本文主要是介绍Zynq—AD9238数据采集DDR3缓存千兆以太网发送实验(前导),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ACM9238 高速双通道ADC模块自助服务手册AD9238
Zynq—AD9238数据采集DDR3缓存千兆以太网发送实验(一)-CSDN博客
一、AD9238
模块在各方面参数性能上与AD9226保持一致。但是在设计上优化了信号调理电路,将单端信号先转成差分信号,再送入ADC转换,已获得更小的采样误差。
功能参数
1、±5V电压输入范围
2、每通道65Msps最高采样速率
3、每通道12位输出
二、DDR3(大容量存储器件)
DDR=Double Data Rate双倍速率,DDR SDRAM=双倍速率同步动态随机存储器,人们习惯称为DDR,其中,SDRAM 是Synchronous Dynamic Random Access Memory的缩写,即同步动态随机存取存储器。而DDR SDRAM是Double Data Rate SDRAM的缩写,是双倍速率同步动态随机存储器。(摘录:ddr(双倍数据速率)_百度百科 (baidu.com))
1.相关知识
PL:通用可编程逻辑FPGA。
PS:两个 Cortex-A9 核、 IO 外设、各类硬核控制器等资源在内的 SOC 处理系统。
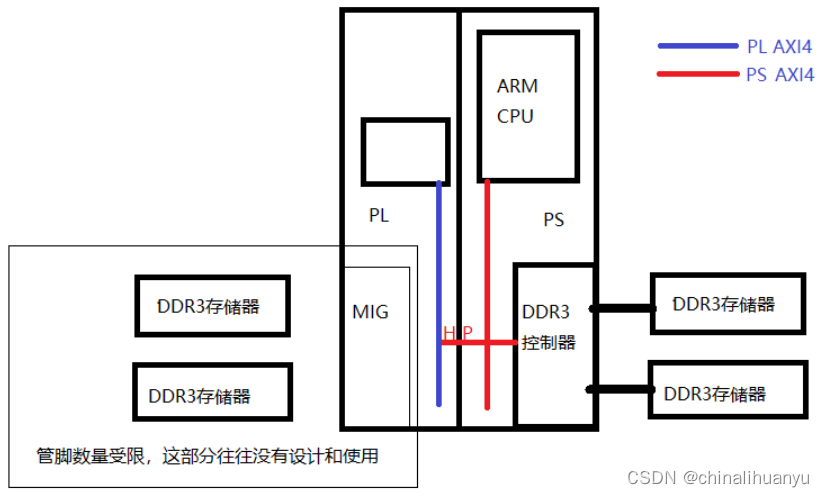
PS部分的DDR3主要用作ARM CPU的内存系统,ARM CPU的程序可以在该DDR3中运行,PS部分的DDR3存储器使用,不需要,也不能调用MIG IP来控制,只需要在设计中添加ZYNQ7 Processing System 组件,并配置好DDR相关的参数,即可使用。ACZ7015开发板的DDR型号为MT41K256M16 RE-125。
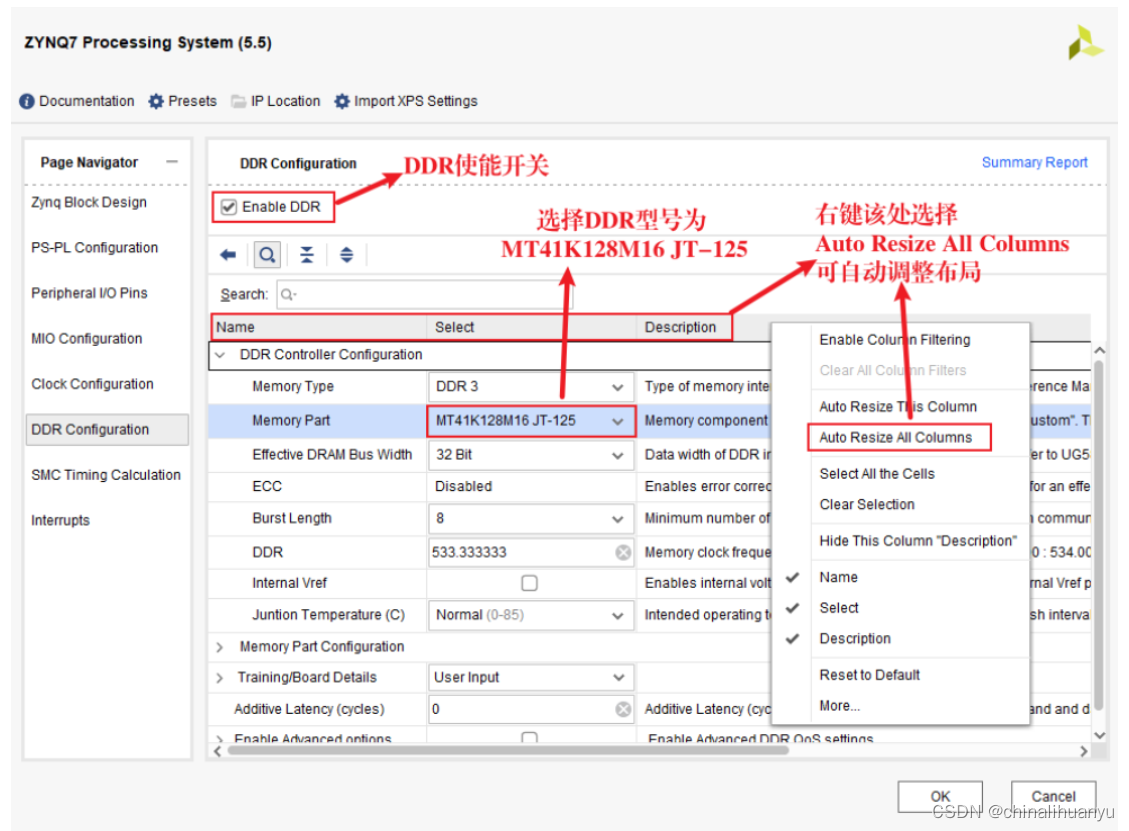
PL部分如果要使用DDR3存储器:
第一种:首先在PL部分要设计DDR3部分电路,并且需要通过在IP Catlog中调用MIG IP来创建DDR3控制器。
第二种:PL通过AXI4(4个高性能数据交互端口,High-Performance Ports)接口使用PS的DDR3存储器空间。
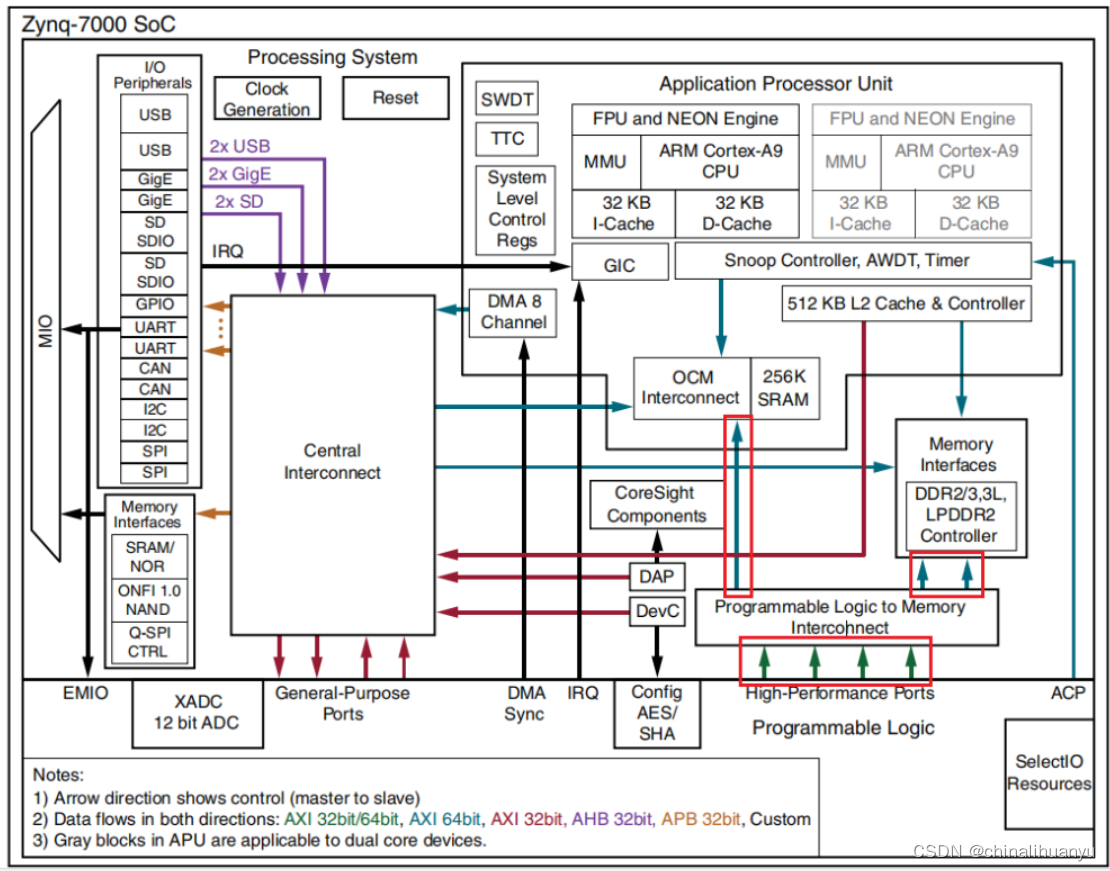
2.架构优势
PL通过HP端口写入到PS侧DDR3中的数据,不仅PL可以再读回来,同时PS侧的ARM CPU也可以读写这些数据。相同的道理,PS侧在某些区域写入的数据,PL侧也可以从该区域读出来使用。
