本文主要是介绍漏斗分析:你可能低估了它的复杂度(逻辑细节及产品化),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
来源:首席数据科学家
“ 漏斗分析应该是互联网中的最基础的分析了。”
与《RFM分析》《留存分析》《归因分析》《用户路径分析》不同的是,大部分互联网从业者,都听过漏斗分析。但对于漏斗分析的细节,你确定了解吗?漏斗分析可不只是简单的几个递减、转化率哦~下面,和大家一起聊聊具体的逻辑。
01
—
什么是漏斗分析
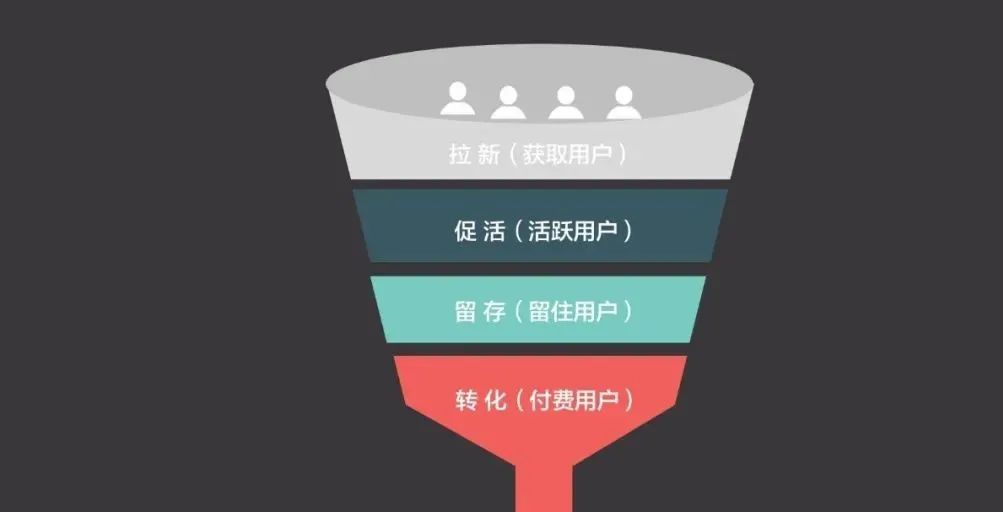
提到漏斗分析,大家都能想到下图:

从图中我们可以了解到漏斗分析的基础特征:(1)是分多层、多环节的(2)各环节是有转化率(或者流失)效应的(3)环节之间有先后顺序
总结一下,漏斗分析是分析用户从起始到终点环节,过程当中每一步环节的转化(或者流失)情况。通过漏斗,可以找出全链路业务的问题环节所在,从而进行针对性优化。
说到这里,大家可能也都是了解的。但是,如果谈到细节逻辑呢?比如,用户从漏斗中间环节进入,是否要计算?在给定的范围内如果发生了其他未定义的行为,该如何处理?等等。下面咱们来具体聊聊。
02
—
漏斗分析的计算逻辑
这里介绍一下漏斗分析的详细逻辑。
(1)明确时间范围等筛选条件
这是计算漏斗的第一步。
常用的筛选条件主要是时间范围及用户类型。当然,其他的筛选维度(比如设备类别等)理论上也是可以支持的,但时间范围的筛选是漏斗计算必不可少的。是统计近7天的漏斗转化,还是近30天的转化?等等。
