本文主要是介绍Elasticsearch:解决并发写入导致版本冲突异常version_conflict_engine_exception,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
「问题描述:」
数据同步中,在使用阿里云Elasticsearch7.10.0版本的集群作为目标数据源时,在连续写入同一文档(document)出现版本冲突问题。
注意:以下所述均以阿里云7.10.0版本的Elasticsearch集群为前提(不同版本可能会稍有不同)
「异常信息:」
以生产环境的错误日志信息为例:
|
|
当Elasticsearch在写入或者删除的时候出现错误version_conflict_engine_exception时,表示当前写入或删除存在版本冲突。此时,status为409.
注意:在异常信息中返回的信息中,存在两个名词,它们的名称和含义分别是(新版本中会建议我们使用):
|
|
「版本冲突的实质:」
理解版本冲突的实质,首先要理解elasticsearch的写入流程:Elasticsearch之图解写入流程
一般我们在更新文档时,主要的操作流程是:读取文档->修改->提交保存。数据中心等保存的都是最新一次提交的内容。
正常来说没什么问题,但是如果两个或者更多的请求并发修改同一个文档时,很容易产生冲突。如果按照先后顺序,则最后被处理的请求可能覆盖首先被处理的请求作出的操作和变更,从而导致其数据变更丢失(最后被处理的请求也不一定是最后发起的,可能会受到网络传输等因素影响)。
在并发冲突的时候,我们有常用的两种策略:
1.悲观锁并发策略:
在关系型数据库中,通过阻塞并排队的方式,来避免发生冲突。例如在读取数据时阻塞,来保证正在修改行数据的请求完成正常操作后,能够读取到最新的数据。这种方式的前提假设是数据冲突更有可能发生。
优点:方便,直接加锁,对应用程序来说透明,不需要额外的操作。
缺点:并发能力很低,同一时间只有一条线程操作数据。
2.乐观锁并发策略:
乐观锁假设多用户并发的事务在处理时不会互相影响,各事务能够在不产生锁的情况下处理各自影响的那部分数据,在提交数据更新之前,每个事务会先检查在该事务读取数据后,有没有其他事务又修改了该数据。如果其它事务有更新的话,正在提交的事务会进行回滚。相对于悲观锁,在对数据库进行处理的时候,乐观锁并不会使用数据库提供的锁机制。一般实现乐观锁的方式就是记录数据版本。
数据版本是为数据增加一个版本标识,当读取数据时,将版本标识的值一同读出。数据每更新一次,同时对版本标识进行更新。当我们提交更新的时候,判断数据库表对应记录的当前版本信息与第一次取出来的版本标识进行比对,如果数据库表当前版本号与第一次取出来的版本标识值相当,则予以更新,否则认为是过期数据。
实现数据版本有两种方式,第一种是使用版本号,第二种是使用时间戳。
优点:并发能力很高,不给数据加锁,可以进行大量线程并发操作。
缺点:麻烦,每次更新的时间都要先比对版本号,然后可能需要重新加载数据,再次修改,再写;这个过程可能要重复好几次。
Elasticsearch中采用的是乐观锁的并发策略,这种方式的前提假设是数据冲突一般不会发生,从而避免阻塞数据请求。然而,在读和写之间,如果数据发生改变,更新就失败了,然后由程序决定如何进行后续的处理。
3.Elasticsearch 内部如何基于_version进行乐观锁并发控制:
Elasticsearch的修改,如果没有带上version的时候,直接替换原来的文档,没有查询过程,多线程操作,不区分执行的先后顺序。这时候Elasticsearch并不阻止别的线程修改这条数据,极大的可能会出现数据回流或数据覆盖。
Elasticsearch是分布式的,文档的创建/变更等都会同步到其他节点。由于其异步性和并发的特点,这些同步请求都是并行的,因此并不能保证数据是按照修改顺序依次到达的。Elasticsearch保证了一个老版本的数据永远无法重写或覆盖新版本的数据。
在index get 和 delete 请求中,都存在一个_version 字段。数据的变更会导致_version的值递增。第一次创建一个document的时候,它的_version内部版本号就是1;以后,每次对这个document执行修改或者删除操作,都会对这个_version版本号自动加1。哪怕是删除,也对这条数据的版本号加1。
其实,每次删除一个document并不是立即进行物理删除的,因为它的一些版本号信息还保留着,比如先删除一条document,再重新创建这条document,会发现新建的这条document的_version版本号的值取自删除时_version的值再加1.
