本文主要是介绍【Ai生态开发】Spring AI上架,打造专属业务大模型,AI开发再也不是难事!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好 这里是苏泽 后端是工作 ai是兴趣

对于ai的产生我的立场是拥抱ai的 是希望拿他作为提升能力的工具 那么这一篇带大家来学习如何使用ai打造一个专属的业务大模型
需求 就是说假设现在有一个 商城系统 里面有查询订单的api和获取商品购买方式的api 用户只需要输入 “帮我看看我前几天买过最便宜的衣服” 经过语言处理 ai就能够调用 查询订单的api并在里面自动的添加查询条件以及 排序条件 这是我们的目标 本文就是来讲解实现这样的目标
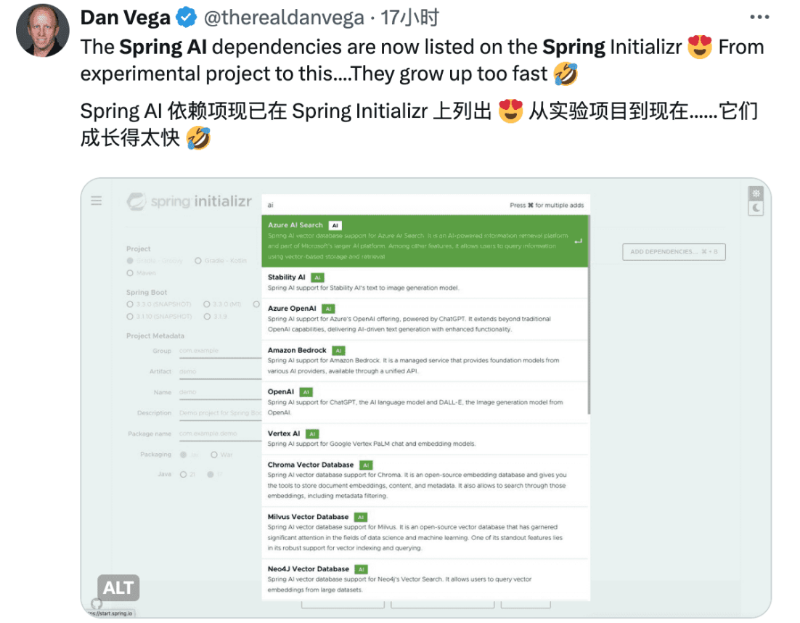
Spring AI介绍
Spring AI 是 AI 工程师的一个应用框架,它提供了一个友好的 API 和开发 AI 应用的抽象,旨在简化 AI 应用的开发工序。
提供对常见模型的接入能力,目前已经上架 https://start.spring.io/,提供大家测试访问。(请注意虽然已经上架 start.spring.io,但目前还是在 Spring 私服,未发布至 Maven 中央仓库)
基本知识讲解:
函数调用
函数调用(Function Calling)是OpenAI在2023年6月13日对外发布的新能力。根据OpenAI官方博客描述,函数调用能力可以让大模型输出一个请求调用函数的消息,其中包含所需调用的函数信息、以及调用函数时所携带的参数信息。这是一种将大模型(LLM)能力与外部工具/API连接起来的新方式。
比如用户输入:
What’s the weather like in Tokyo?
使用function calling,可实现函数执行get_current_weather(location: string),从而获取函数输出,即得到对应地理位置的天气情况。这其中,location这个参数及其取值是借助大模型能力从用户输入中抽取出来的,同时,大模型判断得到调用的函数为get_current_weather。
开发人员可以使用大模型的function calling能力实现:
- 在进行自然语言交流时,通过调用外部工具回答问题(类似于ChatGPT插件);
- 将自然语言转换为调用API调用,或数据库查询语句;
- 从文本中抽取结构化数据
- 其它
实现步骤
1. 添加依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency><!-- 配置 Spring 仓库 --><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories>2. 配置 OpenAI 相关参数
spring:
ai:
openai:
base-url: # 支持 openai-sb、openai-hk 等中转站点,如用官方则不填
api-key: sk-xxxx
3.创建一个Spring Controller处理HTTP请求。
在Spring项目中创建一个Controller类,用于处理提取要素的HTTP请求和生成调用的API和变量集合。
import com.google.gson.Gson;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;import java.util.HashMap;
import java.util.Map;@RestController
public class ElementExtractionController {@Autowiredprivate ElementExtractionService elementExtractionService;@PostMapping("/extract-elements")public ResponseEntity<Map<String, Object>> extractElements(@RequestBody String userInput) {Map<String, Object> result = elementExtractionService.extractElements(userInput);return ResponseEntity.ok(result);}
}3.创建一个ElementExtractionService服务类来提取要素
创建一个服务类,用于封装提取要素的逻辑。在这个服务类中,可以使用自然语言处理技术来分析用户输入并提取需求和变量。可以使用现有的开源NLP库或API,如NLTK、SpaCy、Stanford CoreNLP、Google Cloud Natural Language API等
这里使用NLTK库来进行文本分析和实体识别,以提取用户输入中的需求和变量:
import org.springframework.stereotype.Service;
import edu.stanford.nlp.simple.Document;
import edu.stanford.nlp.simple.Sentence;import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class ElementExtractionService {public Map<String, Object> extractElements(String userInput) {// 使用NLTK库进行文本分析和实体识别Document doc = new Document(userInput);List<Sentence> sentences = doc.sentences();// 提取需求String requirement = extractRequirement(sentences);// 提取变量Map<String, String> variables = extractVariables(sentences);// 构建结果Map<String, Object> result = new HashMap<>();result.put("api", requirement);result.put("variables", variables);return result;}private String extractRequirement(List<Sentence> sentences) {// 在这里根据实际需求,从句子中提取需求// 可以使用关键词提取、模式匹配等方法// 这里示例直接返回第一句话作为需求if (!sentences.isEmpty()) {return sentences.get(0).text();}return "";}private Map<String, String> extractVariables(List<Sentence> sentences) {// 在这里根据实际需求,从句子中提取变量// 可以使用实体识别、关键词提取等方法// 这里示例直接从第一句话中提取名词作为变量Map<String, String> variables = new HashMap<>();if (!sentences.isEmpty()) {Sentence sentence = sentences.get(0);for (String word : sentence.words()) {if (isNoun(word)) {variables.put(word, "true");}}}return variables;}private boolean isNoun(String word) {// 在这里根据实际需求,判断一个词是否为名词// 可以使用词性标注、词典匹配等方法// 这里示例简单判断是否以大写字母开头,作为名词的判断条件return Character.isUpperCase(word.charAt(0));}