确定好时间范围,将时间范围内的数据搂出来,是计算漏斗的首要前提。
(2)确定漏斗的划分阶段及条件
确定好了时间范围,接下来需要确定漏斗的整体阶段划分。
每个漏斗,至少需要包含两个阶段(不然称不上漏斗)。每个阶段,基本设定就是【事件类型】+【筛选条件】。
关于筛选条件,通常来讲都是针对当前阶段进行的限制。但有时多个阶段之间需要进行打通。拿电商的环节举例。有时分析师想看的是浏览、加购且下单了同一个sku的数据(因为有可能有用户浏览了A商品,但是加购下单了B商品,这种情况不是我们想统计的漏斗转化),那这时,在筛选条件这需进行特殊处理,即打通多个阶段之间的关联。
在神策中,是用【属性关联】的概念实现了多个阶段的筛选逻辑处理。
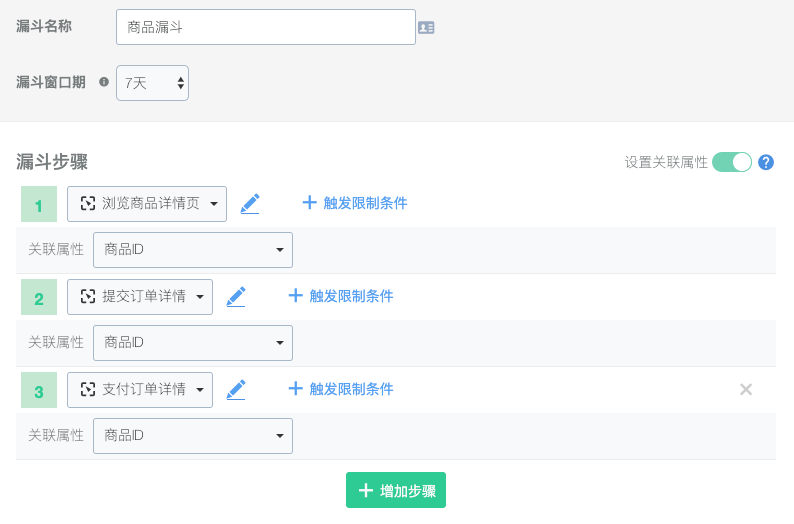
这一个步骤,相当于把用户全量行为中,符合本次漏斗的行为数据筛选出来,以备后续的计算。
(3)关于漏斗的类型
接下来,进入到漏斗流程的计算环节。
假设我们想看的转化流程是A→B→C→D→E。那么如果经过上面几个数据处理之后,有以下几个路径,我们该怎么处理呢?
路径1:A→B→C
路径2:C→D→E
路径3:A→B→D→E
路径4:A→B→X→C→D
在聊上面路径之前,先聊一下漏斗的分类:【封闭式漏斗】和【开放式漏斗】。
所谓封闭式漏斗,就是只有从整体漏斗的第一个阶段进入的路径,才统计在漏斗当中。因此在这种逻辑下,路径2就不会统计在我们漏斗分析中了,因为没有从第一阶段发起。通常情况下,我们进行漏斗分析,都是基于封闭式进行的,这样可以确保看到每个环节的真实转化。
