本文主要是介绍模型部署 - BevFusion - (1) - 思路总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模型部署实践 - BevFusion
- 思路总结
- 一、网络结构 - 总结
- 1.1、代码
- 1.2、网络流程图
- 1.3、模块大致梳理
- 二、Onnx 的导出 -总体思路分析
- 三、优化思路总结
学习 BevFusion 的部署,看了很多的资料,这篇博客进行总结和记录自己的实践
思路总结
对于一个模型我们要进行部署,一般有以下几个开发流程或思路:
- PyTorch 转 ONNX 转 TRT
- FP16 优化
- cuda-graph 优化
- INT8 量化优化
- ONNX 模型层面优化
- Pipeline 优化
- 模型内深度优化
我们需要先快速的去了解网络,然后将其转换成 Onnx 和 Tensorrt,然后再去根据结果进行二次优化
一、网络结构 - 总结
1.1、代码
Pytorch 代码:https://github.com/mit-han-lab/bevfusion
CUDA-BEVFusion 部署代码:https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution/tree/master/
1.2、网络流程图
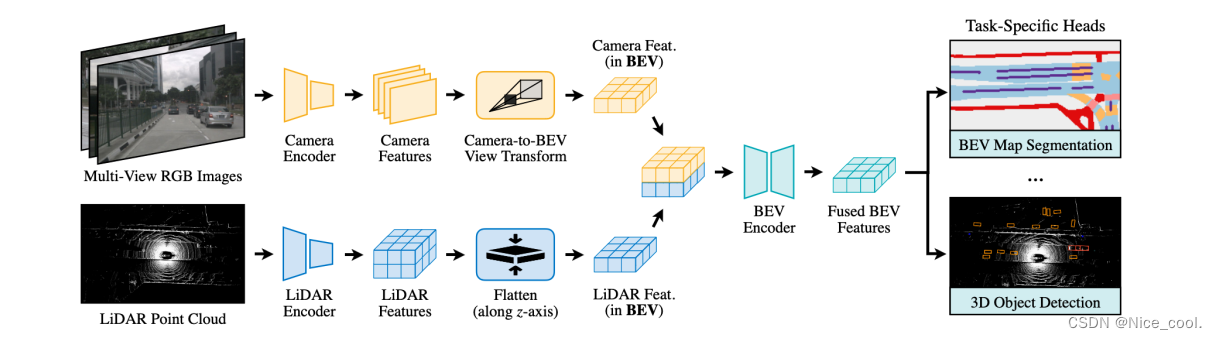
1.3、模块大致梳理
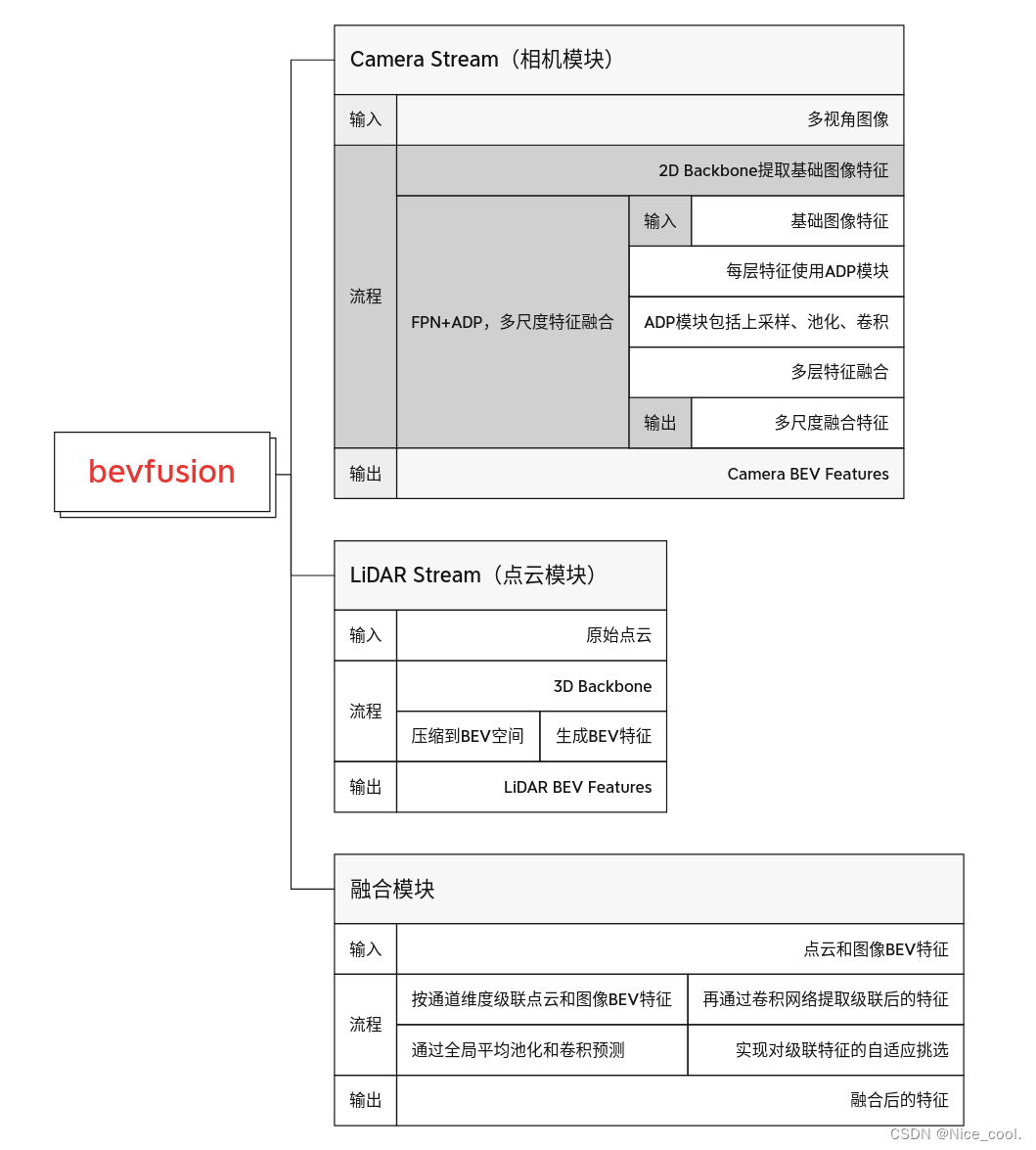
二、Onnx 的导出 -总体思路分析
在 CUDA-BEVFusion 的代码中一共有五个 onnx ,说明作者是分模块来导出 onnx 的。
| 模块 | onnx 名称 |
|---|---|
| Camera | camera.backbone.onnx |
| Camera | camera.vtransform.onnx |