}那么下一步 :
4.封装一个API来操作open ai的Assistants API
创建一个Spring Service来操作OpenAI Assistants API。
创建一个服务类,用于封装操作OpenAI Assistants API的逻辑。
import com.google.gson.Gson;
import okhttp3.*;import org.springframework.stereotype.Service;import java.io.IOException;@Service
public class OpenAIAssistantsService {public String callOpenAIAssistantsAPI(String prompt) {OkHttpClient client = new OkHttpClient();MediaType mediaType = MediaType.parse("application/json");JsonObject requestBody = new JsonObject();requestBody.addProperty("prompt", prompt);requestBody.addProperty("max_tokens", 32);requestBody.addProperty("stop", null);RequestBody body = RequestBody.create(mediaType, requestBody.toString());Request request = new Request.Builder().url(OPENAI_API_URL).post(body).addHeader("Authorization", "Bearer " + OPENAI_API_KEY).build();try {Response response = client.newCall(request).execute();if (response.isSuccessful()) {String responseBody = response.body().string();JsonObject jsonObject = new Gson().fromJson(responseBody, JsonObject.class);return jsonObject.getAsJsonObject("choices").get(0).getAsJsonObject().get("text").getAsString();} else {System.out.println("OpenAI Assistants API调用失败: " + response.code() + " - " + response.message());}} catch (IOException e) {System.out.println("OpenAI Assistants API调用异常: " + e.getMessage());}return null;}
}创建一个自定义函数签名。
创建一个函数,它将调用其他项目中的API,并返回结果。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class CustomFunctionService {@Autowiredprivate OtherAPIService otherAPIService;public String customFunction(String apiId, String inputParameters) {// 根据API的ID筛选需要调用的APIString apiEndpoint = getApiEndpoint(apiId);// 调用其他项目中的API,并进行处理String result = otherAPIService.callOtherAPI(apiEndpoint, inputParameters);// 对结果进行处理,并返回return "处理后的结果:" + result;}private String getApiEndpoint(String apiId) {//这里还会有很多具体业务的api就不一一列举了// 根据API的ID获取相应的API的URL或其他信息// 这里可以根据实际情况进行实现if (apiId.equals("api1")) {return "https://api.example.com/api1";} else if (apiId.equals("api2")) {return "https://api.example.com/api2";} else {throw new IllegalArgumentException("无效的API ID: " + apiId);}}
}创建一个Spring Controller来调用自定义函数。
创建一个Controller类,它将调用自定义函数,并返回结果。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;import java.util.HashMap;
import java.util.Map;@RestController
public class CustomFunctionController {@Autowiredprivate CustomFunctionService customFunctionService;@PostMapping("/call-custom-function")public ResponseEntity<String> callCustomFunction(@RequestBody String userInput) {String result = customFunctionService.customFunction(userInput);return ResponseEntity.ok(result);}
}在上面提取要素的服务(ElementExtractionService)的基础上,我们可以再封装一个Assistants服务,它将接受用户的请求并调用提取要素的服务。然后,Assistants服务将提取的要素和变量(uid)作为输入传递给封装了OpenAI的服务(OpenAIAssistantsService),并根据要素选择适当的API进行调用,并返回对应的结果。
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;import java.util.Map;@Service