具体demo:ElasticSearch如何处理并发冲突
「解决方案:」
方案一:retry策略
retry策略,Elasticsearch再次获取document数据和最新版本号,成功就更新,失败再试;比如,设置尝试5次更新,retry_on_conflict=5,代表着最大更新5次,5次后不再尝试写入并且抛出异常。需要注意的是,retry策略在增量操作的无关顺序的场景中更适用,比如计数操作,数据写入的先后顺序对最终结果关系不大。其它的一些场景,比如库存的变化,订单的状态,直接更新为指定数值的,retry策略都不适用。除非可以在业务中将数据写入由顺序有关转化成顺序无关,才可以使用retry策略。
方案二:回调写入
简单粗暴的方式,如果遇到status=409的异常直接回调当前写入方法重新写入,直到写入成功为止。以java代码为例,捕获到的异常为ElasticsearchStatusException。本以为当前方案会对Elasticsearch集群造成一定不良影响,但经过一周的观察,Elasticsearch集群的监控指标(包含GC频次)并无异常,但不能保证在更大的数据量级中不会发生其它异常。
优点:开发成本低,可以解决retry策略无法解决的顺序写入的问题,回调写入方法即可。
缺点:
1.尝试写入的次数很高,且无法预估在大数据量级中直接回调写入会对集群性能造成何种影响,即使对集群进行扩容升级,也会变相提高成本。
2.线程消亡或者等待队列溢出会造成数据丢失。
3.如果当前写入执行了多次的回调写入,那么势必会影响分配到当前线程的其它写入,造成数据延迟,当然也可以通过加大线程池、升级服务器的方式提高性能,但毕竟是治标不治本的方法,一旦产生业务侧不可接受的延迟依然很麻烦。
方案三:延时写入
直接回调写入会造成更多的版本冲突发生,虽然可以解决问题但依然存在风险。结合对Elasticsearch的写入机制的深入理解,尝试跳出Elasticsearch本身,在业务侧解决Elasticsearch频繁更新同一document时出现的版本冲突异常。
延时写入,见文知意,即将写入请求延迟处理。
一、使用Redis作为中间缓存,将一段时间内的同一document的写入请求缓存,key为documentID,value为变更字段的k-v格式。在这段时间内,后写入的覆盖先写入的,也就是将写入请求合并,只更新一次。
