本文主要是介绍AI论文速读 | 立场观点:时间序列分析,大模型能告诉我们什么?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目:Position Paper: What Can Large Language Models Tell Us about Time Series Analysis
作者:Ming Jin ; Yifan Zhang ; Wei Chen ; Kexin Zhang ; Yuxuan Liang ; Bin Yang ; Jindong Wang ; Shirui Pan ; Qingsong Wen
机构:莫纳什大学(Monash),中国科学院,香港科技大学(广州),浙江大学,华东师范大学,微软亚洲研究院(MSRA),格里菲斯大学(Griffith),松鼠AI
网址:https://arxiv.org/abs/2402.02713

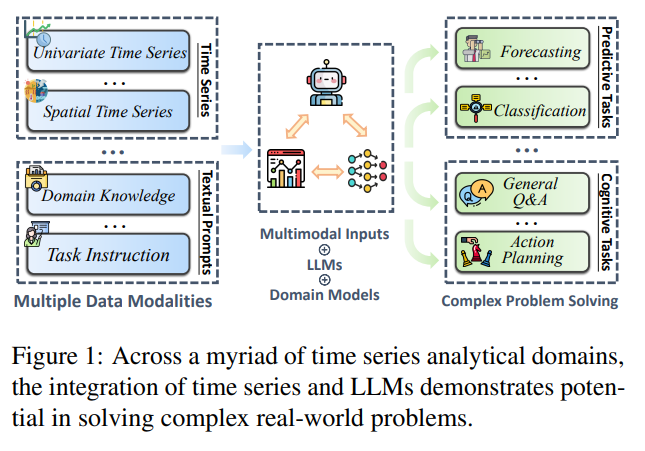
摘要
时间序列分析对于理解各种现实世界系统和应用程序固有的复杂性至关重要。 尽管大型语言模型(LLM)最近取得了重大进展,但配备时间序列分析功能的通用人工智能(AGI)的发展仍处于起步阶段。 大多数现有时间序列模型严重依赖领域知识和广泛的模型调整,主要关注预测任务。 本文认为当前的LLM有可能彻底改变时间序列分析,从而促进高效的决策并朝着更通用的时间序列分析智能形式迈进。 这种进步可以释放广泛的可能性,包括模态转换和时间序列问答。 本文鼓励研究人员和从业者认识到LLM在推进时间序列分析方面的潜力,并强调对这些相关努力的信任的必要性。 此外,还详细介绍了时间序列分析与现有LLM技术的无缝集成,并概述了未来研究的有希望的途径。

Q: 这篇论文试图解决什么问题?
A: 这篇论文探讨了如何利用大型语言模型(LLMs)来革新时间序列分析领域。时间序列分析对于理解现实世界系统中的复杂性至关重要,但目前的时间序列模型主要依赖于领域知识和大量的模型调整,且主要集中在预测任务上。论文的主要目标是:
- 展示LLMs在时间序列分析中的潜力:作者认为,尽管LLMs在处理文本序列方面取得了显著进展,但它们在时间序列分析中的应用仍处于起步阶段。论文旨在探讨LLMs如何通过提供更丰富的外部知识和分析能力,以及增强的内部知识和推理能力,来改进时间序列数据的分析。
- 促进决策制定和智能分析:通过将时间序列分析与LLMs技术无缝集成,论文旨在推动更高效的决策制定和向更通用的时间序列分析智能形式的转变。
- 探索LLMs在时间序列分析中的应用:论文详细讨论了LLMs如何作为数据和模型增强器、优越的预测器以及下一代智能体,以及它们在时间序列分析中的潜在应用,如模态切换和时间序列问答。
