本文主要是介绍Python实现EMV工具判断信号:股票技术分析的工具系列(2),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Python实现EMV工具判断信号:股票技术分析的工具系列(2)
- 介绍
- 算法解释:
- 优势:
- 劣势:
- 代码
- rolling函数介绍
- 核心代码
- 计算 EMV
- 完整代码
介绍
先看看官方介绍:
EMV(简易波动指标)
用法
1.EMV 由下往上穿越0 轴时,视为中期买进信号;
2.EMV 由上往下穿越0 轴时,视为中期卖出信号;
3.EMV 的平均线穿越0 轴,产生假信号的机会较少;
4.当ADX 低于±DI时,本指标失去效用;
5.须长期使用EMV指标才能获得最佳利润。
算法解释:
VOLUME:=MA(VOL,N)/VOL;
MID:=100*(HIGH+LOW-REF(HIGH+LOW,1))/(HIGH+LOW);
EMV:MA(MID*VOLUME*(HIGH-LOW)/MA(HIGH-LOW,N),N);
MAEMV:MA(EMV,M);
优势:
| 优势 | 描述 |
|---|---|
| 清晰的信号 | EMV提供了明确的买入和卖出信号,当指标由下往上穿越0轴时,视为中期买进信号,由上往下穿越0轴时,视为中期卖出信号,使投资者能够更容易地进行决策。 |
| 较少的假信号 | EMV的平均线穿越0轴时,产生假信号的机会较少,这增加了指标的可靠性,帮助投资者避免不必要的交易。 |
| 相对简单 | EMV指标相对简单,易于理解和应用,对于初学者或喜欢简单交易策略的投资者来说,是一种较为友好的指标。 |
劣势:
| 劣势 | 描述 |
|---|---|
| 依赖其他指标 | 当ADX低于±DI时,EMV指标失去效用,因此投资者在使用EMV指标时可能需要结合其他指标进行综合分析,降低失误的风险。 |
| 单一性 | 即使EMV提供了明确的买卖信号,但它仍然是一种单一的指标,可能无法完全覆盖市场的全部信息,投资者仍需谨慎考虑其他因素。 |
| 需长期使用 | 虽然提到了须长期使用EMV指标才能获得最佳利润,但这也意味着需要一定的时间来验证该指标的有效性,对于短期交易者可能不够实用。 |
代码
rolling函数介绍
rolling 函数通常与其他函数(如 mean、sum、std 等)一起使用,以计算滚动统计量,例如滚动均值、滚动总和等。
以下是 rolling 函数的基本语法:
DataFrame.rolling(window, min_periods=None, center=False, win_type=None, on=None, axis=0, closed=None)
window: 用于计算统计量的窗口大小。min_periods: 每个窗口最少需要的非空观测值数量。center: 确定窗口是否居中,默认为False。win_type: 窗口类型,例如None、boxcar、triang等,默认为None。on: 在数据帧中执行滚动操作的列,默认为None,表示对整个数据帧执行操作。axis: 执行滚动操作的轴,默认为0,表示按列执行操作。closed: 确定窗口的哪一端是闭合的,默认为None。
核心代码
计算 EMV
EMV(简易波动指标)是一种用于中期买卖信号的技术指标,通过观察其与0轴的交叉以及平均线的运动,提供清晰的交易信号。
def calculate_EMV(v_df, n, m):"""计算EMV指标参数:v_df: pandas.DataFrame,包含股票数据的DataFramen: int,窗口大小m: int,平滑窗口大小返回:无,结果直接存储在输入的DataFrame中"""# 计算VOLUMEv_df['MA_VOL'] = v_df['VOL'].rolling(window=n).mean()v_df['VOLUME'] = v_df['MA_VOL'] / v_df['VOL']# 计算MIDv_df['MID'] = 100 * (v_df['HIGH'] + v_df['LOW'] - v_df['HIGH'].shift(1) - v_df['LOW'].shift(1)) / (v_df['HIGH'] + v_df['LOW'])# 计算EMVv_df['HL_MA'] = v_df['HIGH'] - v_df['LOW']v_df['MA_HL'] = v_df['HL_MA'].rolling(window=n).mean()v_df['EMV'] = v_df['MID'] * v_df['VOLUME'] * v_df['HL_MA'] / v_df['MA_HL']v_df['EMV'] = v_df['EMV'].rolling(window=n).mean()# 计算MAEMVv_df['MAEMV'] = v_df['EMV'].rolling(window=m).mean()
完整代码
这里完整代码中的data部分,阔以通过下面资源文件下载,或者留下邮箱等发送。:
https://download.csdn.net/download/qq_36051316/88896567
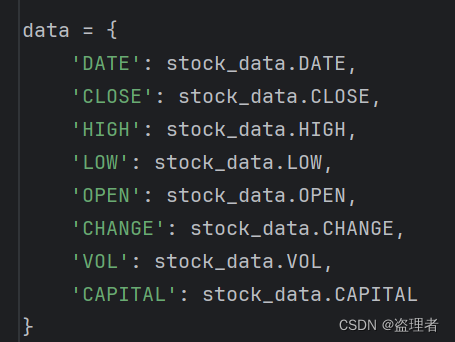
import pandas as pd
import stock_datadata = {'DATE': stock_data.DATE,'CLOSE': stock_data.CLOSE,'HIGH': stock_data.HIGH,'LOW': stock_data.LOW,'OPEN': stock_data.OPEN,'CHANGE': stock_data.CHANGE,'VOL': stock_data.VOL,'CAPITAL': stock_data.CAPITAL
}df = pd.DataFrame(data)def check_signal(v_df, day_index=-1):"""检查信号参数:v_df: pandas.DataFrame,包含EMV指标的DataFrameday_index: int,要检查的日期索引,默认为最后一天返回:str,表示信号的字符串,可能为"买入信号"、"卖出信号"或"无信号""""latest_data = v_df['EMV'].iloc[day_index]latest_data2 = v_df['EMV'].iloc[-1 + day_index]signal = "无信号"if latest_data > 0 >= latest_data2:signal = "买入信号"elif latest_data < 0 <= latest_data2:signal = "卖出信号"return signaldef calculate_EMV(v_df, n, m):"""计算EMV指标参数:v_df: pandas.DataFrame,包含股票数据的DataFramen: int,窗口大小m: int,平滑窗口大小返回:无,结果直接存储在输入的DataFrame中"""# 计算VOLUMEv_df['MA_VOL'] = v_df['VOL'].rolling(window=n).mean()v_df['VOLUME'] = v_df['MA_VOL'] / v_df['VOL']# 计算MIDv_df['MID'] = 100 * (v_df['HIGH'] + v_df['LOW'] - v_df['HIGH'].shift(1) - v_df['LOW'].shift(1)) / (v_df['HIGH'] + v_df['LOW'])# 计算EMVv_df['HL_MA'] = v_df['HIGH'] - v_df['LOW']v_df['MA_HL'] = v_df['HL_MA'].rolling(window=n).mean()v_df['EMV'] = v_df['MID'] * v_df['VOLUME'] * v_df['HL_MA'] / v_df['MA_HL']v_df['EMV'] = v_df['EMV'].rolling(window=n).mean()# 计算MAEMVv_df['MAEMV'] = v_df['EMV'].rolling(window=m).mean()N = 14
M = 9calculate_EMV(df, N, M)# 输出信号
latest_signal = check_signal(df, -1)
print(latest_signal)
这篇关于Python实现EMV工具判断信号:股票技术分析的工具系列(2)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





