本文主要是介绍如何做代币分析:以 SHIB 币为例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:lesley@footprint.network
编译:cici@footprint.network
数据源:SHIB Token Dashboard (仅包括以太坊数据)
在加密货币和数字资产领域,代币分析起着至关重要的作用。代币分析指的是深入研究与代币相关的数据和市场行为的过程。这是一个详细的过程,涉及到对与这些资产相关的价格和流动性进行彻底的检查。
通过代币分析,我们可以获得对市场趋势、风险因素、交易活动和资金流向的投资决策。
SHIB 是 Shiba 生态系统中的主要代币,代表一种去中心化和社区驱动的加密货币。它于 2020 年底出现,并迅速引起全球轰动。
目前,SHIB 作为一种有效的支付方式已被众多场所接受,无论是通过直接交易还是通过第三方服务。治理特性的引入提升了 SHIB 的地位,使其成为全球前 20 大加密货币之一。
如何分析 SHIB?
代币分析至关重要,一般来说,需要考虑哪些关键指标?
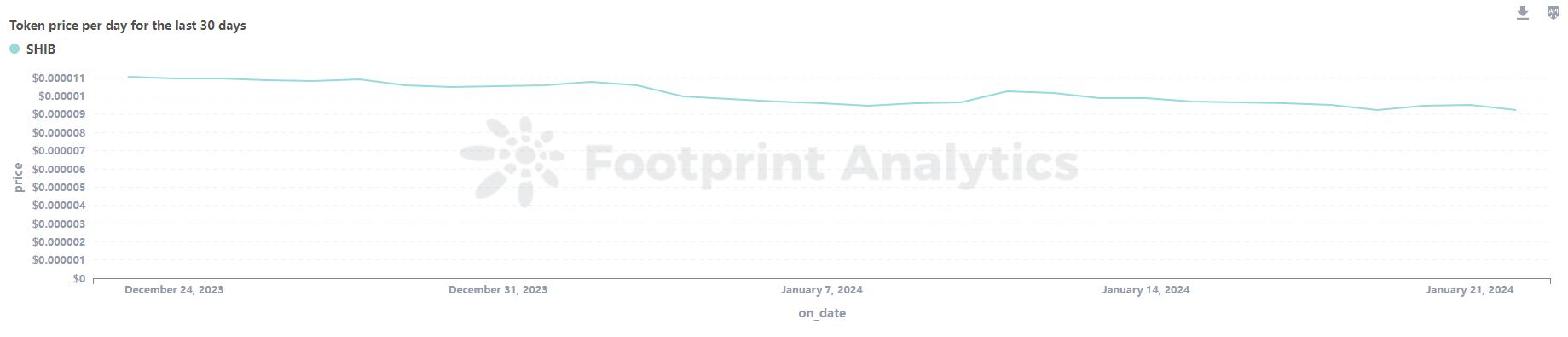
SHIB Price per Day for the Last 30 Days
代币价格
代币价格,以法定货币和加密货币两种形式来衡量,是评估代币市场健康状况和潜力的关键指标。截至 2024 年 1 月 22 日,SHIB 代币价格约为 0.00000927 美元,较上个月下跌约 16.30%。通过诊断分析来分析这种价格趋势可以深入了解代币的表现和潜在的预测趋势。
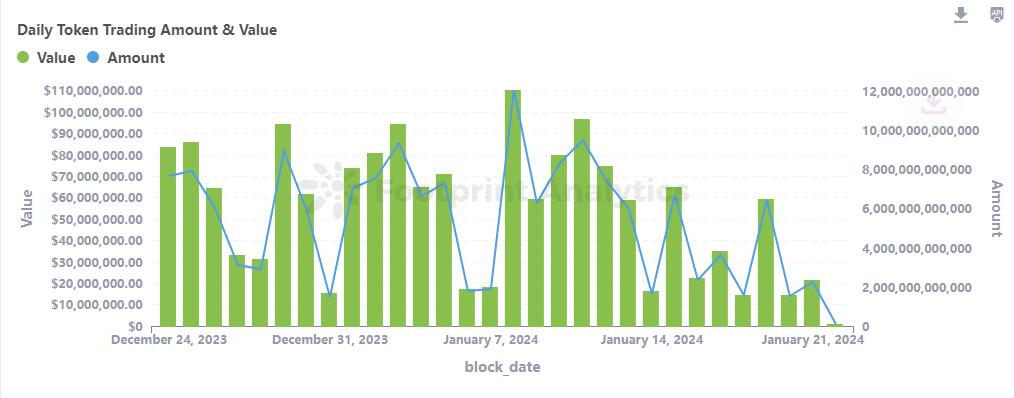
Picture: Daily Token Trading Amount & Value
交易价值
代币交易量是市场活动的关键指标。该代币目前的交易量约为 17,879,696.93 美元。各种数据分析揭示了市场活动的动态性,并为投资者行为和市场情绪提供了宝贵的见解。