- 鼓励研究和实践:作者鼓励研究人员和实践者认识到LLMs在推进时间序列分析方面的潜力,并强调在这些相关努力中建立信任的重要性。
- 提出未来研究方向:论文还识别并概述了当前研究尚未涉及的领域,为这一不断发展的跨学科领域提出了有前景的未来研究方向。
总的来说,这篇论文试图解决的问题是如何将LLMs的先进能力应用于时间序列分析,以克服现有方法的局限性,并推动该领域向更智能、更通用的分析方法发展。
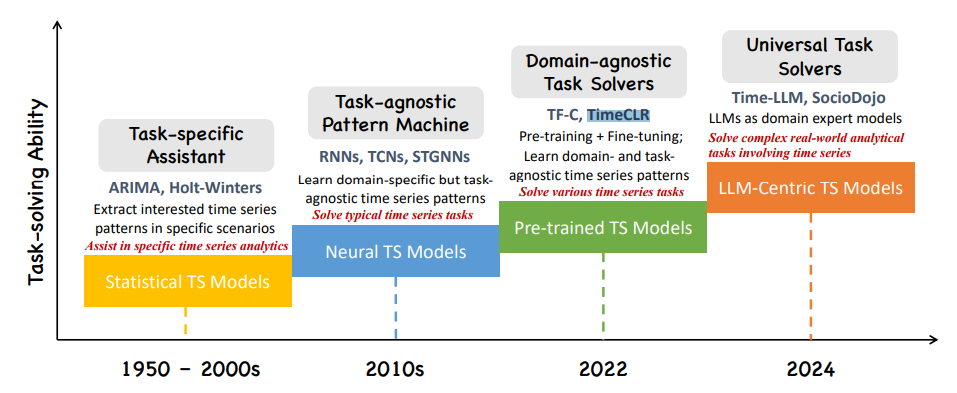
Q: 有哪些相关研究?
A: 论文中提到了多项与大型语言模型(LLMs)在时间序列分析中的应用相关的研究。以下是一些关键的研究点和相关研究:
- LLM-assisted Enhancer:
- 数据增强:研究如SignalGPT、LLM-MPE、SST、Insight Miner、AmicroN等,通过LLMs提供文本描述和总结,增强时间序列数据的可解释性。
- 模型增强:例如IMU2CLIP、STLLM、TrafficGPT等,通过将LLMs的知识转移到时间序列模型中,提高模型在复杂任务中的性能。
- LLM-centered Predictor:
- Tuning-Based Predictor:研究如Time-LLM、FPT、UniTime、TEMPO、LLM4TS等,通过调整LLM的参数来适应时间序列任务。
- Non-Tuning-Based Predictor:例如PromptCast、LLMTIME等,通过预处理时间序列数据以适应LLM的输入格式,而不直接调整LLM的参数。
- Others:如Lag-Llama、PreDcT、CloudOps等,这些研究构建了基础模型,旨在模拟LLMs的扩展规律。
- LLM-empowered Agent:
- External Knowledge Integration:研究如GPT3-VQA、PromptGAT、Open-TI等,通过在LLMs中嵌入领域特定的提示(prompts),增强模型对特定领域的理解。
- Adapt Target Modality:例如Toolformer、LLaVA、PIXIU等,这些研究通过调整LLMs以适应特定的目标模态内容,如将LLMs与视觉模型结合,或为金融应用创建多任务指令数据集。
- 其他相关研究:
- 时间序列数据增强:如TimeCLR,通过在大规模时间序列数据上进行预训练,然后针对特定任务进行微调。
- 时间序列问答:如GPT-4和Llama等LLMs在时间序列问答任务中的应用。
这些研究展示了LLMs在时间序列分析中的多样化应用,包括数据增强、模型改进、预测任务以及作为智能智能体的潜力。通过这些研究,我们可以更好地理解LLMs如何被集成到现有的时间序列分析框架中,并探索其在未来可能的发展方向。
Q: 论文如何解决这个问题?