3.直接使用DDR控制器可能会遇到的实际问题
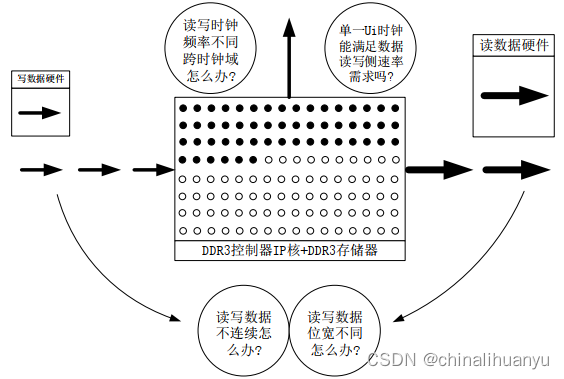
如何确保读写DDR时数据的有效性以及读写传输的高效性?
3.1读写时钟频率不同跨时钟域怎么办?单一Ui时钟能满足数据读写侧速率需求吗?
这里的Ui时钟指的是DDR控制器输出的供用户侧使用的ui_clk时钟。
DDR控制器的时钟频率恒定,但是大部分硬件(读写)有自身的固定工作频率、数据读写频率,并且有可能与DDR时钟频率不一致。有可能导致DDR控制器无法满足读写硬件的速率需求,进而数据交互存在跨时钟域,还会导致DDR读写错误。
3.2读写数据不连续怎么办?
在速率满足的情况下,还可能存在外设发送接收数据并不连续的问题。
3.3读写数据位宽不同怎么办?
DDR典型数据位宽128位,但外设一般为8位或16位。
以上问题通过在读写段各添加一个FIFO解决,进而引出AXI转化模块。
这篇关于Zynq—AD9238数据采集DDR3缓存千兆以太网发送实验(前导)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




