql_cxt.curr_compile_context->plpgsql_pkg_nDatumsu_sess->plsql_cxt.curr_compile_context->plpgsql_Datums注意变量列表是一套plpgsql_Datums
命名空间区别:
| openGauss | PostgreSQL | |
|---|---|---|
| 命名空间区别 | u_sess->plsql_cxt.curr_compile_context->ns_top | ns_top |
| 命名空间结构体区别 | int itemtype; | PLpgSQL_nsitem_type itemtype; |
| int itemno; | int itemno; | |
| struct PLpgSQL_nsitem* prev; | struct PLpgSQL_nsitem *prev; | |
| char name[FLEXIBLE_ARRAY_MEMBER]; | char name[FLEXIBLE_ARRAY_MEMBER]; | |
| char* pkgname; | ||
| char* schemaName; |
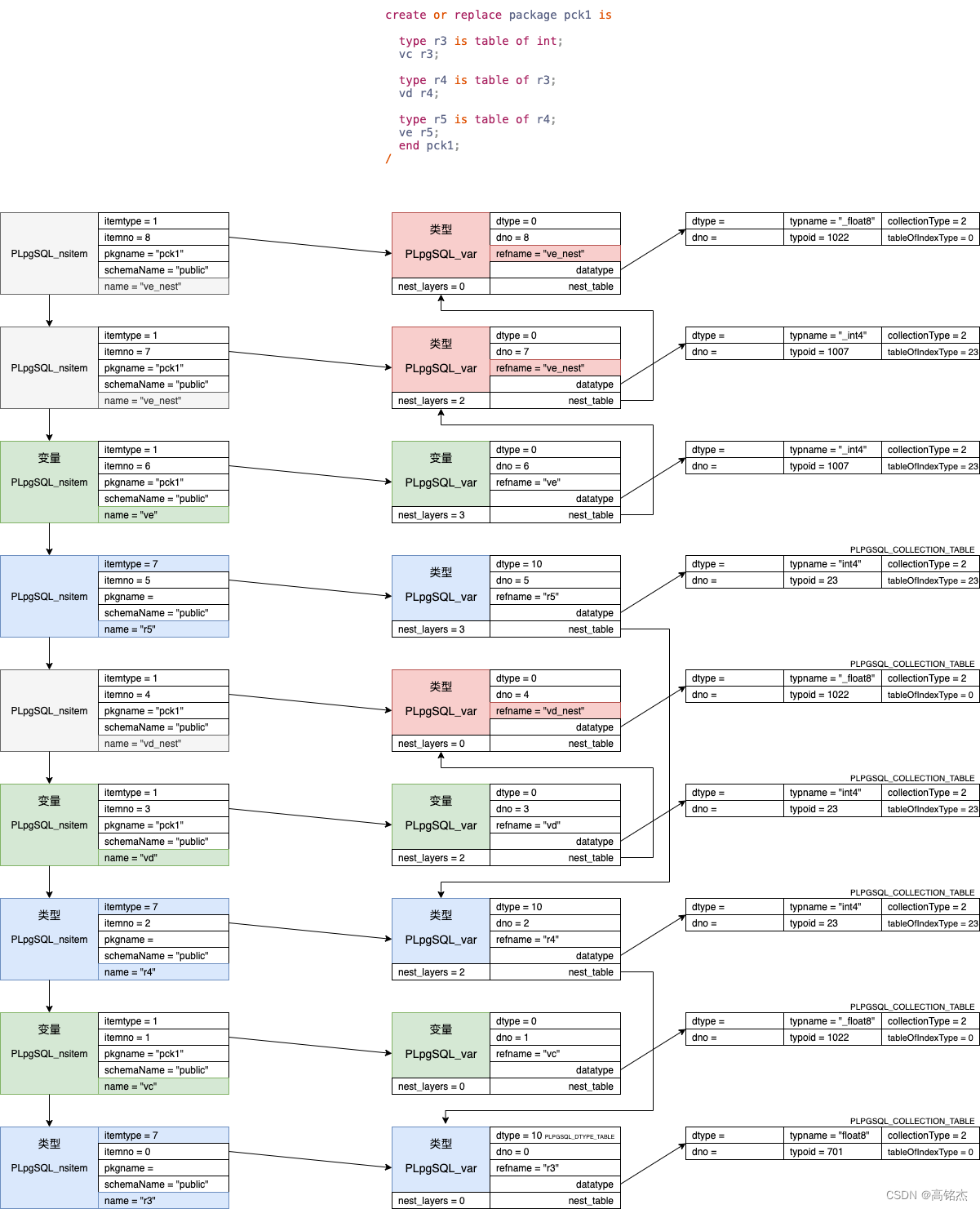
3.1 pck1编译结果
- 语法解析时走plpgsql_build_tableType函数构造类型。
- 语法解析时走build_array_type_from_elemtype构造集合类型。
从编译结果来看:
- 一层嵌套表类型,只需要自己的datatype是_float8数组类型就ok了,参考下图中变量"vc"。
- 两层嵌套表类型,var会创建nest_table变量指向内层数组类型,参考下图中变量"vd"。
- 三层嵌套表类型,var会创建nest_table变量→nest_table变量,两层变量记录内层数组类型,参考下图中变量"ve"。
3.2 调用者pck2执行结果
create or replace package pck2 is
ve int;
procedure p1;
end pck2;
/
create or replace package body pck2 is
procedure p1 as
begin
pck1.vc(1) := 1;
pck1.vc(2) := 2 + pck1.vc(1);
pck1.vd(1) := pck1.vc;
pck1.vd(2) := pck1.vc;
pck1.ve(1) := pck1.vd;
raise info '% % % %', pck1.vc(1), pck1.vd(1)(1), pck1.vd(1)(1), pck1.ve(1)(1)(2);
end;
end pck2;
/call pck2.p1();pck1.vc(1) := 1;
PLpgSQL_stmt_assign
PLpgSQL_stmt_assign = { cmd_type = 1, lineno = 3, varno = 11, expr = {dtype = 7, dno = 0, query = "SELECT 1"}, sqlString = "pck1.vc(1) := 1;"
}
varno = 11 PLpgSQL_tableelem
PLpgSQL_tableelem = {dtype = 6, dno = 11, ispkg = false, subscript = {query = "SELECT 1"}, tableparentno = 10, parenttypoid = 0, parenttypmod = 0, tabletypoid = 0, tabletypmod = 0, tabletyplen = 0,elemtypoid = 0, elemtyplen = 0, elemtypbyval = false, elemtypalign = 0 '\000', assignattrno = -1, pkg_name = 0x0, pkg = 0x0