A: 论文提出了几种方法来解决如何利用大型语言模型(LLMs)来改进时间序列分析的问题,具体包括以下几个方面:
-
LLM-assisted Enhancer:
- 数据增强:通过LLMs提供文本描述和总结,帮助理解时间序列数据中的模式和异常。例如,使用LLMs生成关于时间序列数据的自然语言描述,以辅助人类分析师理解数据。
- 模型增强:将LLMs的知识转移到时间序列模型中,通过双塔模型等方法,利用LLMs的内部知识来提升时间序列模型的性能。

LLM 辅助增强器代表了增强时间序列数据和模型的有前途的途径,值得进一步探索。 未来的方向应侧重于开发高效、可靠且通用的即插即用解决方案,有效解决数据稀疏和噪声等实际挑战,同时还要考虑大规模数据集应用的时间和成本效率。
-
LLM-centered Predictor:
- Tuning-Based Predictor:通过调整LLMs的参数,使其适应时间序列数据,例如,通过添加任务层(Task Layer)来执行特定的时间序列分析任务。
- Non-Tuning-Based Predictor:通过预处理时间序列数据,使其适应LLMs的输入格式,然后利用LLMs进行预测,而不直接调整LLMs的参数。
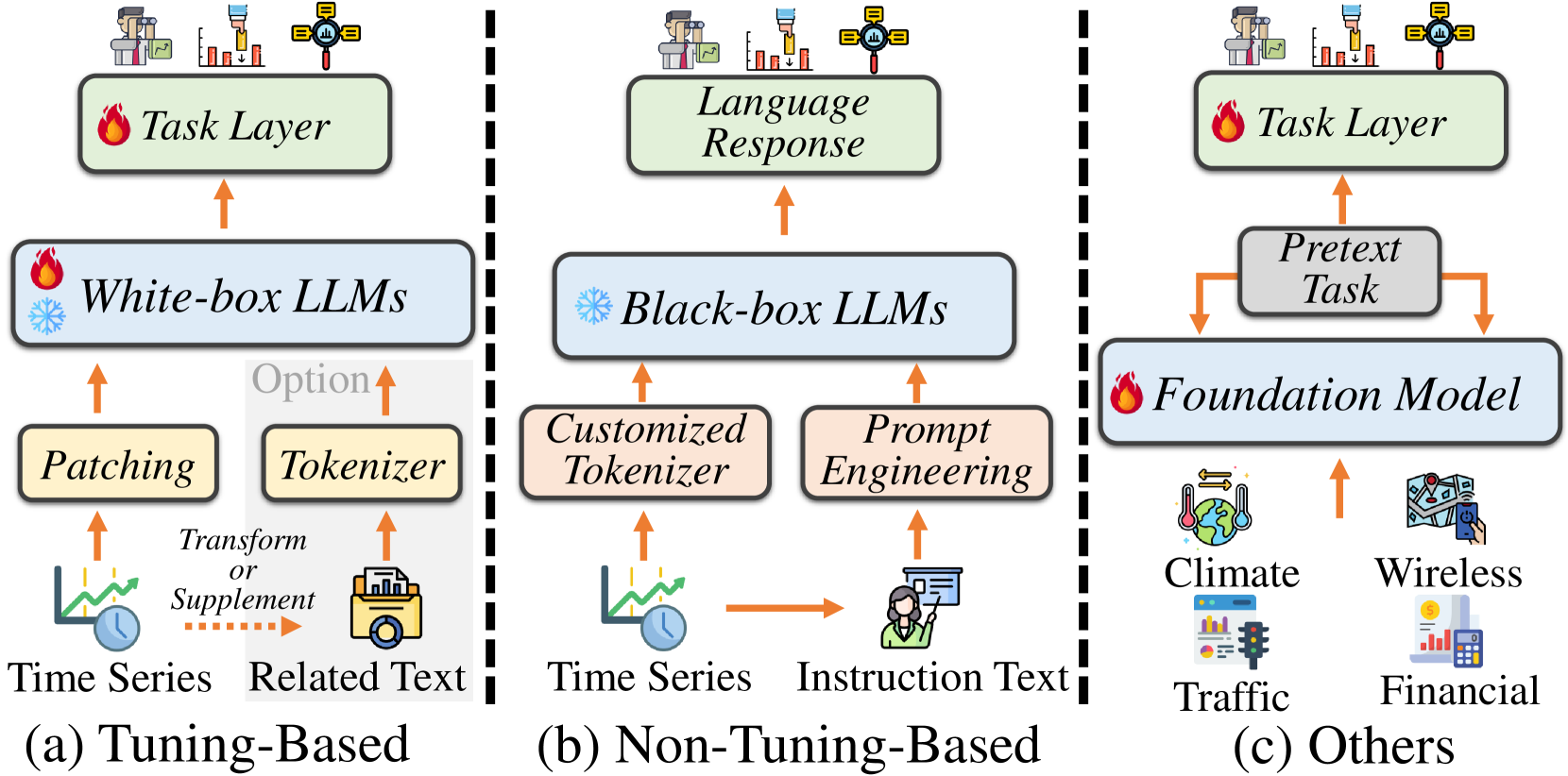

以 LLM 为中心的预测器虽然在时间序列分析中蓬勃发展,但仍处于起步阶段,值得更深入的考虑。 未来的进步不仅应该建立在时间序列基础模型的基础上,还应该增强时间序列基础模型。 通过利用情境学习和思想链推理等独特的法学硕士能力,这些进步可以克服当前的局限性,如灾难性遗忘,并提高预测的稳定性和可靠性。
-
