本文主要是介绍南瓜树数据平台——共享数据API服务平台(后端的利器,前端的神器),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文档是针对南瓜树数据管理平台的数据服务模块功能及使用说明。对第三方客户就如何使用数据平台开发API服务进行说明。
本文档可帮助:
- 后端开发人员快速开发数据接口服务;
- 不具备服务开发的前端人员也能开发自己的应用;
- 维护人员快速进行API服务的在线动态升级和维护
- 第三方公司快速实现业务接口。
建设背景
当前软件的开发流程耗时较长,从需求部门提出需求到需求上线需要一个较长的时间周期,当程序出现问题时,开发人员往往需要先定位问题,修复代码、发布程序版本;耗时长、影响业务开展。
系统目标
数据源接入南瓜树数据平台后,可通过编写SQL的形式快速开发数据接口服务,接口动态升级和维护;只需要简单编写sql,无需编写任何代码就能开发接口。
主要目标:
- 实现企业统一工作流流程管理;
- 实现企业统一数据管理;
- 可支持多种数据源管理;
- 可支持在线设计表单;
- 可支持多种数据源代码生成。
业务功能架构
总体业务功能架构:

第三方数据源接入
数据源的接入可支持二种方式:
- 用户自己有阿里云或者腾讯云的数据库:这是可根据用户的业务需求创建一个权限小的用户账号,用于接入数据平台进行相关数据服务API的开发;
- 用户无数据库,此时可联系客服进行租赁一个数据库进行使用。
具体接入操作:
1、进入菜单“数据服务》我的数据源”;
2、点击“新增”按钮;
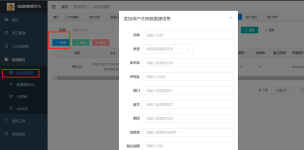
3、填写接入申请表单,填写完您的数据库信息后,点击“确定”按钮,提交申请;
4、管理员审核通过后,可在列表中看到数据源的“状态”列显示为“审核通过”;此时数据源就完成了接入了。

数据服务APi开发
数据源接入申请通过后,就可以进行数据服务的开发,菜单:“数据服务—数据服务API”;
新增数据API
- 进入列表后,点击“新增”按钮,打开新增页面;
- 选择需要进行API开发的数据源,填写数据服务的名称,便于见名知意;
- 根据业务要求编写sql,sql的编写规则在3.2.2 章节中进行说明;
- 填写使用方式和选择状态(只有发布状态下的api才可以被调用消费);
- 点击确定,保存成功;完成API的新增。
SQL规则
Sql编写注意
- 查看相关表是否有主键、索引、是否必填;
- Sql编写所在的库与接口所在的库要对应;
- Sql中where条件中顺序序:
能确定的情况下(主键/索引)条件>等值条件>in条件>exist/is not exists 条件>日期处理条件>is null/is not null 条件
- 过滤数据多的字段筛选条件放where 最前边,数据量大的表放在from 的最开始。
Oracle中,Where子句中条件的顺序对性能没有影响(不管是CBO还是RBO优化器模式),但不包含表的顺序。在RBO优化器模式下,表应按结果记录数从大到小的顺序从左到右来排列,因为表间连接时,最右边的表会被放到嵌套循环的最外层。最外层的循环次数越少,效率越高。
MySQL遵循最左前缀原理,当查询条件匹配联合索引的前面几列时,可以使用联合索引;否则,不会使用联合索引。
- 对于不确定前端是否会传入的参数,必须在条件两边有中括号{};
- 对于传入的参数占位符名称必须和前端传入的一致,且需要在参数两边用#包住,例如:#userId#.
API中sql编写动态参数传入
KPI开发中,数据源类型可以分为关系数据源类型(oracle\mysql\sqlserver\crdb),键值对数据源类型(es)。
在编写sql过程中我们需要针对不同的数据源类型,制定了相关的规则:
1、针对关系型数据源类型,再where条件编写是:
如果是=判断,则占位符用 # 前端传入参时不需要在参数两边拼接单引号

如果是in方式 ,则占位符用 $,前端入参时,需要在每个参数值的两边拼接上单引号。

2、针对ES数据源,在where条件编写时,只能使用占位符$ ,es不是关系型数据源,不支持 # 的方式:
如果是=判断,则需要用对应的:字段.keyword = $param$ ,前端传入参数需要拼接单引号
如果是 in 方式,则需要用:字段.keyword in($param$),前端入参时,需要再每个参数的两边拼接上单引号

3、针对ES的模糊查询方式:
如果是=判断,则需要用对应的:字段=$param$,前端传入参数需要拼接单引号
如果是in方式,则需要用:字段 in($param$),前端入参时,需要在每个参数的两边拼接上单引号。
对于能确定的参数是必传的,则需要把该参数两边的大括号“}”去掉,避免前端做压测还是其他测试时不传参数进来,从而导致我们进行全表扫描增大业务库或中台数据库的访问压力。
具体使用说明
1.1 、针对关系型数据源类型,再where条件编写是:
如果是 = 判断 ; 则占位符用 # 前端传入参时不需要在参数两边拼接单引号:
如果是 in 方式 ; 则占位符用 $ 前端入参时,需要在每个参数的两边拼接上单引号。
1.2、 针对ES数据源,在where条件编写时,只能使用占位符 $ , es不是关系型数据源,不支持 # 的方式:
如果是 = 判断,则需要用 字段.keyword = $param$ 前端传入参数需要拼接单引号;
如果是 in 方式,则需要用 字段.keyword in($param$),前端入参时,需要再每个参数的两边拼接上单引号。
3、针对ES的模糊查询方式:
如果是 = 判断,则需要用对应的 字段 = $param$ 前端传入参数需要拼接单引号
如果是 in 方式,则需要用 字段 in($param$) 前端入参时,需要在每个参数的两边拼接上单引号
API服务验证
验证方式
服务编写完成后,需要进行测试验证,平台支持以list或者map的形式进行数据的返回。可根据业务的需求进行响应的选择:
| 序号 | 返回格式 | 调用方式 | 说明 |
| 1 | List | http://qxsdcloud.com:18083/data/getMessageList | 以数组的形式返回 |
| 2 | Map | http://qxsdcloud.com:18083/data/getMessageRow | 以键值对的形式返回 |
入参
服务编写完成后,必须传入三个参数,其中,param参数中需要把传入的参数进行封装成键值对的形式传入
| 序号 | 参数名称 | 说明 | 示例 |
| 1 | ApiCode | API编码,在数据服务API列表中可获取 | 9129bde5e705402fb61f93176f8fbf01 |
| 2 | requestDev | 请求设备,用户自定义 | custom |
| 3 | param | 参数封装后的json串 | {“userId”:1} |
List返回结果:

Map返回结果

请求日志
在菜单“数据服务—api日志”菜单中,可以查看到请求的日志明细,可根据日志来分析:
- 接口的请求频率;
- 前端传入的参数情况;
- 接口的报错信息

产品在2020年已上线第一版,截至到2021年6月14日;已完成基础功能;现诚邀各行业人员加入试用。
试用地址:http://qxsdcloud.com:18081/
这篇关于南瓜树数据平台——共享数据API服务平台(后端的利器,前端的神器)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