}
运行时exec_assign_expr
- 计算右值:exec_eval_expr得到1。
- 结果赋值:exec_assign_value,赋值中走PLPGSQL_DTYPE_TABLEELEM分支。通过tableparentno=10找到数组结构,然后往数组结构中赋值即可。
pck1.vc(2) := 2 + pck1.vc(1);
PLpgSQL_stmt_assign
PLpgSQL_stmt_assign = { cmd_type = 1, lineno = 4, varno = 12, expr = {dtype = 7, dno = 0, query = "SELECT 2 + pck1.vc[1]"}, sqlString = "pck1.vc(2) := 2 + pck1.vc(1);"
}
varno = 12 PLpgSQL_tableelem
PLpgSQL_tableelem = {dtype = 6, dno = 12, ispkg = false, subscript = {query = "SELECT 2"}, tableparentno = 10, parenttypoid = 0, parenttypmod = 0, tabletypoid = 0, tabletypmod = 0, tabletyplen = 0,elemtypoid = 0, elemtyplen = 0, elemtypbyval = false, elemtypalign = 0 '\000', assignattrno = -1, pkg_name = 0x0, pkg = 0x0
}
运行时:和上述类似。
pck1.vd(1) := pck1.vc;
PLpgSQL_stmt_assign
PLpgSQL_stmt_assign = { cmd_type = 1, lineno = 5, varno = 14, expr = {dtype = 7, dno = 0, query = "SELECT pck1.vc"}, sqlString = "pck1.vd(1) := pck1.vc;"
}
varno = 14 PLpgSQL_tableelem
PLpgSQL_tableelem = {dtype = 6, dno = 14, ispkg = false, subscript = {query = "SELECT 1"}, tableparentno = 13, parenttypoid = 0, parenttypmod = 0, tabletypoid = 0, tabletypmod = 0, tabletyplen = 0,elemtypoid = 0, elemtyplen = 0, elemtypbyval = false, elemtypalign = 0 '\000', assignattrno = -1, pkg_name = 0x0, pkg = 0x0
}
运行时:
- 右值计算:exec_eval_expr拿到vc数组。
- 左值计算:exec_assign_value进入PLPGSQL_DTYPE_TABLEELEM。开始找数组target
- 1 找到的目标数组是
{dtype = 0, dno = 3, refname = 'vd'},然后找到nested_table指向的{dtype = 0, dno = 9, ispkg = true, refname = "vd_nest"} - 2 这里会递归进入exec_assign_value,这次的目标是dno=9的vd_nest。
- 3 把值赋给dno=9的vd_nest。
- 1 找到的目标数组是
总结

这篇关于分析openGauss包内集合类型的实现方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