LLM-empowered Agent:
- 利用外部知识:通过在LLMs中嵌入领域特定的提示(prompts),增强模型对特定领域的理解,使其能够处理更复杂的时间序列问题。
- 适应目标模态:通过将LLMs与特定模态的内容对齐,例如,将LLMs与视觉模型结合,或者为金融应用创建多任务指令数据集,以提高模型在特定任务上的性能。
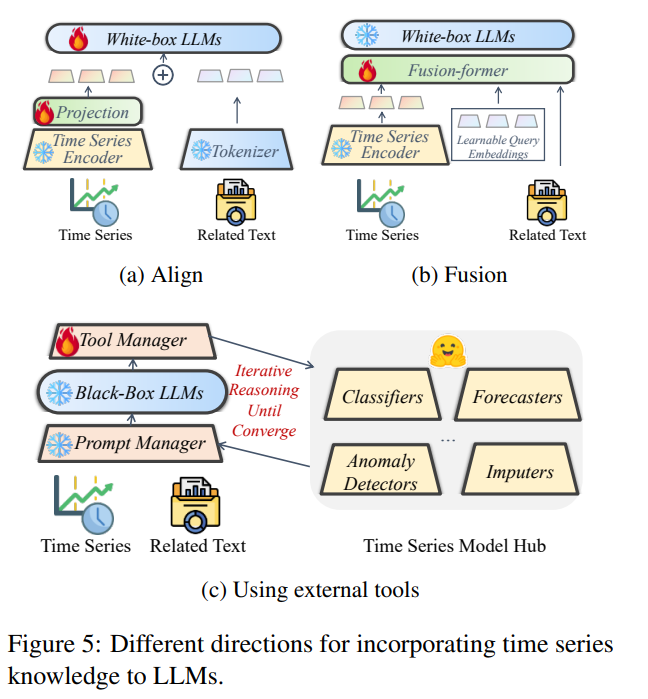

目前的LLM在人机交互和时间序列数据分析方面表现出色,但他们遇到了诸如偶尔不准确和容易出现幻觉等问题。 为了提高他们决策的可靠性,制定有效指导方针并纳入特定领域的知识至关重要。 克服幻觉等挑战、符合人类偏好以及适应不断变化的时间序列数据是最大化其能力和最小化风险的关键。 未来的愿景是开发强大且适应性强的LLM赋能智能体,能够熟练处理复杂的时间序列分析。
-
未来研究方向:
- 时间序列特征与语言模型表示的对齐:研究如何将时间序列特征映射到LLMs的表示中,以增强模型对时间模式的理解。
- 文本嵌入与时间序列特征的融合:探索如何将文本嵌入与时间序列特征结合起来,创建一种新的表示形式,既利用LLMs在自然语言处理方面的优势,又能够处理时间序列数据的复杂性。
- 教授LLMs使用外部预训练时间序列模型:指导LLMs识别并使用外部的时间序列模型,以解决用户查询,使LLMs成为高级智能体,负责协调这些模型的使用。
论文通过这些方法,旨在推动LLMs在时间序列分析中的应用,从而实现更高效、更智能的数据分析和决策支持。同时,论文也强调了在这一过程中需要解决的挑战,如模型的可解释性、隐私保护、环境和计算成本等。
Q: 论文做了哪些实验?