public class AssistantsService {@Autowiredprivate ElementExtractionService elementExtractionService;@Autowiredprivate OpenAIAssistantsService openAIAssistantsService;public String processUserRequest(String userInput) {// 提取要素Map<String, Object> elements = elementExtractionService.extractElements(userInput);// 获取要素和变量String requirement = (String) elements.get("api");Map<String, String> variables = (Map<String, String>) elements.get("variables");String uid = (String) elements.get("uid");// 调用OpenAI Assistants服务String result = openAIAssistantsService.callOpenAIAssistantsAPI(requirement, variables, uid);return result;}
}AssistantsService类接受用户的请求,并调用ElementExtractionService来提取要素。然后,它获取要素、变量和uid,并将它们作为参数传递给OpenAIAssistantsService的callOpenAIAssistantsAPI方法。该方法根据要素选择适当的API进行调用,并返回结果。
具体的业务实现“提取要素”的逻辑部分
请注意,为了实现这个过程,还需要修改ElementExtractionService中提取要素的逻辑,以确保这个服务能符合具体业务的逻辑 例如我提到的 “帮我看看我买过最便宜的衣服”
import org.springframework.stereotype.Service;
import edu.stanford.nlp.simple.Document;
import edu.stanford.nlp.simple.Sentence;import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class ElementExtractionService {public Map<String, Object> extractElements(String userInput) {// 使用NLTK库进行文本分析和实体识别Document doc = new Document(userInput);List<Sentence> sentences = doc.sentences();// 提取需求String requirement = extractRequirement(sentences);// 提取变量Map<String, String> variables = extractVariables(sentences);// 构建结果Map<String, Object> result = new HashMap<>();result.put("api", requirement);result.put("variables", variables);return result;}private String extractRequirement(List<Sentence> sentences) {// 在这里根据实际需求,从句子中提取需求// 可以使用关键词提取、模式匹配等方法// 这里示例直接返回第一句话作为需求if (!sentences.isEmpty()) {return sentences.get(0).text();}return "";}private Map<String, String> extractVariables(List<Sentence> sentences) {// 在这里根据实际需求,从句子中提取变量// 可以使用实体识别、关键词提取等方法// 这里示例从第一句话中提取名词作为变量,并根据特定模式进行匹配Map<String, String> variables = new HashMap<>();if (!sentences.isEmpty()) {Sentence sentence = sentences.get(0);List<String> words = sentence.words();for (int i = 0; i < words.size() - 1; i++) {String currentWord = words.get(i);String nextWord = words.get(i + 1);if (isNoun(currentWord) && nextWord.equals("的")) {variables.put(currentWord, "true");}}}return variables;}private boolean isNoun(String word) {// 在这里根据实际需求,判断一个词是否为名词// 可以使用词性标注、词典匹配等方法// 这里示例简单判断是否以大写字母开头,作为名词的判断条件return Character.isUpperCase(word.charAt(0));}
}我将extractVariables方法进行了修改。现在它从第一句话中提取名词作为变量,并且根据特定模式进行匹配。特定模式是判断当前词是否为名词,以及下一个词是否为"的"。如果匹配成功,则将当前词作为变量存储。
这样我们就基本实现了一开始的那个目标:
假设现在有一个 商城系统 里面有查询订单的api和获取商品购买方式的api 用户只需要输入 “帮我看看我前几天买过最便宜的衣服” 经过语言处理 ai就能够调用 查询订单的api并在里面自动的添加查询条件以及 排序条件 这是我们的目标 本文就是来讲解实现这样的目标
更长远的目标:
希望能够开发出一款中间件(作为一个服务被注册到项目当中) 能够作为open ai 和具体项目的桥梁 即在开发配置当中我输入我的已有项目的服务的签名 那这个助手能够根据用户的自然语言输入 自动的去调用执行 项目中已有的各种服务 来做各种各样的复杂的数据库查询 等操作
本文所受启发 参考文献:
- Function calling and other API updates: https://openai.com/blog/function-calling-and-other-api-updates
- OpenAI assistants in LangChain: https://python.langchain.com/docs/modules/agents/agent_types/openai_assistants
- Multi-Input Tools in LangChain: https://python.langchain.com/docs/modules/agents/tools/multi_input_tool
- examples/Assistants_API_overview_python.ipynb: https://github.com/openai/opena...
- The Spring Boot Actuator is the one dependency you should include in every project (danvega.dev)
- Assistants API won't allow external web request - API - OpenAI Developer Forum
本文只是简单提供一个可行的思路做参考 真正做出可拓展性的ai开发插件道路还很长 先在这立个小flag吧 希望今年能够完成这个小目标 如果有一起开发这个项目的伙伴可以跟我来讨论哦
这篇关于【Ai生态开发】Spring AI上架,打造专属业务大模型,AI开发再也不是难事!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