所谓开放式漏斗,就是从整体漏斗中的任意一个环节进入的路径,均计入整体漏斗的统计。这种逻辑下,路径2是会统计到漏斗中的,哪怕是单独的发生一个环节(例如C)也会计入整体。这其实是广义的漏斗概念。但是很多场景下是有这个需求的(回头分享我正在做的针对大促场景项目,正是基于开放式的逻辑)。
因此,在封闭式漏斗下,路径3会处理为在B环节发生了流失;而在开放式漏斗中,路径3 其实是处理成了两个环节:A→B,D→E,然后分别计入到漏斗中。
路径1就不用赘述了,无论是啥类别,都是记为C环节的流失。那路径4呢?请继续看。
(4)两个相邻阶段之间的逻辑
到这里,我们还要关注一下两个相邻阶段之间的逻辑。主要包括其他环节干扰的处理,以及窗口期逻辑。
路径4的关键是两个阶段中间发生了其他的行为环节X。这个需要定义是否纳入计算。在神策中,这种环节是直接剔除的,因此认为路径4完成了漏斗;但是在GA中,进行了更灵活的处理,支持用户决定是否通过。
另外一个,就是决定是否要设置窗口期。所谓窗口期,即完成两个阶段之间的时间间隔。若大于某个阈值,即使符合我们上面的各类条件,也不认为是完成了漏斗转化。
(5)漏斗的统计
最后,就是计算各阶段的用户数量、进而计算一下转化率等,是水到渠成的事了,这里就不赘述了。关键还是上面环节的数据计算,比较复杂。
以上是漏斗分析中的主要计算逻辑。
03
—
产品化实现及行业案例
我们这里主要以Google analysis和神策分析为例,看一下两个典型BI产品中的漏斗分析,是如何设计的。
(1)Google Analysis