A: 论文中进行了一系列的实验来评估大型语言模型(LLMs)在时间序列分析中的应用潜力。以下是一些关键的实验内容:
- 时间序列分类实验:
- 使用了HAR(Human Activity Recognition)数据库,该数据库包含了30名参与者在进行日常活动(如站立、坐下、躺下、行走)时携带的智能手机上的惯性传感器数据。
- 实验目的是将活动分类为四个类别之一,使用GPT-3.5作为LLM进行零样本(zero-shot)分类任务。
- 实验结果显示,LLMs在某些情况下(如站立)能够准确分类,但在其他情况下(如躺下)可能存在误分类。
- 时间序列数据增强实验:
- 提供了来自Electric Transformer Temperature (ETT)数据集的实例,该数据集包含了油温和电力负载特征。
- 实验要求LLMs基于给定的输入模式生成新的实例,即进行数据增强。
- LLMs能够生成与给定数据结构和特征相似的新实例,但这些实例是基于假设的模式生成的,而不是基于实际的时间序列模型。
- 时间序列异常检测实验:
- 在ETT数据集上,LLMs被要求识别潜在的异常点。
- LLMs提供了基于简单视觉检查的潜在异常点,但没有使用任何统计方法或模型来支持这些猜测。
这些实验展示了LLMs在时间序列分析中的潜力,尤其是在零样本学习、数据增强和异常检测等任务上。然而,实验也揭示了LLMs在理解复杂时间序列模式和生成准确解释方面的局限性。例如,LLMs在某些情况下可能会产生幻觉(hallucination),生成看似合理但实际错误的输出。这些发现强调了在将LLMs应用于时间序列分析时需要进一步研究和改进的方向。
Q: 有什么可以进一步探索的点?
A: 论文提出了几个可以进一步探索的研究方向,以推动大型语言模型(LLMs)在时间序列分析中的应用。以下是一些潜在的研究方向:
- 增强LLMs的时间序列理解能力:
- 研究如何将时间序列特征与LLMs的语言模型表示对齐,以增强模型对时间模式的理解。
- 探索融合文本嵌入和时间序列特征的方法,创建一种新的表示形式,既利用LLMs在自然语言处理方面的优势,又能够处理时间序列数据的复杂性。
- 教授LLMs使用外部预训练时间序列模型:
- 开发方法,使LLMs能够识别并利用外部的时间序列模型,以解决用户查询,使LLMs成为高级智能体,负责协调这些模型的使用。
- 提高LLMs的可解释性和可靠性:
- 研究如何减少LLMs在时间序列分析中的幻觉(hallucination)问题,提高模型的预测稳定性和可靠性。
- 开发有效的指导方针,以创建对时间序列分析有影响力的提示(prompts)。
- 研究LLMs与人类偏好的对齐:
- 确保生成的内容既有帮助又无害,特别是在处理敏感数据时。
- 适应不断变化的时间序列数据:
- 使LLMs能够持续获取新知识,或采用终身学习模式,以适应时间序列数据中的模式漂移(concept drift)。
- 优化环境和计算成本:
- 探索更高效的对齐和推理策略,以减少LLMs在时间序列分析中的环境和计算成本。
- 隐私和安全:
- 在LLM-centric时间序列分析中,研究如何实施隐私保护措施,防止数据泄露和滥用。
- 跨学科应用:
- 探索LLMs在不同领域(如金融、医疗、交通等)的时间序列分析应用,以及如何将这些应用与特定领域的知识结合。