二、将写入失败的数据发送到rocketmq的队列中,按照documentID分区,做延时写入,顺序消费。
优点:1.实现顺序写入,写入频次降低,大大降低并发冲突的发生。
2.将数据存储在缓存和消息队列,保证数据不会丢失。
缺点:
1.在本就存在显示延迟的基础上,加大了延迟,具体的延迟指标需要结合集群规格,数据量级等综合考虑。
2.容易造成消息堆积,如果消费出现异常需要重新消费。
方案四:Redis 外部版本号 + setNx锁 + rocketmq
流程图如下:
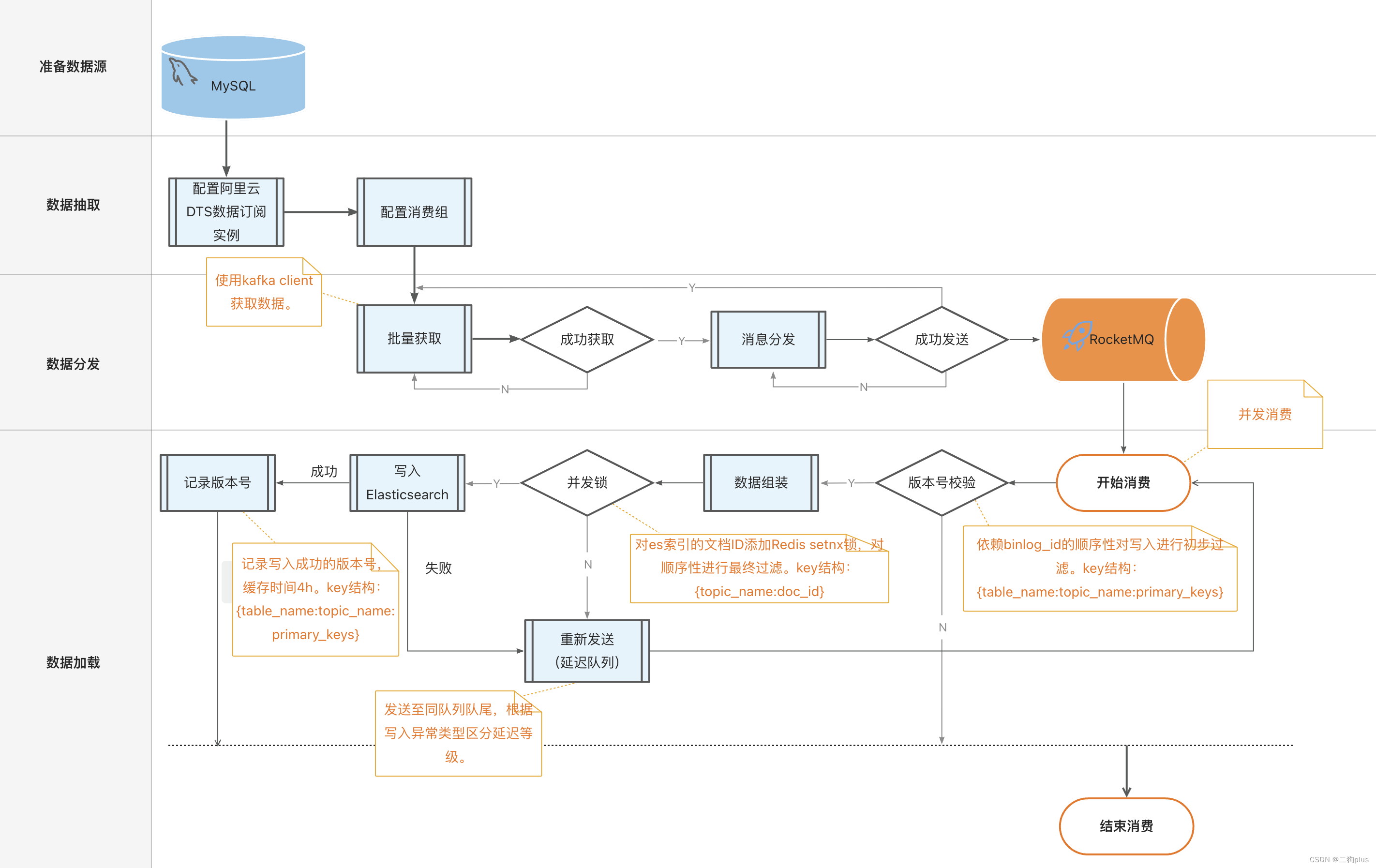
将采集到的binlog写入rocketmq的队列中(多队列),然后并发消费这些数据。使用表名为key,binlogID为value,在每次写入之前校验当前binlogID与Redis中存储的binlogID的大小,作为判断是否同步的条件,之后用Redis的setNx锁,锁住docID,目的是保证并发条件下,同一doc只有一次更新。如果以上两次校验有任何一次发生版本号异常,那么将此条消息原封不动的发送至队尾,并设置延迟消费(延迟级别根据具体情况分析),执行写入方法后catch出版本号异常,如仍存在版本号异常,即同样将消息发送至队列队尾,延迟消费。
以上简述的方案,虽然不能从根本上解决版本号异常的问题,但是却可以大大减少版本号异常发生的频次,同时也可以降低写入次数,并且当前文档更新的阻塞不会影响后续的数据同步,基本上解决了版本号异常对数据同步造成的堆积延迟。
目前使用的这种方案,还未出现数据丢失或者延迟过高的情况,集群状态也比较健康。在此方案中,需要注意的是延迟消费的级别与幂等锁的时间(我所使用的延迟消费级别为:2(5s),幂等锁时间:1500ms).
经过多次时间,以上四种方案中,方案四最为稳妥。如各同僚有更好的方案,或者对文档中的内容有什么疑惑,可以留言或者私信。
这篇关于Elasticsearch:解决并发写入导致版本冲突异常version_conflict_engine_exception的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