| Fuse | fuser.onnx |
| Lidar | lidar.backbone.xyz.onnx |
| decoder + post | head.bbox.onnx |
- (1) 在 Camera 模块 中导出了两个 onnx,为什么要分两个 onnx 导出?
-
因为 bev_pool 中有个下采样的部分,会影响整个onnx的导出,所以才选择分开两个 onnx。第一个是backone相关的,第二个是bev_pool相关的
(2) Camera 的 backone 为什么选择了 Resnet50? -
源代码的 backone 是选择了SwinTransform,但是由于 bev_pool 有大量的计算,并且SwinTransform含有大量的复杂计算,所以在部署的时候会选择 Resnet50,因为它结构简单,容易做量化且精度不会损失太大。
(3) 如何导出 bev_pool ? -
有两种方式实现。
-
方法一: 做成 Plugin,但是这样太麻烦,所以不太推荐
-
方法二:使用核函数实现,分成三个部分(
subclass机制) -
- bev_pool之前用onnx;
-
- bev_pool不导出onnx,用cuda核函数实现;
-
- bev_pool后的 downsample使用 onnx
(4) lidar模块如何导出 onnx? -
因为模块中包含 spconv ,pytorch不能直接导出onnx,所以使用 onnx.helper 自定义导出 onnx
(5) decoder部分为什么不能用int8? -
因为模块中包含 transformer,并且Tensorrt推理中容易出现 NAN(这种情况极难解决)
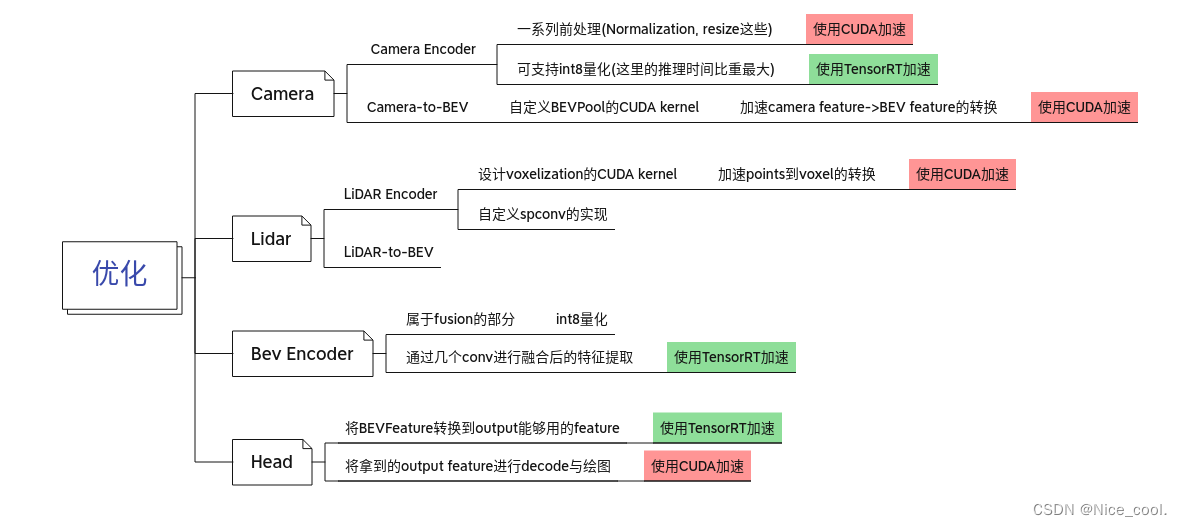
三、优化思路总结
这篇关于模型部署 - BevFusion - (1) - 思路总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