- 模型透明度和可解释性:
- 研究如何提高LLMs的透明度,以便更好地理解其内部机制和决策过程。
这些研究方向不仅有助于提升LLMs在时间序列分析中的性能,还有助于解决当前应用中存在的挑战,如模型的可解释性、隐私保护和环境影响等问题。通过这些研究,可以推动LLMs在时间序列分析领域的实际应用和理论发展。
Q: 总结一下论文的主要内容
A: 这篇论文探讨了大型语言模型(LLMs)在时间序列分析领域的应用潜力和未来研究方向。以下是论文的主要内容总结:
- 背景与挑战:
- 时间序列分析对于理解现实世界系统中的动态变化至关重要,但现有的时间序列模型主要依赖于领域知识和模型调整,且多聚焦于预测任务。
- LLMs在处理文本序列方面取得了显著进展,但在时间序列分析中的应用尚处于起步阶段。
- LLMs在时间序列分析中的潜力:
- LLMs有潜力通过提供丰富的外部知识和增强的内部知识及推理能力,来改进时间序列数据的分析。
- LLMs可以作为数据和模型增强器、预测器以及下一代智能智能体,推动时间序列分析向更通用的智能系统发展。
- LLM-assisted Enhancer:
- 数据增强:LLMs可以提供文本描述和总结,帮助理解时间序列数据中的模式和异常。
- 模型增强:通过将LLMs的知识转移到时间序列模型中,提高模型在复杂任务中的性能。
- LLM-centered Predictor:
- Tuning-Based Predictor:通过调整LLMs的参数来适应时间序列任务。
- Non-Tuning-Based Predictor:通过预处理时间序列数据以适应LLMs的输入格式,而不直接调整LLMs的参数。
- LLM-empowered Agent:
- 利用LLMs作为时间序列分析的智能智能体,通过外部知识集成和目标模态适应,提高分析的准确性和可靠性。
- 实验与实证洞察:
- 通过HAR数据库的时间序列分类实验,展示了LLMs在零样本学习中的潜力和局限性。
- 在ETT数据集上的时间序列数据增强和异常检测实验,进一步验证了LLMs的应用潜力。
- 未来研究方向:
- 提出了一系列研究方向,包括提高LLMs的时间序列理解能力、教授LLMs使用外部模型、提高可解释性和可靠性、隐私和安全保护等。
- 结论:
- LLMs在时间序列分析中具有巨大潜力,但目前仍处于发展初期。未来的研究应集中在克服现有挑战,如模型的可解释性、隐私保护、环境影响等,以实现LLMs在时间序列分析中的广泛应用。
列研究方向,包括提高LLMs的时间序列理解能力、教授LLMs使用外部模型、提高可解释性和可靠性、隐私和安全保护等。
8. 结论:
- LLMs在时间序列分析中具有巨大潜力,但目前仍处于发展初期。未来的研究应集中在克服现有挑战,如模型的可解释性、隐私保护、环境影响等,以实现LLMs在时间序列分析中的广泛应用。
论文强调了LLMs在时间序列分析中的潜在应用,并呼吁研究人员和实践者关注这一领域,同时提出了一系列具体的研究方向,以推动LLMs在时间序列分析中的进一步发展。
这篇关于AI论文速读 | 立场观点:时间序列分析,大模型能告诉我们什么?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