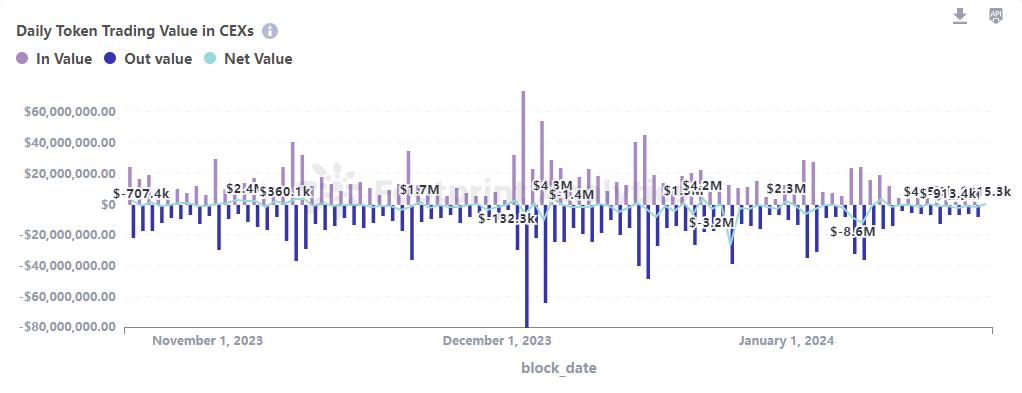
SHIB Daily Token Trading Value in CEXs
CEX 中的净流量
通过分析进出中心化交易所 (CEX) 的代币净流量可以深入了解投资者行为。该分析不仅跟踪进出交易所的代币数量,还研究了这些变动对市场趋势、投资者信心和流动性的更广泛影响。
就近期的 SHIB 而言,主要的流出趋势可能意味着投资者正在将代币转移到私人钱包中,这可能是一种长期持有的策略,也可能是出于对交易所稳定性和安全性的担忧。
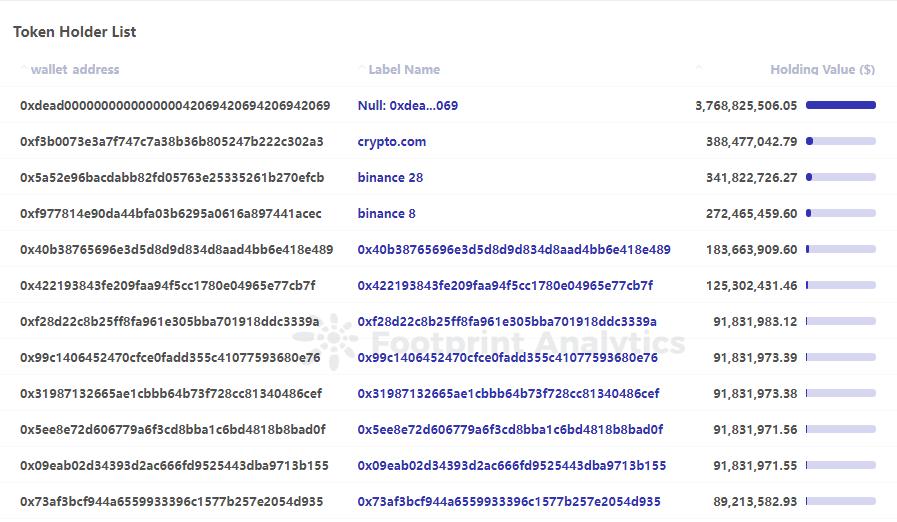
SHIB Token Holder List
代币集中度
分析代币集中度至关重要,因为它揭示了市场完整性和易受操纵的关键见解。通过分析代币在顶级持有者中的分布,我们可以深入了解鲸鱼投资者的影响力以及代币市场的整体健康状况。
请访问我们的网站或安排一次会议,以了解更多解决方案。
Footprint Analytics 是一家区块链数据解决方案提供商。借助尖端的人工智能技术,我们提供 Crypto 领域首家支持无代码数据分析平台以及统一的数据 API,让用户可以快速检索超过 30 条公链生态的 NFT,Game 以及钱包地址资金流追踪数据。
产品亮点
-
面向开发人员的 Data APII
-
用于GameFi项目的 Footprint Growth Analytics (FGA)
-
大数据批量下载功能 Batch download
-
Footprint 提供的所有数据集
-
查看我们的推特(Footprint_Data)了解更多产品更新信息
这篇关于如何做代币分析:以 SHIB 币为例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