GA中的漏斗分析主要有两个:一个是在普通版中的漏斗分析,一个是在GA360(即付费版本)中的自定义漏斗分析。
关于漏斗分析,主要的功能配置项有以下:
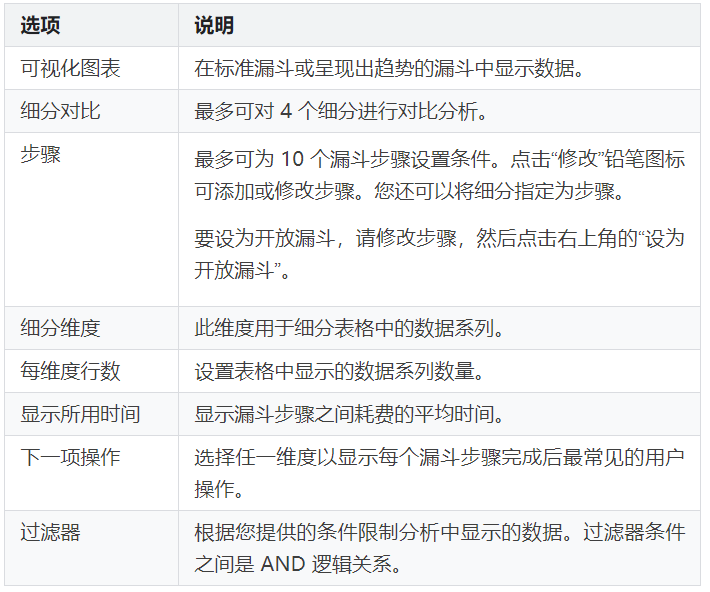
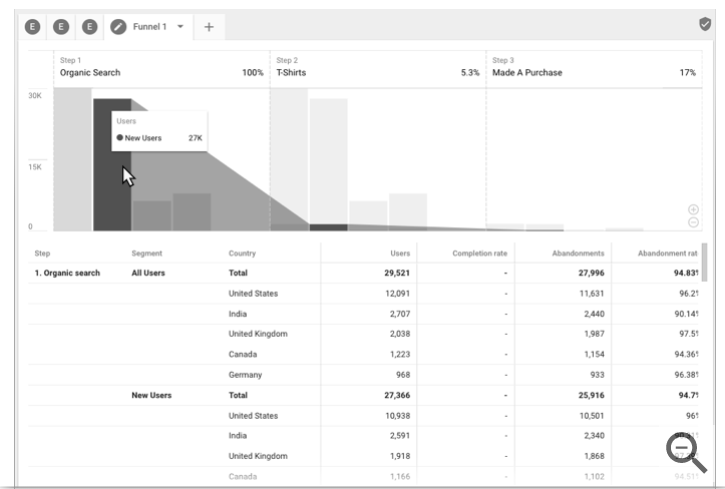
谷歌分析的截图,实在是没有了,就有以下的参考图了:
(2)神策分析
神策分析,能调研的内容范围多一些。
首先看一下神策漏斗分析的报告页:
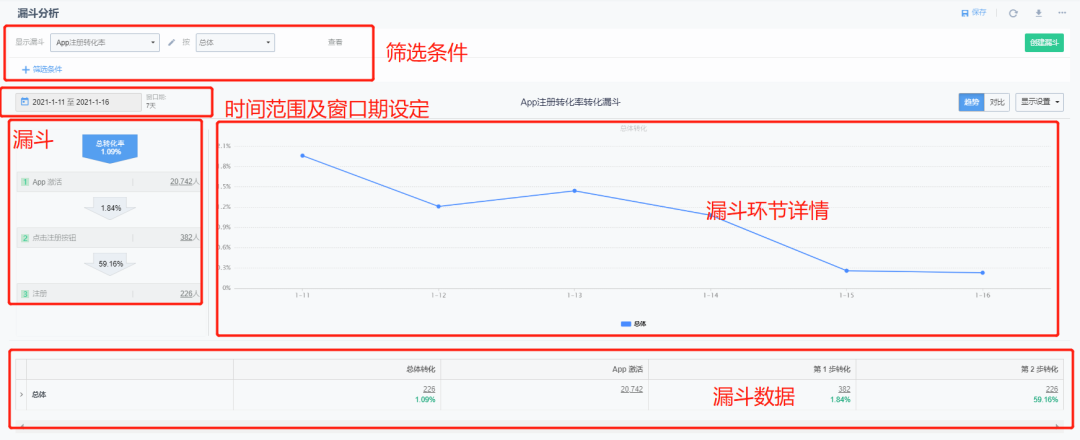
上面针对各个主要模块,进行了标注,就不详细展开了。总体来讲,产品设计的是比较合理的,用户既可以看到漏斗情况,又可以针对每个漏斗环节进行详细分析。
这里针对漏斗的计算逻辑,说一下,神策直接使用了【封闭式漏斗】,没有给用户可选的余地。这是个比较强的逻辑,但也比较通用吧。
下面是创建漏斗的过程:
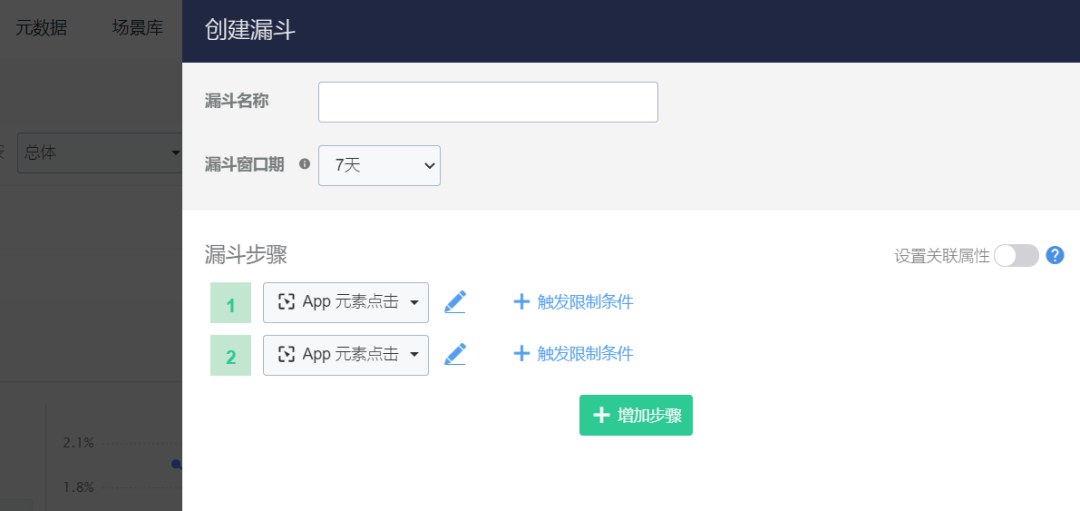
神策在这里可以设定窗口期,但是针对的是整体漏斗第一步到最后一步的窗口,而不是任意两个阶段之间的。另外,在报告页,时间筛选时,用户可以不使用窗口期。
对于【关联属性】在上文中有截图了,个人觉得这个还是挺好的一个设计。但用户的理解需要一点基础才行。
以上是关于漏斗分析及产品化的一些分享,欢迎大家继续关注~
这篇关于漏斗分析:你可能低估了它的复杂度(逻辑细节及产品化)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






